
Статья посвящена результатам комплексного анализа производительности системы после внесения изменений в тестовые сценарии и настройки окружения в версии 5.1. Основное внимание уделено выявлению узких мест под нагрузкой, в особенности — критическим проблемам ввода-вывода (I/O), которые стали определяющим фактором ограничения производительности СУБД.
Глоссарий терминов | Postgres DBA | Дзен
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Важное изменение в версии 5.1⚠️
Изменены тестовые сценарии scenario-2 и scenario-3.
scenario-2 (INSERT)
scenario-3 (UPDATE)
scenario-1 (SELECT) - без изменений
Веса тестовых сценариев и параметры нагрузочного тестирования
# Веса сценариев по умолчанию
scenario1 = 0.7
scenario2 = 0.2
scenario3 = 0.1
Измененные параметры операционной системы для оптимизации
1️⃣Общие параметры производительности
vm.dirty_ratio = 10
vm.dirty_background_ratio = 5
2️⃣Параметры IO-планировщика
[mq-deadline] kyber bfq none
3️⃣Настройки кэширования и буферизации
vm.vfs_cache_pressure = 50
4️⃣Оптимизация параметров файловой системы
/dev/mapper/vg_data-LG_data on /data type ext4 (rw,noatime,nodiratime)
5️⃣Изменение размера буферов для операций с блочными устройствами
read_ahead_kb = 256
Тестовая среда, инструменты и конфигурация СУБД:
- СУБД: PostgreSQL 17
- Тестовая база данных: pgbench (10GB, простая структура)
- CPU = 8
- RAM = 8GB
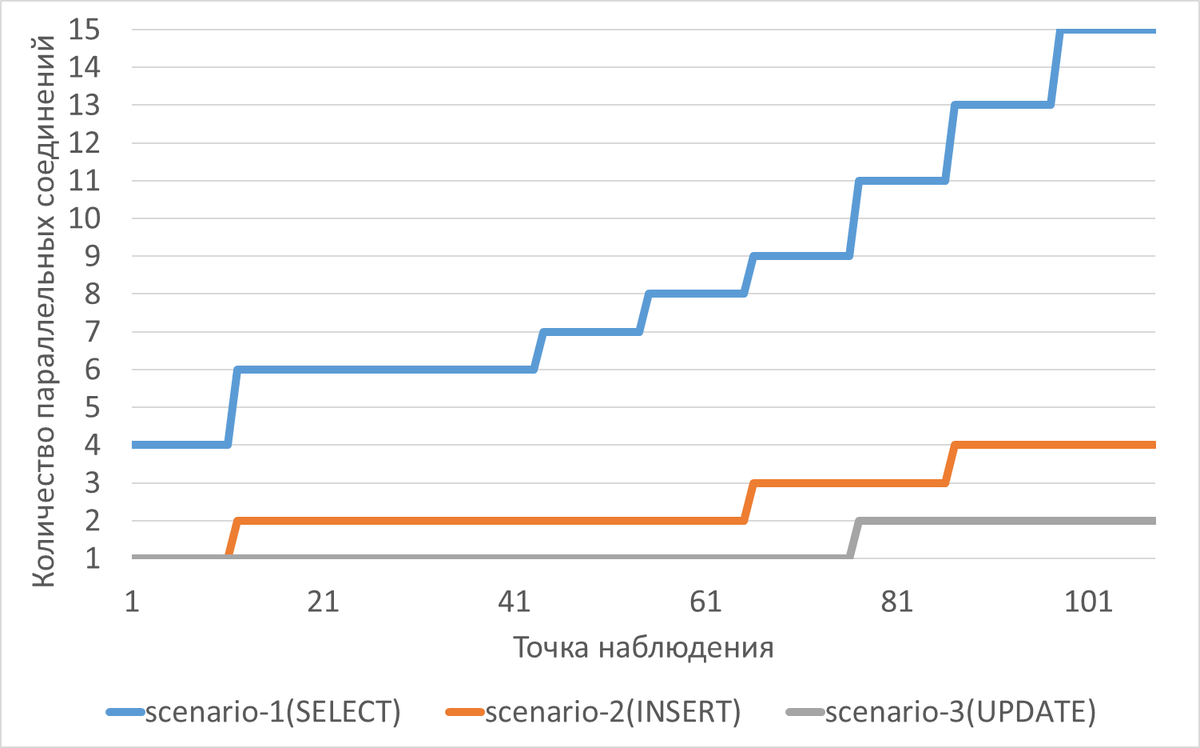
Нагрузка на СУБД в ходе экспериментов
Корреляционный анализ производительности и ожиданий СУБД
Операционная скорость
Ожидания СУБД
Производительность подсистемы IO
IOPS (Производительность IO)
MB/s (Пропуская способность IO)
Анализ производительности и ожиданий СУБД и метрик vmstat
Проанализируй данные по метрикам производительности и ожиданий СУБД , метрикам инфраструктуры vmstat/iostat. Подготовь итоговый отчет по результатам анализа. Для построения отчета используй списки вместо таблиц.
