
Производительность PostgreSQL в высокой степени зависит от корректной работы с памятью. Ядро Linux, управляя дисковым кэшем и буферами, может как значительно ускорить работу СУБД, так и стать причиной серьёзных проблем — от излишнего свопинга до деградации производительности из-за двойного кэширования. В статье предоставлены практические инструкции по настройке ключевых параметров ядра (vm.swappiness, vm.dirty_*, vm.vfs_cache_pressure) для оптимальной работы PostgreSQL.
Начало работ по теме
Исходные данные
Характер нагрузки на СУБД: преобладание чтения над записью
RAM = 8GB
shared_buffers = 2GB
🔍 Часть 1: Диагностика текущего состояния
1.1. Проверка параметров кэширования ОС Linux
1. Текущие значения параметров виртуальной памяти:
# Основные параметры dirty-страниц и буферизации
echo "=== Текущие настройки кэширования ОС ==="
sudo sysctl -a | grep -E "(dirty|swappiness|vfs_cache_pressure)" | grep -v net.ipv4
# Альтернативно - чтение напрямую из /proc/sys/vm
cat /proc/sys/vm/swappiness
cat /proc/sys/vm/dirty_background_ratio
cat /proc/sys/vm/dirty_ratio
cat /proc/sys/vm/dirty_expire_centisecs
cat /proc/sys/vm/dirty_writeback_centisecs
cat /proc/sys/vm/vfs_cache_pressure
2. Проверка состояния Transparent Huge Pages:
cat /sys/kernel/mm/transparent_hugepage/enabled
# Результат: [never] значит отключено, [always] - включено
3. Мониторинг текущего использования кэша и буферов:
# Общая статистика памяти
free -h
# Подробная информация о dirty-страницах
grep -E "(Dirty|Writeback|NFS_Unstable)" /proc/meminfo
# Динамический мониторинг (обновление каждые 2 секунды)
watch -n 2 'grep -E "(Dirty|Writeback)" /proc/meminfo && echo "---" && free -h | grep -v total'
4. Проверка активности диска (критично для анализа влияния записи):
# Установите sysstat если нет: sudo yum install sysstat / sudo apt-get install sysstat
iostat -x 2 5
# Обратите внимание на:
# - %util (загрузка диска)
# - await (среднее время ожидания)
# - avgqu-sz (средняя длина очереди)
1.2. Диагностика кэширования PostgreSQL
1. Подключение к базе данных и проверка hit ratio:
psql -U postgres -d БД
-- Общий hit ratio для всех таблиц
SELECT
sum(heap_blks_read) as heap_read,
sum(heap_blks_hit) as heap_hit,
CASE
WHEN sum(heap_blks_hit) > 0 THEN
ROUND((sum(heap_blks_hit)::numeric / (sum(heap_blks_hit) + sum(heap_blks_read))) * 100, 2)
ELSE 0
END as heap_hit_ratio,
sum(idx_blks_read) as idx_read,
sum(idx_blks_hit) as idx_hit,
CASE
WHEN sum(idx_blks_hit) > 0 THEN
ROUND((sum(idx_blks_hit)::numeric / (sum(idx_blks_hit) + sum(idx_blks_read))) * 100, 2)
ELSE 0
END as idx_hit_ratio
FROM pg_statio_user_tables;
-- Hit ratio по базам
SELECT
datname,
blks_read,
blks_hit,
ROUND((blks_hit::numeric / (blks_hit + blks_read)) * 100, 2) as hit_ratio
FROM pg_stat_database
WHERE datname NOT LIKE 'template%';
2. Анализ использования shared_buffers:
-- Установиnm расширение если еще не установлено
CREATE EXTENSION IF NOT EXISTS pg_buffercache;
-- Топ-10 таблиц в кэше
SELECT
c.relname as table_name,
COUNT(*) * 8 / 1024 as cached_mb,
