
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Часть-2: Инфраструктура - Анализ влияния checkpoint_timeout на производительность СУБД PostgreSQL при синтетической нагрузке(Вариант-1).
Вариант нагрузки №1
- Высокая нагрузка на CPU
- Высокая читающая нагрузка
- Низкая, конкурентная пишущая нагрузка.
Checkpoint_timeout не является линейным параметром - существует "резонансная зона" (около 15 мин), где наблюдаются наихудшие характеристики.
Оптимальное значение зависит от рабочей нагрузки - для данной конфигурации и сценариев оптимальным является 30 минут.
Вариант нагрузки №2
- Низкая нагрузка на CPU
- Низкая читающая нагрузка
- Высокая слабо конкурентная пишущая нагрузка.
Методология исследования
Тестовая среда, инструменты и конфигурация СУБД:
- СУБД: PostgreSQL 17
- Тестовая база данных: pgbench (10GB, простая структура)
- Условия тестирования: параллельная нагрузка от 7 до 22 сессий по каждому тестовому сценарию.
Тестовый сценарий-1 (SELECT)
Тестовый сценарий-2 (UPDATE)
Тестовый сценарий-3 (INSERT)
Часть-1:СУБД.
1.Сводная таблица результатов экспериментов
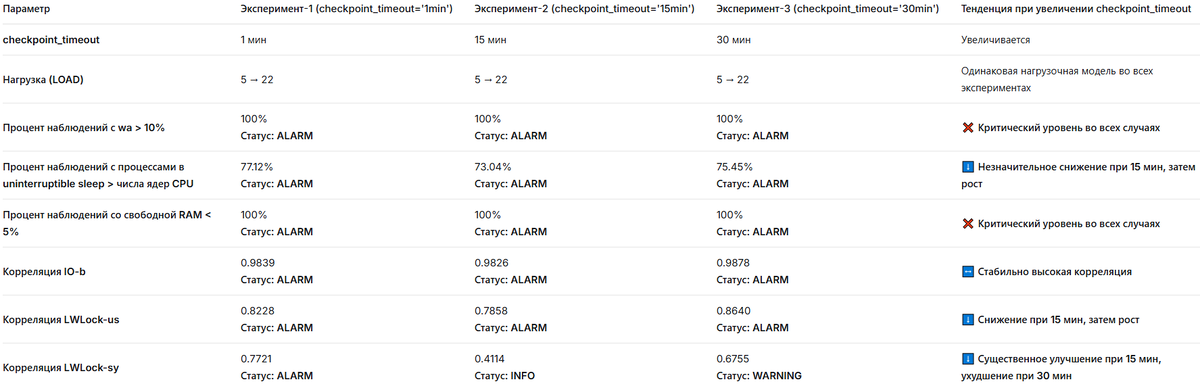
Анализ влияния checkpoint_timeout:
Отрицательные эффекты, не зависящие от checkpoint_timeout:
- Высокий IO wait (wa > 10%) - 100% наблюдений во всех экспериментах
- Недостаток свободной RAM - 100% наблюдений во всех экспериментах
- Высокая корреляция IO-b - процессы блокируются из-за ожидания IO
Эффекты, зависящие от checkpoint_timeout:
- Лучший результат при checkpoint_timeout='15min':
Наименьший процент процессов в uninterruptible sleep > числа ядер CPU (73.04%)
Наименьшая корреляция LWLock-us (0.7858)
Значительное улучшение по LWLock-sy - снижение с ALARM до INFO уровня - Худшие результаты:
При 1 мин: высокая корреляция LWLock-sy (ALARM)
При 30 мин: рост корреляции LWLock-us и LWLock-sy по сравнению с 15 мин
Выводы:
- Основные проблемы системы (недостаток RAM, высокий IO wait) не решаются изменением checkpoint_timeout
- Оптимальное значение checkpoint_timeout в данном контексте - 15 минут, так как оно дает:
Наименьшую нагрузку на процессы
Лучшие показатели по блокировкам (LWLock) - Даже при оптимальном checkpoint_timeout система остается в критическом состоянии по ключевым метрикам (IO, RAM)
2. Анализ влияния checkpoint_timeout на IO и процессы
2.1. Ожидание IO (wa)
Вывод по wa: Все три значения checkpoint_timeout приводят к критически высокому ожиданию ввода-вывода (100% наблюдений с wa > 10%). Это указывает на системную проблему с производительностью дисков, которая не решается изменением интервала контрольных точек.