Общая картина производительности
- Период тестирования: 2026-01-15 10:24 - 2026-01-15 12:11 (108 минут)
- Нагрузка: Постепенно возрастала с 5 до 22 единиц в течение теста
- Производительность СУБД: выросла с ~318 667 до ~374 484 единиц
- Ожидания СУБД: Значительно выросли с ~31,225 до ~86,203 единиц
Ключевые проблемы производительности
1. Критическая проблема с I/O подсистемой
Симптомы:
- Очень высокая корреляция ожиданий IO и времени ожидания I/O (wa) в vmstat: 0.9407
- Очень высокая корреляция ожиданий IO и процессов в состоянии D (блокированных): 0.9761
- 100% наблюдений показывают время ожидания I/O выше 10%
- Процессы в состоянии uninterruptible sleep превышают количество ядер CPU в 56.48% наблюдений
Причины (из анализа):
- Неоптимальные настройки I/O подсистемы (scheduler, лимиты IOPS/пропускной способности)
- Медленный диск или неправильная настройка контроллера/ФС
- Вероятные проблемы с настройками виртуальной памяти (vm.dirty_*)
2. Проблемы с памятью
Симптомы:
- 100% наблюдений показывают свободной RAM менее 5%
- Сильная корреляция скорости операций с чтением блоков: 0.9958
- Высокое соотношение прочитанных к записанным блокам: 4.3717 (OLAP-сценарий)
3. Анализ ожиданий СУБД
Распределение ожиданий:
- IO (99.48%): DataFileRead (основное событие)
- IPC (0.10%): BufferIo
- Lock (<0.01%): relation (53.85%), extend (46.15%)
Основные проблемные запросы:
- select scenario1() (queryid: 6697384987258542853)
- 73.03% всех ожиданий IO
- 59.34% всех ожиданий IPC
- Выполнен 13+ миллионов раз
- select scenario2() (queryid: -6955341207442296116)
- 17.13% всех ожиданий IO
- 26.37% всех ожиданий IPC
- 100% всех ожиданий Lock
- Выполнен 2.8+ миллионов раз
Анализ инфраструктуры
Конфигурация сервера:
- CPU: 8 ядер, Intel Xeon (Skylake)
- RAM: 7.5 GB
- Дисковая подсистема: Раздельные LVM для данных (/data - 100G), WAL (/wal - 50G), логов (/log - 30G)
Положительные аспекты:
- Отсутствие свопинга (swap in/out = 0%)
- Нормальная загрузка CPU (user+system < 30%)
- Отсутствие очереди выполнения процессов (procs_r в норме)
Рекомендации по оптимизации
Неотложные меры (I/O подсистема):
- Оптимизация настроек виртуальной памяти:
- Проверить и настроить параметры vm.dirty_background_bytes и vm.dirty_bytes
- Уменьшить значения для более частой и плавной записи "грязных" страниц
- Оптимизация настройки дисковой подсистемы:
- Проверить и настроить I/O scheduler (deadline или noop для SSD)
- Проверить лимиты IOPS/пропускной способности в виртуальной среде
- Рассмотреть использование более производительных дисков
- Оптимизация настроек PostgreSQL:
- Увеличить shared_buffers (текущее значение 1GB при 7.5GB RAM)
- Настроить effective_cache_size для текущей рабочей нагрузки
- Оптимизировать параметры контрольных точек
Вывод
Система испытывает критическую нагрузку на I/O подсистему, что является основным узким местом производительности. Память практически полностью утилизирована, что приводит к интенсивному чтению с диска. Рекомендуется начать с оптимизации настроек виртуальной памяти и дисковой подсистемы, затем перейти к оптимизации проблемных запросов и увеличению ресурсов памяти для кэширования.
Анализ производительности IO для файловой системы /data
Подготовь отчет по результатам анализа производительности подсистемы IO
для дисковых устройств, используемых для файловых систем /data /wal
**Общая характеристика системы**
- Период анализа
- Основные устройства хранения
- Тип нагрузки
Состав отчета по файловой системе:
**Критические проблемы производительности по файловой системе**
**Анализ корреляций и паттернов нагрузки по файловой системе**
**Диагностика узких мест IO по файловой системе**
- r_await(ms)
- w_await(ms)
- aqu_sz
- proc_b
- cpu_wa(%)
- Корреляция speed с IOPS
- Корреляция speed с пропускной способностью (MB/s)
- Вывод по диагностике узких мест IO
**Рекомендации по оптимизации файловой системы**
**Итоговый вывод по производительности IO**
Для построения отчета используй списки вместо таблиц.