pg_size_pretty(pg_relation_size(c.oid)) as table_size,
ROUND(COUNT(*) * 100.0 / (SELECT setting::numeric FROM pg_settings WHERE name='shared_buffers'), 2) as percent_of_cache
FROM pg_buffercache b
JOIN pg_class c ON b.relfilenode = pg_relation_filenode(c.oid)
WHERE c.relkind = 'r' -- только обычные таблицы
GROUP BY c.relname, c.oid
ORDER BY cached_mb DESC
LIMIT 10;
-- Распределение shared_buffers по типам данных
SELECT
CASE
WHEN usagecount IS NULL THEN 'Free'
ELSE usagecount::text
END as usage_count,
COUNT(*) * 8 / 1024 as mb,
ROUND(COUNT(*) * 100.0 / (SELECT setting::numeric FROM pg_settings WHERE name='shared_buffers'), 2) as percent
FROM pg_buffercache
GROUP BY usagecount
ORDER BY usagecount DESC NULLS FIRST;
3. Проверка временных файлов (переполнение work_mem):
SELECT
datname,
temp_files,
pg_size_pretty(temp_bytes) as temp_size,
ROUND(temp_bytes / 1024.0 / 1024.0 / NULLIF(temp_files, 0), 2) as avg_file_size_mb
FROM pg_stat_database
WHERE temp_files > 0;
-- Активные запросы, использующие временные файлы
SELECT
pid,
query,
temp_files,
temp_bytes
FROM pg_stat_activity
WHERE temp_files > 0 AND state = 'active';
4. Проверка текущих настроек PostgreSQL:
-- Критические настройки памяти
SELECT
name,
setting,
unit,
context
FROM pg_settings
WHERE name IN (
'shared_buffers',
'work_mem',
'maintenance_work_mem',
'effective_cache_size',
'wal_buffers',
'random_page_cost',
'effective_io_concurrency'
)
ORDER BY name;
⚙️ Часть 2: Оптимизация настроек
2.1. Оптимизация ОС Linux (требует прав root)
1. Создание оптимизированного профиля tuned:
# Создание директории для профиля
sudo mkdir -p /etc/tuned/postgresql-optimized
# Создание конфигурационного файла
sudo cat > /etc/tuned/postgresql-optimized/tuned.conf << 'EOF'
[main]
summary=Optimized for PostgreSQL with 8GB RAM, read-heavy workload
include=throughput-performance
[sysctl]
# Минимизация записи на диск (оптимизация для чтения)
vm.dirty_background_ratio = 2
vm.dirty_ratio = 5
vm.dirty_expire_centisecs = 6000
vm.dirty_writeback_centisecs = 1000
# Минимизация свопинга
vm.swappiness = 5
# Сохранение кэша dentry и inode (улучшение для частого чтения файлов)
vm.vfs_cache_pressure = 50
# Увеличение лимитов для большего количества соединений
fs.file-max = 2097152
EOF
# Активация профиля
sudo tuned-adm profile postgresql-optimized
sudo tuned-adm active # Проверка активации
2. Отключение Transparent Huge Pages:
# Немедленное отключение
echo never | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
echo never | sudo tee /sys/kernel/mm/transparent_hugepage/defrag
# Постоянное отключение (для систем с systemd)
sudo cat > /etc/systemd/system/disable-thp.service << 'EOF'
[Unit]
Description=Disable Transparent Huge Pages
[Service]
Type=oneshot
ExecStart=/bin/sh -c "echo never > /sys/kernel/mm/transparent_hugepage/enabled && echo never > /sys/kernel/mm/transparent_hugepage/defrag"
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable disable-thp.service
sudo systemctl start disable-thp.service
