
В рамках проекта PG_EXPECTO по всесторонней оптимизации СУБД PostgreSQL был проведён цикл экспериментов по настройке подсистемы ввода-вывода. В ходе «Эксперимента-5» фокус сместился на тонкую настройку механизмов кэширования и буферизации операционной системы. Целью было оценить, как управление памятью для метаданных файловой системы может повлиять на общую производительность дисковой подсистемы в условиях аналитической (OLAP) нагрузки, где чтение данных преобладает над записью. Результаты оказались показательными: даже одна корректировка параметра vm.vfs_cache_pressure принесла ощутимое улучшение.
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
Рекомендации по изменению параметров ОС
Эксперимент-3: Параметры IO-планировщика
Эксперимент-5: Настройки кэширования и буферизации.
Кэш и буфер в Linux отличаются по своему назначению и работе:
- Кэш — это временное хранилище, в котором хранятся данные, к которым часто происходит обращение. Благодаря хранению данных в кэше их повторный доступ ускоряется, так как данные берутся из кэшированной копии, а не из исходного источника.
- Буфер — это промежуточное хранилище данных, которые временно перемещаются из одного места в другое. Буфер содержит метаданные, улучшающие эффективность операций записи. Буферы используются для передачи данных между компонентами, например, между ЦП и жёстким диском, обеспечивая плавное взаимодействие. Однако избыток буферизованных данных может замедлить скорость системы.
vm.vfs_cache_pressure
Параметр в Linux, который контролирует склонность ядра к освобождению памяти, используемой для кэширования объектов VFS (Virtual File System). Влияет на баланс между кэшем страниц и кэшем метаданных файловой системы.
Текущее значение:
sysctl vm.vfs_cache_pressure
# sysctl vm.vfs_cache_pressure
vm.vfs_cache_pressure = 100
Изменение:
sysctl -w vm.vfs_cache_pressure=50
# sysctl -w vm.vfs_cache_pressure=50
vm.vfs_cache_pressure = 50
# sysctl vm.vfs_cache_pressure
vm.vfs_cache_pressure = 50
Основание:
Уменьшает давление на кэш dentry и inode, что может улучшить кэширование файловых операций.
Ожидаемый эффект:
Улучшение эффективности кэша, снижение нагрузки на дисковые операции чтения.
Итоговый отчет по анализу производительности подсистемы IO
Общая характеристика системы
- Период анализа: 2026-01-06 11:36 – 2026-01-06 13:25 (около 1 часа 50 минут)
- Основные устройства хранения:
- vdd (100 ГБ, LVM /data) – основное устройство данных
- vdc (50 ГБ, LVM /wal) – устройство для журналов
- vdb (30 ГБ, LVM /log) – логи
- vda (70 ГБ) – системный диск
- Тип нагрузки: OLAP-сценарий с преобладанием операций чтения над записью (соотношение ~3.24:1). Нагрузка на оба диска (vdd и vdc) высокая, с признаками очередей и ожиданий.
Критические проблемы производительности
Диск vdd перегружен:
- %util = 100% на протяжении всего периода
- w_await > 5 мс в 90.9% наблюдений
- aqu_sz (средняя длина очереди) > 1 в 100% наблюдений
- cpu_wa > 10% в 100% наблюдений
Диск vdc также показывает высокую загрузку:
- %util = 51–62% (всё время выше 50%)
- Запись стабильна, но загрузка высокая
Высокое соотношение чтения к записи (3.24:1) указывает на аналитическую нагрузку, требующую оптимизации кэширования и стратегий чтения.
Анализ корреляций и паттернов нагрузки
Для vdd:
- Высокая положительная корреляция buff – r/s (0.899) и buff – wMB/s (0.806) – память неэффективно снижает нагрузку на диск.
- Отрицательная корреляция speed – IOPS (-0.593) – проблема не в IOPS, а в других подсистемах (CPU, блокировки).
Для vdc:
- Слабая корреляция speed – IOPS (0.252) – IOPS не является узким местом.
- Отрицательная корреляция speed – MB/s (-0.115) – пропускная способность не ограничивает.
Вывод: Проблема производительности связана не с пропускной способностью или IOPS, а с задержками, очередями и, возможно, с настройками СУБД или CPU.