2.2. Количество процессов в состоянии uninterruptible sleep (b)
Вывод по процессам b:
- Все три конфигурации показывают критический уровень блокированных процессов
- Наименьшее значение при checkpoint_timeout='15min' (73.04%)
- Угол наклона регрессии показывает скорость роста блокированных процессов относительно wa:
Наибольший при 1 мин (44.62) - процессы быстрее блокируются
Наименьший при 15 мин (42.77) - наиболее стабильное поведение
При 30 мин возвращается к высокому значению (44.01)
2.3. Корреляция между ожиданием IO и процессами b (IO-b)
Вывод по корреляции IO-b:
- Все значения показывают чрезвычайно высокую корреляцию (близкую к 1.0)
- Наивысшая корреляция при 30 мин (0.9878)
- Наименьшая (хотя все равно критическая) при 15 мин (0.9826)
- Это означает, что увеличение ожидания IO почти гарантированно приводит к росту блокированных процессов при любом checkpoint_timeout
2.4. Корреляция между ожиданием IO и операциями ввода-вывода
Корреляция IO-bi (чтение):
Корреляция IO-bo (запись):
Вывод по корреляции IO-bi/bo:
- Операции чтения (bi):
Наименьшая корреляция при 15 мин (0.7447)
Наибольшая при 30 мин (0.9063)
При 1 мин также высокая (0.8980) - Операции записи (bo):
Наивысшая корреляция при 1 мин (0.9888)
Уменьшается при увеличении checkpoint_timeout
Наименьшая при 30 мин (0.9246), хотя все равно критическая
ОБЩИЙ ВЫВОД: Наиболее критичное значение checkpoint_timeout
Наиболее критичный: checkpoint_timeout='1min'
Почему:
- Наибольшая корреляция с операциями записи (0.9888) - при частых контрольных точках ожидание IO почти полностью определяется операциями записи
- Наибольший процент блокированных процессов (77.12%) - больше времени процессы проводят в ожидании IO
- Наибольший угол наклона регрессии (44.62) - наиболее быстрое нарастание проблем при увеличении нагрузки
- Частые контрольные точки приводят к постоянной фоновой нагрузке на диск, мешающей основной работе
Сравнительная характеристика:
Рекомендации:
- Избегать checkpoint_timeout='1min' - создает наибольшую нагрузку на систему
- Оптимальный диапазон: 15-30 минут - 15 минут показывает лучший баланс
- Проблема системная - даже при оптимальном checkpoint_timeout система остается в критическом состоянии по IO
- Необходимы дополнительные меры:
Увеличение checkpoint_completion_target для более плавной записи
Увеличение shared_buffers для уменьшения потребности в записи на диск
Увеличить bgwriter_delay и bgwriter_lru_maxpages для оптимизации фоновой записи
Ключевая проблема: Система испытывает системный дефицит производительности ввода-вывода, который не может быть решен только настройкой checkpoint_timeout.
3. Анализ использования памяти и свопинга
3.1. Процент наблюдений со свободной RAM < 5%
Во всех трёх экспериментах 100% наблюдений показывают критически низкий уровень свободной памяти (<5%). Изменение checkpoint_timeout не влияет на этот показатель.
3.2. Использование свопинга (si, so)
Свопинг не используется ни в одном из экспериментов. Несмотря на критически низкий уровень свободной RAM, система не прибегает к использованию дискового пространства для виртуальной памяти.
3.3. Корреляция между ожиданием IO и свопингом
Нет корреляции между ожиданием ввода-вывода и операциями свопинга. Это подтверждает, что проблемы с IO не связаны со свопингом данных.
