
Статья посвящена анализу производительности системы на основе PostgreSQL в условиях нагрузочного тестирования, для увеличенного значения shared_buffers = 4GB. Основное внимание уделено выявлению узких мест в подсистемах ввода-вывода (I/O) и памяти, а также их влиянию на общую производительность СУБД. Результаты анализа служат основой для формирования конкретных рекомендаций по оптимизации инфраструктуры и конфигурации базы данных.
Глоссарий терминов | Postgres DBA | Дзен
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Начало - Эксперимент-1(shared_buffers = 1GB)
Корреляционный анализ производительности и ожиданий СУБД
Операционная скорость
Ожидания СУБД
Производительность подсистемы IO
IOPS (Производительность IO)
MB/s (Пропуская способность IO)
Анализ производительности и ожиданий СУБД и метрик vmstat
Проанализируй данные по метрикам производительности и ожиданий СУБД , метрикам инфраструктуры vmstat/iostat. Подготовь итоговый отчет по результатам анализа. Для построения отчета используй списки вместо таблиц.
1. Общая информация о системе
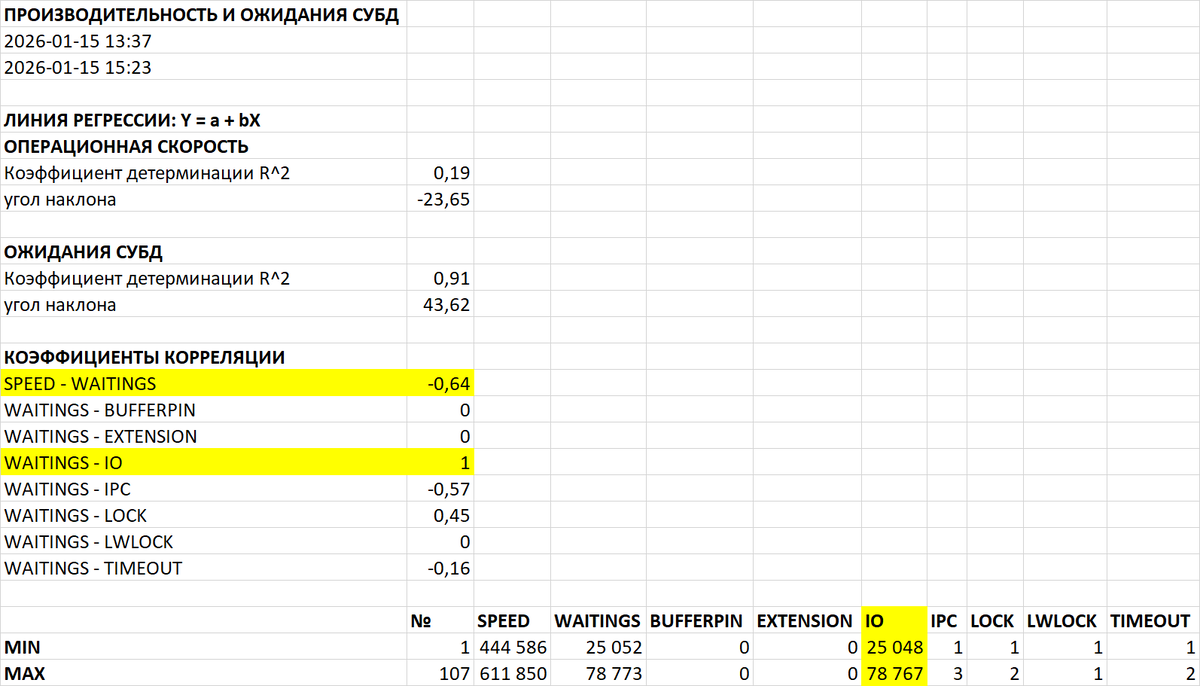
- Дата тестирования: 15 января 2026 г., период с 13:37 до 15:23
- Конфигурация сервера:
CPU: 8 ядер, Intel Xeon (Skylake)
RAM: 7,5 ГБ
Дисковая подсистема:
Данные: 100 ГБ (vdd → /data)
WAL: 50 ГБ (vdc → /wal)
Логи: 30 ГБ (vdb → /log)
Система: 70 ГБ (vda → /, /boot, /tmp и др.)