1. Общая характеристика системы
Основные устройства хранения:
- /data – устройство vdd (100 ГБ, LVM: vg_data-LG_data)
- /wal – устройство vdc (50 ГБ, LVM: vg_wal-LG_wal)
Тип нагрузки:
- OLAP-сценарий с преобладанием операций чтения (соотношение read/write ≈ 4.37:1)
- Смешанная нагрузка на устройстве /data (высокая корреляция с IOPS и пропускной способностью)
- Нагрузка, не ограниченная IO на устройстве /wal (низкая корреляция с IOPS и MB/s)
2. Критические проблемы производительности
Для файловой системы /data (vdd):
- Постоянная 100% загрузка устройства (%util = 100% во всех наблюдениях)
- Высокое время ожидания CPU для IO (cpu_wa: 58–74%)
- Большая глубина очереди запросов (aqu_sz: 12–28, превышает 1 в 100% наблюдений)
- Процессы в состоянии uninterruptible sleep превышают количество ядер CPU (proc_b > 8 ядер)
- Высокая корреляция между ожиданием CPU и загрузкой диска (0.8978) – процессы простаивают в ожидании IO
Для файловой системы /wal (vdc):
- Высокая загрузка устройства (%util: 56–64%, постоянно >50%)
- Высокое время ожидания CPU для IO (общее с системой)
3. Анализ корреляций и паттернов нагрузки
Для /data (vdd):
- Корреляция speed – IOPS: 0.9509 (очень высокая) – классический OLTP-паттерн
- Корреляция speed – MB/s: 0.9602 (очень высокая) – классический OLAP-паттерн
- Смешанный тип нагрузки – производительность ограничена как IOPS, так и пропускной способностью
- Кэширование связано с большим чтением с диска (корреляция shared_blks_hit – shared_blks_read: 0.9221)
Для /wal (vdc):
- Корреляция speed – IOPS: 0.0320 (слабая) – IOPS не является ограничивающим фактором
- Корреляция speed – MB/s: 0.1799 (слабая) – нагрузка чувствительна к объёму данных
- Узкое место не в IO – вероятно, в CPU, блокировках или настройках параллелизма
4. Диагностика узких мест IO
Для файловой системы /data (vdd):
- r_await(ms): 3–7 мс (MIN 3, MAX 7)
- w_await(ms): 2–5 мс (MIN 2, MAX 5)
- aqu_sz: 12–28 (MIN 12, MAX 28) – высокая очередь запросов
- proc_b: 6–15 процессов в состоянии D (uninterruptible sleep)
- cpu_wa(%): 58–74% – CPU простаивает в ожидании IO
- Корреляция speed – IOPS: 0.9509 (сильная зависимость)
- Корреляция speed – MB/s: 0.9602 (сильная зависимость)
- Вывод: Узкое место – дисковая подсистема /data. Диск постоянно перегружен, высокая очередь, процессы блокируются.
Для файловой системы /wal (vdc):
- r_await(ms): 0 мс (чтение отсутствует)
- w_await(ms): 1 мс (стабильно низкое)
- aqu_sz: ~1 (очередь минимальна)
- proc_b: 6–15 процессов в состоянии D
- cpu_wa(%): 58–74% (общее для системы)
- Корреляция speed – IOPS: 0.0320 (слабая)
- Корреляция speed – MB/s: 0.1799 (слабая)
- Вывод: Узкое место не в IO устройства /wal. Проблема в общей нагрузке на систему или в настройках СУБД.
5. Рекомендации по оптимизации
Для файловой системы /data (vdd):
- Рассмотреть переход на более производительные диски (SSD/NVMe)
- Увеличить размер shared_buffers для кэширования данных
- Оптимизировать запросы – уменьшить последовательное чтение больших объёмов
- Настроить параметры работы с IO:
- Увеличить effective_io_concurrency
- Настроить random_page_cost в зависимости от типа диска
- Рассмотреть разделение данных по табличным пространствам
Для файловой системы /wal (vdc):
- Проверить настройки WAL:
- Увеличить wal_buffers
- Настроить commit_delay и commit_siblings
- Оптимизировать частоту контрольных точек (checkpoint_timeout, max_wal_size)
- Проанализировать блокировки и конфликты в СУБД
Общие рекомендации:
- Увеличить объём ОЗУ для кэширования (текущий hit ratio ~92.7%)
- Настроить мониторинг процессов в состоянии D
- Рассмотреть балансировку нагрузки между дисками
- Проверить использование индексов и выполнить VACUUM ANALYZE
6. Итоговый вывод по производительности IO
Критическая ситуация на устройстве /data (vdd):
- Дисковая подсистема является узким местом производительности
- Постоянная 100% загрузка диска, высокие задержки, большая очередь запросов
- Процессы блокируются в ожидании IO, CPU простаивает
Устройство /wal (vdc) не является узким местом в IO, но общая нагрузка на систему приводит к высокому cpu_wa.
Необходимы срочные меры по апгрейду дискового оборудования для /data и оптимизации конфигурации СУБД для снижения нагрузки на диск. Без этого дальнейшее масштабирование нагрузки невозможно.
Итог
Проведённое нагрузочное тестирование выявило критическое состояние I/O-подсистемы, в первую очередь диска /data. Наблюдается постоянная 100% загрузка, высокие задержки и большая очередь запросов, из-за чего процессы блокируются, а процессор простаивает в ожидании операций с диском. Память практически полностью утилизирована, что усугубляет нагрузку на диск. Ключевыми проблемными запросами являются scenario1 и scenario2. Для восстановления и повышения производительности требуются срочные меры: апгрейд дискового оборудования, оптимизация настроек виртуальной памяти и PostgreSQL, а также пересмотр параметров WAL и кэширования.