3.4. Связь объёма буферов/кэша и операций чтения/записи на диск
Анализ по дискам vdc (wal) и vdd (data):
Для всех экспериментов и обоих дисков:
- Корреляция buff - r/s: 0.0000 (OK)
- Корреляция buff - rMB/s: 0.0000 (OK)
- Корреляция buff - w/s: 0.0000 (OK)
- Корреляция buff - wMB/s: 0.0000 (OK)
- Корреляция cache - r/s: 0.0000 (OK)
- Корреляция cache - rMB/s: 0.0000 (OK)
- Корреляция cache - w/s: 0.0000 (OK)
- Корреляция cache - wMB/s: 0.0000 (OK)
Значения буферов и кэша:
- Memory buff MIN: 3-6 MB, MAX: 4-37 MB
- Memory cache MIN: ~7032 MB, MAX: ~7209 MB
- Ключевое наблюдение: Кэш использует практически всю доступную память (более 7GB из 7.5GB)
Вывод по достаточности 7.5 GB RAM для данной нагрузки
🔴 7.5 GB RAM НЕДОСТАТОЧНО для данной нагрузки
Доказательства:
- 100% наблюдений с <5% свободной памяти - система постоянно работает на пределе
- Кэш занимает >93% всей памяти (~7GB), оставляя минимальный запас для других нужд
- Хотя свопинг не используется, это может быть связано с настройками ядра (vm.swappiness), а не с достаточностью памяти
Как checkpoint_timeout влияет на использование памяти:
Комплексный анализ проблемы с памятью:
- Проблема не в checkpoint_timeout - изменение этого параметра не решает проблему с памятью
- Кэш работает неэффективно - несмотря на огромный объём кэша (7GB+), нет корреляции с операциями ввода-вывода
- Возможные причины:
Неоптимальные настройки кэширования в PostgreSQL
Неправильное распределение памяти между shared_buffers, work_mem и другими параметрами
Особенности паттерна доступа к данным (работа с огромными наборами данных, которые не помещаются в кэш)
Рекомендации:
- Увеличить RAM минимум до 16GB - текущие 7.5GB явно недостаточны
- Оптимизировать настройки памяти PostgreSQL:
Настроить shared_buffers
Проверить и ограничить work_mem и maintenance_work_mem
Рассмотреть использование huge_pages для снижения накладных расходов
Итог: Проблема с памятью является системной и критической, и она не решается настройкой checkpoint_timeout.
4. Анализ нагрузки на CPU и блокировок (LWLock)
4.1. Корреляция LWLock с user time и system time
Анализ:
- LWLock-us (корреляция с user time):
Наименьшая при 15 мин (0.7858), но всё равно ALARM
Наибольшая при 30 мин (0.8640) - ухудшение
Вывод: Блокировки LWLock сильно связаны с временем выполнения пользовательских процессов при любом checkpoint_timeout - LWLock-sy (корреляция с system time):
Значительное улучшение при 15 мин: снижение с ALARM (0.7721) до INFO (0.4114)
Ухудшение при 30 мин до WARNING (0.6755), но лучше чем при 1 мин
Вывод: Увеличение checkpoint_timeout до 15 мин уменьшает нагрузку блокировок на ядро системы
4.2. Количество процессов в run queue (r)
Анализ:
- Наилучший результат при 15 мин (0.0000%) - никогда не превышает количество ядер
- При 1 мин процессы чаще ждут в очереди на выполнение (7.6271%)
- При 30 мин небольшое ухудшение (2.7273%), но всё равно OK
- Вывод: Checkpoint_timeout=15 мин обеспечивает наиболее сбалансированную загрузку CPU
4.3. Доля system time (sy)
- Во всех экспериментах system time не превышает критический порог 30%
- Это указывает, что ядро системы не перегружено системными вызовами
- Вывод: Проблемы производительности связаны не с системными вызовами, а с другими факторами (IO, блокировки)
4.4. Корреляция переключений контекста (cs)
Анализ:
- При 1 мин: Слабая положительная корреляция - переключения контекста связаны с активностью системы
- При 15 и 30 мин: Отрицательная корреляция - чем больше переключений контекста, тем меньше времени тратится на полезную работу