2. Ключевые проблемы производительности
2.1 Основная проблема: Высокая нагрузка на ввод-вывод (I/O Bottleneck)
- Высокая корреляция ожиданий СУБД с метриками I/O:
Корреляция IO-wa: 0,9393 (очень высокая)
Корреляция IO-b: 0,9757 (очень высокая) - Фактические показатели:
100% наблюдений имеют ожидание I/O (wa) > 10%
98,9% событий ожидания СУБД — операции чтения данных (DataFileRead)
Количество процессов в состоянии непрерываемого сна (ожидание диска) возрастает - Последствия:
Процессы переходят в состояние непрерываемого сна, ожидая ответа от диска
Даже базовые операции записи WAL и сброса буферов занимают неприемлемо много времени
Производительность операций напрямую зависит от скорости чтения с диска
2.2 Проблемы с памятью
- Недостаток свободной оперативной памяти:
100% наблюдений имеют свободной RAM менее 5%
Отсутствие свопинга (swap in/out) не используется - Возможное влияние на производительность:
Недостаток кэширования данных в памяти
Увеличение нагрузки на дисковую подсистему
2.3 Динамика производительности СУБД
- Ожидания СУБД:
Четкая тенденция роста (R² = 0,91)
Увеличение с ~25 тыс. до ~78 тыс. единиц
Угол наклона: +43,62 - Операционная скорость:
Снижение производительности при росте нагрузки
Угол наклона: -23,65
R² = 0,19 (слабая детерминация) - Корреляция скорость-ожидания: -0,64 (умеренная отрицательная)
2.4 Распределение нагрузки по SQL-запросам
- 80% ожиданий I/O вызывают два запроса:
select scenario1() — 78,74% ожиданий I/O (3,59 млн событий)
select scenario2() — 13,48% ожиданий I/O (0,61 млн событий) - Характер операций: преимущественно операции чтения (DataFileRead)
2.5 Анализ CPU
- Положительные аспекты:
Нет перегрузки очереди выполнения (run queue)
Доля системного времени (sy) в норме (<30%) - Предупреждение:
Высокая корреляция переключений контекста с пользовательским временем (0,6814)
3. Рекомендации по оптимизации
3.1 Оптимизация дискового ввода-вывода
- Настройка I/O подсистемы:
Проверить и оптимизировать планировщик ввода-вывода (scheduler)
Убедиться в адекватных лимитах IOPS/пропускной способности
Рассмотреть использование более производительных дисков (SSD/NVMe) - Настройка виртуальной памяти ОС:
Проверить параметры vm.dirty_background_bytes и vm.dirty_bytes
Уменьшить значения для предотвращения накопления "грязных" данных
3.2 Оптимизация памяти
- Увеличение объема оперативной памяти: текущих 7,5 ГБ недостаточно
- Настройка параметров PostgreSQL:
Пересмотреть соотношение shared_buffers (4 ГБ) и effective_cache_size (6 ГБ)
Возможно увеличение work_mem с 32 МБ при условии контроля за max_connections (1000)
3.3 Оптимизация конфигурации PostgreSQL
- Для текущей рабочей нагрузки (OLAP-характер):
Проверить эффективность индексов для запросов scenario1() и scenario2()
Рассмотреть увеличение maintenance_work_mem для улучшения производительности служебных операций - Мониторинг и настройка:
Использовать pg_stat_statements для анализа тяжелых запросов
Мониторить выполнение контрольных точек с текущими настройками
3.4 Оптимизация SQL-запросов
- Приоритетная оптимизация запроса scenario1():
Анализ плана выполнения
Добавление/оптимизация индексов
Возможное кэширование результатов - Вторичная оптимизация запроса scenario2():
Аналогичный анализ и оптимизация
4. Заключение
Основным узким местом системы является производительность дискового ввода-вывода, что особенно критично для рабочей нагрузки с преобладанием операций чтения. Недостаток оперативной памяти усугубляет ситуацию, увеличивая нагрузку на дисковую подсистему.
Приоритетные действия:
- Оптимизация производительности дискового ввода-вывода
- Увеличение объема оперативной памяти
- Оптимизация наиболее ресурсоемких SQL-запросов (scenario1() и scenario2())
- Настройка параметров памяти PostgreSQL и ОС
Система демонстрирует признаки масштабируемости в условиях роста нагрузки, но требует оптимизации для достижения стабильной производительности.
Анализ производительности IO для файловой системы /data
Подготовь отчет по результатам анализа производительности подсистемы IO
для дисковых устройств, используемых для файловых систем /data /wal
**Общая характеристика системы**
- Период анализа
- Основные устройства хранения
- Тип нагрузки
Состав отчета по файловой системе:
**Критические проблемы производительности по файловой системе**
**Анализ корреляций и паттернов нагрузки по файловой системе**
**Диагностика узких мест IO по файловой системе**
- r_await(ms)
- w_await(ms)
- aqu_sz
- proc_b
- cpu_wa(%)
- Корреляция speed с IOPS
- Корреляция speed с пропускной способностью (MB/s)
- Вывод по диагностике узких мест IO
**Рекомендации по оптимизации файловой системы**
**Итоговый вывод по производительности IO**
Для построения отчета используй списки вместо таблиц.
Период анализа: 2026-01-15 13:37 – 2026-01-15 15:23
Основные устройства хранения:
- vdd (100 ГБ, LVM: /data) — основное хранилище данных
- vdc (50 ГБ, LVM: /wal) — журнал транзакций (WAL)
Тип нагрузки: Смешанная (OLAP + OLTP) с преобладанием операций чтения на /data и записи на /wal.
1. Анализ файловой системы /data (устройство vdd)
Критические проблемы производительности:
- Загрузка устройства 100% (%util = 100) на всём интервале анализа.
- Высокая очередь запросов (aqu_sz до 38), что указывает на перегруженность диска.