3. Настройка лимитов памяти для пользователя postgres:
# Добавьте в /etc/security/limits.conf или создайте файл в /etc/security/limits.d/
sudo cat >> /etc/security/limits.conf << 'EOF'
postgres soft memlock 8388608 # 8GB в kB
postgres hard memlock 8388608
postgres soft nofile 65536
postgres hard nofile 65536
EOF
# Для применения в текущей сессии
sudo prlimit --pid $(pgrep -u postgres) --memlock=8388608:8388608
2.2. Оптимизация PostgreSQL
1. Расчет оптимальных значений (для 8 ГБ RAM, shared_buffers=2GB):
# Автоматический расчет work_mem (пример для 100 соединений)
RAM_GB=8
SHARED_BUFFERS_GB=2
MAX_CONNECTIONS=100
WORK_MEM_MB=$(( (RAM_GB - SHARED_BUFFERS_GB) * 1024 / (MAX_CONNECTIONS * 2) ))
MAINTENANCE_MEM_MB=$(( RAM_GB * 64 )) # 5% от 8GB = 409MB, берем 512MB
EFFECTIVE_CACHE_GB=$(( RAM_GB * 3 / 4 )) # 75%
echo "Рекомендуемые значения:"
echo "work_mem = ${WORK_MEM_MB}MB"
echo "maintenance_work_mem = ${MAINTENANCE_MEM_MB}MB"
echo "effective_cache_size = ${EFFECTIVE_CACHE_GB}GB"
2. Применение настроек в postgresql.conf:
# Резервное копирование текущего конфига
sudo cp /var/lib/pgsql/data/postgresql.conf /var/lib/pgsql/data/postgresql.conf.backup.$(date +%Y%m%d)
# Редактирование конфигурации (используйте sudo и ваш любимый редактор)
sudo nano /var/lib/pgsql/data/postgresql.conf
Добавить или изменить следующие параметры:
# Базовые настройки памяти
shared_buffers = 2GB
work_mem = 24MB # Для 100 соединений
maintenance_work_mem = 512MB
effective_cache_size = 6GB
wal_buffers = 16MB
# Оптимизация для read-heavy нагрузки
random_page_cost = 1.1 # Для SSD (для HDD используйте 4.0)
effective_io_concurrency = 200 # Для SSD/NVMe
seq_page_cost = 1.0
# Оптимизация для частого чтения
default_statistics_target = 100
autovacuum_vacuum_scale_factor = 0.05
autovacuum_analyze_scale_factor = 0.02
# Настройки планировщика, учитывающие кэширование
geqo = on
geqo_threshold = 12
3. Применение изменений:
# Проверка синтаксиса конфига
sudo -u postgres /usr/pgsql-*/bin/postgres -D /var/lib/pgsql/data --config-file=/var/lib/pgsql/data/postgresql.conf --check
# Перезагрузка или полный рестарт PostgreSQL
# Только для параметров, требующих перезагрузки (shared_buffers, wal_buffers)
sudo systemctl restart postgresql
# Для остальных параметров - перезагрузка конфигурации
sudo -u postgres psql -c "SELECT pg_reload_conf();"
📊 Часть 3: Верификация и мониторинг после оптимизации
3.1. Создание скрипта для регулярного мониторинга
Создать файл monitor_pg_cache.sh:
#!/bin/bash
# Скрипт мониторинга кэширования PostgreSQL и ОС
echo "=== $(date) ==="
echo ""
echo "1. СОСТОЯНИЕ ПАМЯТИ ОС:"
free -h
echo ""
echo "2. DIRTY-СТРАНИЦЫ:"
grep -E "(Dirty|Writeback)" /proc/meminfo
echo ""
echo "3. HIT RATIO PostgreSQL:"
sudo -u postgres psql -t << EOF
SELECT
'Heap Hit Ratio: ' ||
ROUND((sum(heap_blks_hit)::numeric / NULLIF(sum(heap_blks_hit + heap_blks_read), 0)) * 100, 2) || '%',
'Index Hit Ratio: ' ||
ROUND((sum(idx_blks_hit)::numeric / NULLIF(sum(idx_blks_hit + idx_blks_read), 0)) * 100, 2) || '%'
FROM pg_statio_user_tables;