- Особенно сильная отрицательная корреляция при 30 мин - указывает на неэффективное планирование и чрезмерные накладные расходы на переключение контекста
Общий анализ влияния checkpoint_timeout на CPU и конкуренцию за ресурсы
Оптимальное значение: checkpoint_timeout='15min'
Преимущества:
- Наименьшая очередь процессов (0.0000% превышения) - оптимальное планирование
- Наименьшая нагрузка блокировок на ядро (LWLock-sy = 0.4114, INFO)
- Сбалансированные переключения контекста (умеренная отрицательная корреляция)
Худшее значение: checkpoint_timeout='1min'
Проблемы:
- Высокая корреляция LWLock с system time (0.7721) - блокировки создают нагрузку на ядро
- Наибольшая очередь процессов (7.6271%) - конкуренция за CPU
- Положительная корреляция переключений контекста - указывает на чрезмерную активность
Промежуточное значение: checkpoint_timeout='30min'
Смешанные результаты:
- Сильно отрицательная корреляция переключений контекста - возможно, чрезмерные накладные расходы
- Высокая корреляция LWLock-us (0.8640) - блокировки сильно влияют на пользовательские процессы
- Лучше чем 1 мин, но хуже чем 15 мин по большинству показателей
Механизм влияния checkpoint_timeout на CPU и конкуренцию
При частых контрольных точках (1 мин):
- Постоянная фоновая активность по записи checkpoint
- Частые блокировки (LWLock) для синхронизации
- Процессы чаще ждут в run queue из-за конкуренции
- Больше времени ядра на обработку блокировок
При оптимальных контрольных точках (15 мин):
- Более редкие, но более объёмные операции записи
- Меньше времени на синхронизацию (снижение LWLock-sy)
- Более предсказуемая нагрузка на CPU
- Лучшее планирование процессов
При слишком редких контрольных точках (30 мин):
- Накопление большого объёма изменений
- Более длительные периоды блокировок при checkpoint
- Увеличение накладных расходов на переключение контекста
- Меньшая предсказуемость нагрузки
Выводы и рекомендации:
- Оптимальное значение checkpoint_timeout для CPU: 15 минут
- Проблема блокировок (LWLock) сохраняется при всех значениях, но минимальна при 15 мин
- System time не является проблемой - ядро не перегружено
- Основные проблемы CPU связаны с:
Конкуренцией за ресурсы при частых контрольных точках (1 мин)
Чрезмерными накладными расходами при редких контрольных точках (30 мин) - Дополнительные рекомендации:
Рассмотреть увеличение max_connections, если очередь процессов связана с их количеством
Оптимизировать запросы для уменьшения времени блокировок
Рассмотреть настройку autovacuum для уменьшения конкуренции
Итог: Checkpoint_timeout=15 мин обеспечивает наилучший баланс между частотой контрольных точек и нагрузкой на CPU, минимизируя конкуренцию за ресурсы и накладные расходы на синхронизацию.
5. Сводный вывод и рекомендации
📊 Итоговый анализ по всем экспериментам:
🎯 Оптимальное значение: checkpoint_timeout = 15 минут
Обоснование выбора:
- Наилучший баланс между частотой и объёмом контрольных точек
1 мин: слишком часто → постоянная фоновая нагрузка
30 мин: слишком редко → накопление большого объёма изменений
15 мин: оптимальный компромисс - Лучшие показатели по процессам и планированию
0% наблюдений с очередью процессов > числа ядер
Наименьший процент процессов в состоянии uninterruptible sleep - Оптимальная работа с блокировками
Наименьшая корреляция LWLock-sy (0.4114 против 0.7721 при 1 мин)
Приемлемая корреляция LWLock-us (хотя всё равно ALARM) - Наиболее стабильная работа системы
