⚡️ DeepSeek Engram: условная память LLM через поиск.
DeepSeek опять шатают устои архитектуры трансформеров свежайшим пейпером, который доказывает, что новое — это хорошо и очень хитро забытое старое.
Пока все пытаются запихнуть в LLM как можно больше слоев и параметров, DeepSeek задались вопросом: зачем тратить дорогой компьют на запоминание фактов, если их можно просто подсмотреть? Знакомьтесь:
🟡Engram — модуль, который возвращает нас к дедам с N-грамами.
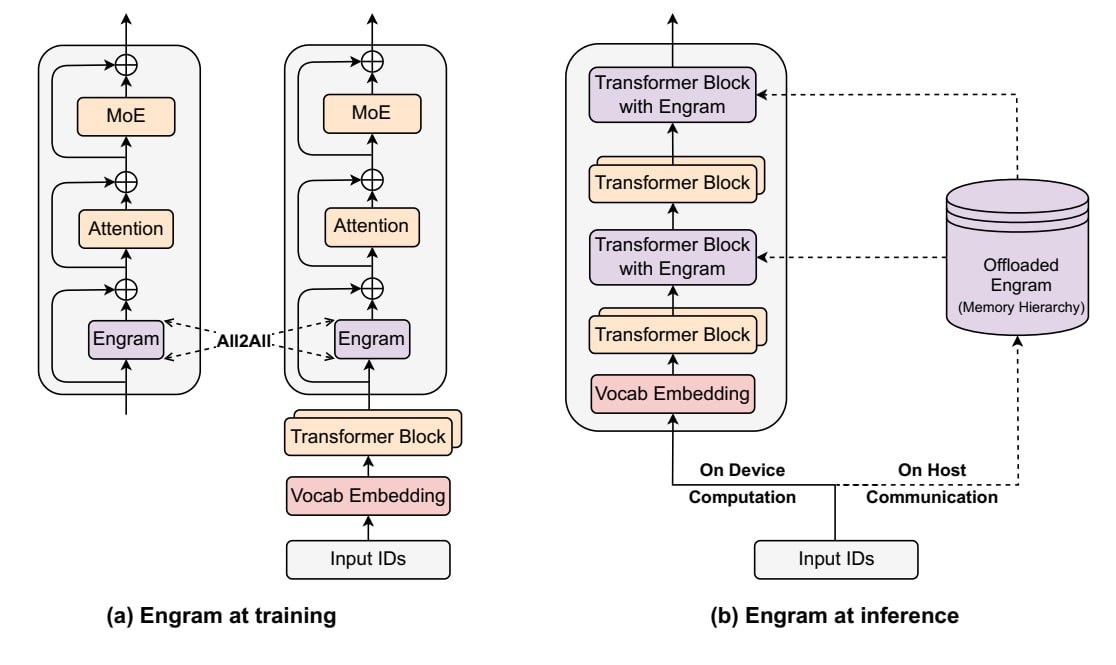
DeepSeek предлагает разделить "думалку" (MoE-слои) и "хранилище знаний" (Engram):
🟢Hashed N-grams: модуль смотрит на входящий текст и нарезает его на N-грамы (последовательности токенов).
🟢O(1) Lookup: система делает мгновенный запрос в гигантскую хэш-таблицу эмбеддингов - это чисто статический поиск.
🟢Context-Aware Gating: самый сок. Модель не просто слепо берет данные из "хранилища знаний" - специальный гейтинг-механизм решает: "Нам сейчас нужен факт из памяти или будем думать сами?". Если найденный N-грам релевантен контексту, он подмешивается в скрытое состояние.
🟢Tokenizer Compression: чтобы хранилище знаний не лопнуло от мусора, похожие токены в нем схлопывают в один ID, например, "Apple" и "apple".
🟡Баланс распределения ресурсов.
Чтобы правильно поделить бюджет параметров между MoE и Engram посчитали сценарии масштабирования. График лосса от соотношения этих частей выглядит как буква U:
🟠Перекос в MoE (100% вычислений): модель тратит дорогие слои внимания на запоминание статики. Это неэффективно, лосс высокий.
🟠Перекос в Память (0% вычислений): модель превращается в гигантскую википедию. Она помнит факты, но у нее напрочь атрофируется ризонинг. Лосс тоже высокий.
🟢Золотая середина (дно U-кривой): 80% MoE и ~20% Engram.
🟡Тесты и результаты.
DeepSeek обучили модель Engram-27B и сравнили ее с классической MoE-27B при одинаковом бюджете параметров и FLOPs. Итоги:
Общее качество подросло: MMLU +3.4 пункта, HumanEval (код) +3.0.
На длинном контексте - разнос. В тесте на поиск иголки (NIAH) точность выросла с 84.2 до 97.0. Модель разгрузила слои внимания от запоминания локальных паттернов, и оно сфокусировалось на глобальном контексте.
Модель быстрее сходится. Engram берет на себя рутину в ранних слоях, тем самым позволяя модели сразу учиться сложным вещам.
🟡Архитектурный нюанс.
Таблица эмбеддингов для Engram может быть запредельно огромной (в пейпере разгоняли до 100B параметров) и, очевидно, в VRAM это не влезает.
Решили так: раз ID токенов известен до прогона слоя, то эти данные можно хранить в RAM и асинхронно подтягивать. В реале, оверхед от этой механики показал меньше 3%., т.е. мы получаем модель, которая знает больше, чем влезает в GPU, используя оперативку сервера.
🟡DeepSeek фактически легализовала подобие шпаргалок для LLM.
Вместо того чтобы заставлять модель учить все наизусть, ей дают гигантский справочник. Теоретически, это открывает путь к прекрасному ИИ светлого будущего, который может иметь условно-бесконечную память, ограниченную только объемом оперативки, а не VRAM.
Похоже, в V4 мы увидим как эта схема работает, ведь инсайдеры обещают у нее запредельные скилы.
#AI #ML #LLM #Engram #Deepseek