EOF
echo ""
echo "4. ИСПОЛЬЗОВАНИЕ SHARED_BUFFERS (топ-5 таблиц):"
sudo -u postgres psql -t << EOF
SELECT
c.relname || ': ' ||
COUNT(*) * 8 / 1024 || ' MB (' ||
ROUND(COUNT(*) * 100.0 / (SELECT setting::numeric FROM pg_settings WHERE name='shared_buffers'), 1) || '%)'
FROM pg_buffercache b
JOIN pg_class c ON b.relfilenode = pg_relation_filenode(c.oid)
WHERE c.relkind = 'r'
GROUP BY c.relname
ORDER BY COUNT(*) DESC
LIMIT 5;
EOF
echo ""
echo "5. ВРЕМЕННЫЕ ФАЙЛЫ:"
sudo -u postgres psql -t << EOF
SELECT
datname || ': ' ||
temp_files || ' files, ' ||
pg_size_pretty(temp_bytes) as temp_info
FROM pg_stat_database
WHERE temp_files > 0;
EOF
Сделайте скрипт исполняемым и запускайть регулярно:
chmod +x monitor_pg_cache.sh
# Добавьте в cron для ежечасного выполнения
(crontab -l 2>/dev/null; echo "0 * * * * /путь/к/monitor_pg_cache.sh >> /var/log/pg_cache_monitor.log") | crontab -
3.2. Ключевые метрики для контроля
Целевые показатели после оптимизации:
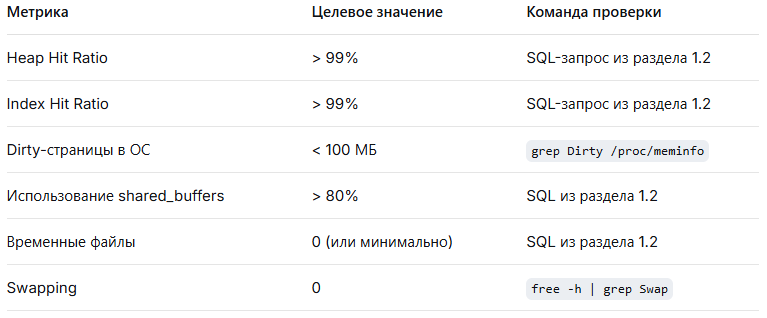
⚠️ Часть 4: Устранение распространенных проблем
Проблема 1: Низкий hit ratio (< 95%)
Решение:
-- Определить таблицы с низким кэшированием
SELECT
schemaname || '.' || relname as table_name,
heap_blks_hit,
heap_blks_read,
ROUND(heap_blks_hit * 100.0 / NULLIF(heap_blks_hit + heap_blks_read, 0), 2) as hit_percent
FROM pg_statio_user_tables
WHERE heap_blks_read > 1000
ORDER BY hit_percent ASC
LIMIT 10;
-- Возможные действия:
-- 1. Увеличить shared_buffers (если свободной RAM > 1GB)
-- 2. Добавить индексы для частых запросов
-- 3. Использовать pg_prewarm для критичных таблиц
Проблема 2: Частые временные файлы
Решение:
-- Запросы, генерирующие временные файлы
SELECT
pid,
left(query, 100) as query_part,
temp_files,
pg_size_pretty(temp_bytes) as temp_size
FROM pg_stat_activity
WHERE temp_files > 0;
-- Увеличить work_mem для конкретных запросов или глобально
-- Добавить индексы для сортируемых полей
Проблема 3: Высокий объем dirty-страниц в ОС
Решение:
# Если Dirty > 200MB постоянно, увеличить интервалы записи
sudo sysctl -w vm.dirty_expire_centisecs=10000
sudo sysctl -w vm.dirty_writeback_centisecs=2000
# Или уменьшить dirty_ratio если есть проблемы с отзывчивостью
sudo sysctl -w vm.dirty_ratio=10
📝 Краткий чек-лист ежедневного мониторинга
- Проверить hit ratio PostgreSQL (> 99%?)
- Проверить использование shared_buffers (> 80%?)
- Проверить наличие временных файлов
- Проверить dirty-страницы в ОС (< 100MB?)
- Проверить swappiness и отсутствие свопинга
🔗 Полезные команды для быстрой проверки
# Однострочник для быстрой проверки
echo "Hit Ratio: $(sudo -u postgres psql -t -c "SELECT ROUND((sum(heap_blks_hit)::numeric/NULLIF(sum(heap_blks_hit+heap_blks_read),0))*100,2) FROM pg_statio_user_tables;")% | Dirty: $(grep Dirty /proc/meminfo | awk '{print $2/1024" MB"}') | Shared buffers: $(sudo -u postgres psql -t -c "SELECT ROUND(COUNT(*)*100.0/(SELECT setting::numeric FROM pg_settings WHERE name='shared_buffers'),1) FROM pg_buffercache WHERE usagecount IS NOT NULL;")% used"