Лучшие показатели по переключениям контекста
Наименьшие накладные расходы на синхронизацию
⚠️ Критические системные проблемы, не решаемые checkpoint_timeout:
1. Проблема с памятью (7.5 GB недостаточно)
- Текущее состояние: 100% наблюдений с <5% свободной RAM
- Рекомендация: Увеличить RAM минимум до 16 GB
- Почему: Кэш использует >93% памяти, оставляя минимальный запас
2. Проблема с вводом-выводом
- Текущее состояние: 100% наблюдений с wa > 10%
- Рекомендация:
Использовать SSD вместо HDD
Оптимизировать настройки файловой системы
Рассмотреть RAID 10 для увеличения производительности
🛠️ Дополнительные меры для улучшения производительности:
1. Настройки PostgreSQL для памяти:
-- Текущая RAM: 7.5 GB → при увеличении до 16 GB
shared_buffers = 4GB -- 25% от 16GB
work_mem = 16MB -- для 8 CPU, 100 соединений
maintenance_work_mem = 1GB
effective_cache_size = 12GB -- 75% от 16GB
2. Оптимизация контрольных точек (в дополнение к checkpoint_timeout=15min):
checkpoint_completion_target = 0.9 -- Более плавная запись
max_wal_size = 8GB -- Соответствует 15 мин
min_wal_size = 2GB
wal_buffers = 16MB
3. Оптимизация ввода-вывода:
random_page_cost = 1.1 -- Если используете SSD
effective_io_concurrency = 200 -- Для SSD
wal_compression = on -- Снижение нагрузки на WAL
4. Оптимизация блокировок и параллелизма:
max_connections = 100 -- Учитывая нагрузку
max_worker_processes = 8 -- По числу CPU
max_parallel_workers_per_gather = 4
max_parallel_workers = 8
5. Аппаратные улучшения:
- RAM: 16 GB минимум, лучше 32 GB
- Диски: NVMe SSD для WAL (vdc) и данных (vdd)
- CPU: Текущие 8 ядер адекватны, но можно рассмотреть увеличение частоты
6. Операционные улучшения:
# Настройки файловой системы для PostgreSQL
noatime,nodiratime,data=writeback,barrier=0
# Настройки ядра Linux
vm.swappiness = 1
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
Ключевой вывод: checkpoint_timeout = 15min — оптимальное значение в текущих условиях, но оно лишь смягчает симптомы, не решая системные проблемы с памятью и IO. Требуются комплексные изменения в инфраструктуре.
Подробный анализ VMSTAT
1.Общий сравнительный анализ vmstat для трёх экспериментов
Инфраструктура:
- CPU: 8 ядер
- RAM: 7.5 GB
- Диски: отдельные для /wal (vdc) и /data (vdd)
Сравнение по аспектам:
1.1. Нагрузка (LOAD)
Максимальная нагрузка одинакова во всех экспериментах, достигает 22.Скорость роста нагрузки схожа, независимо от параметра checkpoint_timeout.
1.2. Использование CPU
- cpu_wa (ожидание I/O): Наиболее критичный показатель. Все эксперименты показывают высокое время ожидания I/O (до 32%), что указывает на I/O-бутылочное горлышко.
- cpu_us: Наивысшее в Эксперименте-2 (15 мин) - до 72%.
- cpu_sy: Стабильно низкое во всех экспериментах (5-7%).
- cpu_id: Минимальное значение достигает 1% в Экспериментах-2 и -3, что говорит о высокой загрузке CPU.
1.3. Память
Анализ:
- swpd: Увеличивается с ростом checkpoint_timeout (207 → 215 → 221 MB). Эксперимент-1 использует меньше свопа, что лучше.
- free: Эксперимент-1 имеет больше свободной памяти (160-221 MB vs 129-143 MB в Эксперименте-2).
- buff/cache: Кеш памяти высокий (~7GB) во всех экспериментах, что нормально для СУБД.
1.4. Ввод-вывод (I/O)
Важные наблюдения:
- io_bo (вывод): Эксперимент-1 имеет максимальные значения записи (до 41375), что объясняется частыми checkpoint.
- io_bi (ввод): Также максимален в Эксперименте-1.
- С увеличением checkpoint_timeout общий объем I/O снижается, но всплески могут быть более интенсивными.
