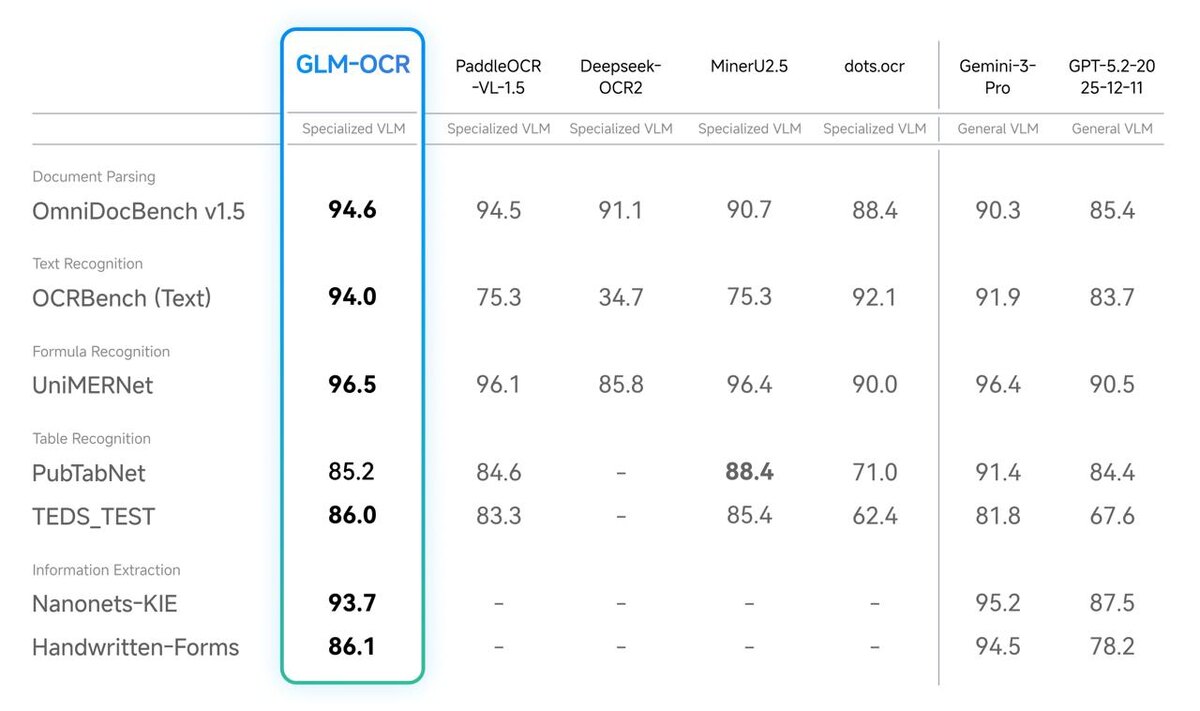
Модель показывает SOTA-результаты в задачах понимания документов, оставаясь компактной и быстрой. Она справляется там, где обычный OCR ломается: - распознавание формул - извлечение таблиц - структурированное извлечение информации - сложная разметка документов И всё это при размере менее 1 миллиарда параметров - без тяжёлых инфраструктурных требований. Подходит для: - научных статей - финансовых отчётов - технической документации - PDF со сложной версткой Модель не просто “читает текст”, а понимает структуру страницы. Веса: http://huggingface.co/zai-org/GLM-OCR Демо: http://ocr.z.ai API: http://docs.z.ai/guides/vlm/glm-ocr
⚡️ GLM-OCR 0.9B - мощный OCR для сложных документов
Модель показывает SOTA-результаты в задачах понимания документов, оставаясь компактной и быстрой.
Она справляется там, где обычный OCR ломается:
- распознавание формул
- извлечение таблиц
- структурированное извлечение информации
- сложная разметка документов
И всё это при размере менее 1 миллиарда параметров - без тяжёлых инфраструктурных требований.
Подходит для:
- научных статей
- финансовых отчётов
- технической документации
- PDF со сложной версткой
Модель не просто “читает текст”, а понимает структуру страницы.
Веса: http://huggingface.co/zai-org/GLM-OCR
Демо: http://ocr.z.ai
API: http://docs.z.ai/guides/vlm/glm-ocr