- Высокое ожидание CPU для IO (cpu_wa 50–71%), процессы не могут выполняться из-за ожидания диска.
- Процессы в состоянии D (uninterruptible sleep) превышают количество ядер CPU (42,99% наблюдений).
- Высокое соотношение чтения к записи (2.91:1), что характерно для OLAP-нагрузки.
Анализ корреляций и паттернов нагрузки:
- Сильная положительная корреляция между cpu_wa и device_util (0.9422) — диск является узким местом.
- Сильная отрицательная корреляция между кэшированием и операциями записи (до -0.9289) — память используется недостаточно эффективно для снижения нагрузки на диск.
- Высокая корреляция между скоростью операций и чтением с диска (0.9691) — производительность напрямую зависит от скорости чтения с диска.
Диагностика узких мест IO:
- r_await(ms): 2–5 мс (в норме)
- w_await(ms): 2–15 мс (в норме)
- aqu_sz: до 38 (критически высоко)
- proc_b: до 7 процессов в состоянии D (выше количества ядер)
- cpu_wa(%): 50–71% (критически высоко)
- Корреляция speed – IOPS: -0.7012 (отрицательная) — проблема не в IOPS
- Корреляция speed – MB/s: -0.8707 (отрицательная) — проблема не в пропускной способности
- Вывод: Узкое место — неспособность диска обрабатывать очередь запросов, процессы блокируются из-за ожидания IO, возможна нехватка RAM для кэширования.
Рекомендации по оптимизации:
- Увеличить объём оперативной памяти для кэширования данных.
- Рассмотреть переход на более производительные диски (SSD/NVMe).
- Оптимизировать запросы к БД: добавить индексы, уменьшить seq scan.
- Настроить параметры СУБД (увеличить shared_buffers, настроить work_mem).
- Возможно, распределить нагрузку по нескольким дискам (разделение данных и индексов).
2. Анализ файловой системы /wal (устройство vdc)
Критические проблемы производительности:
- Загрузка устройства высокая (63–85%), но ниже, чем у vdd.
- Отсутствие операций чтения — чистая запись.
- Корреляция speed – IOPS положительная (0.9412) — типичный OLTP-паттерн.
Анализ корреляций и паттернов нагрузки:
- Отрицательная корреляция между cpu_wa и device_util (-0.4931) — ожидание IO не связано с загрузкой диска.
- Слабая корреляция между кэшированием и записью (0.4818) — память используется умеренно эффективно.
Диагностика узких мест IO:
- r_await(ms): 0 мс (чтения нет)
- w_await(ms): 0.55–0.59 мс (отлично)
- aqu_sz: ~1 (очень низкая очередь)
- proc_b: до 16 процессов в состоянии D (выше ядер)
- cpu_wa(%): 50–71% (высокое, как и на vdd)
- Корреляция speed – IOPS: 0.9412 (очень высокая) — производительность зависит от IOPS
- Корреляция speed – MB/s: -0.7604 (отрицательная) — пропускная способность не является ограничением
- Вывод: Устройство /wal справляется с нагрузкой, но общее высокое cpu_wa указывает на системную проблему с IO, возможно, из-за влияния vdd.
Рекомендации по оптимизации:
- Мониторинг утилизации диска, при росте нагрузки — рассмотреть SSD.
- Настройка параметров WAL в СУБД (wal_buffers, checkpoint_segments).
- Размещение /wal на отдельном физическом диске для изоляции нагрузки.
3. Итоговый вывод по производительности IO
Общий статус: Критический для /data, удовлетворительный для /wal.
Ключевые проблемы:
- Устройство /data перегружено (100% util, высокая очередь, процессы в D).
- Высокое время ожидания IO процессором (wa > 50%) по всей системе.
- Неэффективное использование RAM для кэширования, особенно на /data.
- Нагрузка имеет смешанный характер (OLAP + OLTP), что усложняет оптимизацию.
Рекомендуемые действия в порядке приоритета:
- Немедленно: Увеличить RAM для кэширования и оптимизировать запросы к БД.
- Среднесрочно: Рассмотреть переход на SSD для /data.
- Долгосрочно: Провести редизайн нагрузки, разделив OLAP и OLTP на разные серверы или дисковые группы.
- Мониторинг: Регулярно отслеживать cpu_wa, %util, aqu_sz и proc_b.
Прогноз: Без оптимизации /data станет главным узким местом, что приведёт к дальнейшему снижению производительности СУБД и увеличению времени отклика приложений.
Итог
Основным ограничивающим фактором производительности является дисковый ввод-вывод (I/O bottleneck), особенно на устройстве хранения данных (/data), которое работает на 100% загрузки. Высокое время ожидания операций ввода-вывода приводит к блокировке процессов и снижению операционной скорости СУБД. Дополнительной проблемой является недостаток оперативной памяти, что усиливает нагрузку на дисковую подсистему. Ключевые запросы scenario1() и scenario2() генерируют основную часть нагрузки. Для устранения узких мест необходимы: оптимизация дискового ввода-вывода, увеличение RAM, настройка параметров PostgreSQL и рефакторинг проблемных SQL-запросов.