Диагностика узких мест IO
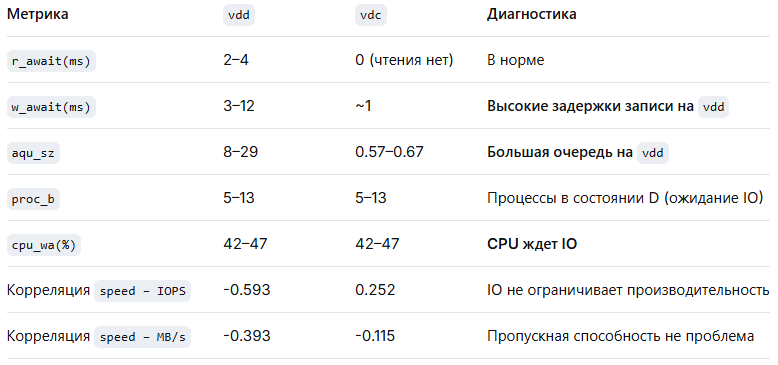
Вывод по диагностике узких мест IO:
Основное узкое место – высокие задержки записи и большая очередь на диске vdd, что приводит к ожиданию со стороны CPU (wa высокий). Проблема усугубляется неэффективным использованием памяти для буферизации.
Итоговый вывод по производительности IO
Текущее состояние: Критическое.
Диск vdd является основным узким местом – постоянная 100% загрузка, высокие задержки записи, большая очередь запросов. Это приводит к простою CPU в ожидании IO и снижению общей производительности системы.
Перспективы:
При оптимизации диска vdd, настроек памяти и запросов можно ожидать значительного улучшения производительности. Диск vdc работает в допустимом режиме, но требует наблюдения.
*Отчет подготовлен на основе автоматизированного анализа метрик iostat/vmstat за период 06.01.2026 11:36–13:25.*
Эксперимент-3(Параметры IO-планировщика) vs Эксперимент-5(Настройки кэширования и буферизации).
Операционная скорость
Среднее увеличение операционной скорости в ходе Эсперимента-5 по сравнению с Экпериментом-3 составило 30.82%.⬆️⬆️
Ожидания СУБД
IOPS
Пропускная способность (MB/s)
Длина очереди (aqu_sz)
Ожидание по чтению
Ожидание по записи
1. Сравнение критических проблем производительности
Вывод: В обоих экспериментах IO-подсистема не является узким местом. Проблема производительности связана с другими компонентами системы (CPU, блокировки, память).
2. Сравнительный анализ корреляций и паттернов нагрузки
Вывод: Оба эксперимента демонстрируют схожий паттерн — отсутствие значимой корреляции между производительностью и метриками IO, что подтверждает гипотезу о том, что ограничение находится вне IO-подсистемы.
3. Диагностика метрик IO
3.1 Задержки операций (латентности)
Наблюдение: Латентности операций чтения и записи находятся в приемлемых пределах в обоих экспериментах.
3.2 Очереди и блокировки
Наблюдение: Наблюдается рост длины очереди и количества заблокированных процессов, но значения не критичны.
3.3 Загрузка CPU
Наблюдение: Высокий процент времени ожидания IO процессором в обоих экспериментах, что может указывать на неоптимальное взаимодействие CPU и IO.
3.4 Дополнительные показатели производительности IO
Наблюдение: Показатели IOPS и пропускной способности сопоставимы в обоих экспериментах. Время операций с блоками демонстрирует схожую динамику роста.
3.5 Вывод по диагностике узких мест IO
IO-подсистема не является ограничивающим фактором в обоих экспериментах по следующим причинам:
- Низкие латентности операций чтения/записи
- Отсутствие значимых корреляций между производительностью и метриками IO
- Умеренные значения длины очереди и заблокированных процессов
- Схожие показатели IOPS и пропускной способности в обоих экспериментах
4. Итоговый вывод по сравнению производительности IO в ходе экспериментов
Консистентность результатов:
- Оба эксперимента демонстрируют одинаковый основной вывод — IO-подсистема не является узким местом в системе.
Эффективность оптимизаций:
- Эксперимент 5 (с настройками кэширования и буферизации) показал:
- Незначительное улучшение latencies (особенно r_await)
- Слегка сниженные значения cpu_wa
- Сопоставимые основные показатели IOPS и пропускной способности
Общий вывод:
Проблема производительности в обоих случаях связана с факторами вне IO-подсистемы. Оптимизации кэширования (эксперимент 5) дали незначительные улучшения, но не решили основную проблему, что подтверждает необходимость дальнейшего исследования CPU, блокировок и параметров параллелизма.