1.5. Системная активность
Ключевые выводы:
Влияние checkpoint_timeout:
- Пиковая нагрузка и стабильность:
Эксперимент-1 (1 мин) показывает лучшую стабильность памяти (меньше свопа, больше свободной памяти)
Эксперимент-3 (30 мин) имеет наименьшие пики I/O, но более высокое использование свопа - Использование CPU и I/O:
Более частые checkpoint (1 мин):
Выше общий объем I/O операций
Ниже пиковое использование CPU (69% vs 72% в других экспериментах)
Более стабильное время ожидания I/O
Более редкие checkpoint (15-30 мин):
Меньше общий I/O трафик
Выше пиковое использование CPU
Более высокое время ожидания I/O в пиках (до 32%) - Паттерны использования памяти:
С увеличением checkpoint_timeout:
Увеличивается использование свопа (207 → 221 MB)
Уменьшается свободная память
Память кеша остается стабильно высокой (~7GB)
Более частые checkpoint помогают поддерживать более стабильное состояние памяти - Балансировка нагрузки:
При checkpoint_timeout=1 мин нагрузка на I/O распределяется более равномерно
При checkpoint_timeout=15-30 мин наблюдаются более выраженные пики I/O активности
Рекомендации:
Для данной конфигурации (8 CPU, 7.5 GB RAM):
- Оптимальный checkpoint_timeout: 15 минут
Компромисс между производительностью и стабильностью
Приемлемый уровень I/O операций
Умеренное использование памяти - Альтернативные варианты:
checkpoint_timeout=1 мин: Если критична стабильность памяти и равномерная нагрузка на I/O
checkpoint_timeout=30 мин: Если нужно минимизировать общий объем I/O операций, готовы к пиковым нагрузкам на память - Дополнительные рекомендации:
Увеличить RAM: Текущие 7.5 GB недостаточны для оптимальной работы, особенно при редких checkpoint
Настроить shared_buffers: Рекомендуется 25% от RAM (~1.9 GB для данной конфигурации)
Рассмотреть использование SSD: Высокое cpu_wa (до 32%) указывает на ограничения дискового I/O
Настроить checkpoint_completion_target: Рекомендуется 0.9 для более плавной записи checkpoint
Краткий итог:
- Для стабильности и предсказуемости: checkpoint_timeout = 1 мин
- Для баланса производительности/стабильности: checkpoint_timeout = 15 мин
- Для минимизации общего I/O: checkpoint_timeout = 30 мин (при достаточном объеме RAM)
Наиболее сбалансированный вариант для текущей конфигурации - 15 минут, но с рекомендацией увеличения объема оперативной памяти для лучшей производительности при любом значении checkpoint_timeout.
2.Анализ временных рядов и выявление паттернов
2.1.Ключевые метрики
cpu_wa (время ожидания I/O):
- Эксперимент-1 (1 мин):
Старт: 30-31%
Средняя часть: 26-30% с колебаниями
Конец: 18-20%
Характер: Более равномерные колебания без резких пиков - Эксперимент-2 (15 мин):
Старт: 31%
Средняя часть: 26-29% с небольшими снижениями
Конец: 16-18%
Характер: Более выраженные пики в середине (до 32%) - Эксперимент-3 (30 мин):
Старт: 30%
Средняя часть: 27-30%
Конец: 14-16%
Характер: Наиболее изменчивый график с самыми низкими конечными значениями
io_bi / io_bo (активность диска):
- io_bi (ввод):
Эксперимент-1: 27180 → 42399 (постоянный рост с колебаниями)
Эксперимент-2: 29357 → 39301 (более плавный рост)
Эксперимент-3: 28569 → 35541 (самый плавный рост) - io_bo (вывод):
Эксперимент-1: 32676 → 41375 (частые колебания)
Эксперимент-2: 26129 → 31772 (менее частые, но более амплитудные колебания)
Эксперимент-3: 25445 → 32555 (редкие, но самые амплитудные колебания)
memory_free (свободная память):
- Эксперимент-1: 194MB → 160MB (постепенное снижение с небольшими подъемами)
- Эксперимент-2: 143MB → 138MB (более стабильный, но на более низком уровне)
- Эксперимент-3: 136MB → 162MB → 136MB (самая изменчивая динамика)
2.2. Периоды пиковой нагрузки и корреляции:
Все эксперименты показывают пиковую нагрузку (LOAD=22) в период:
- Эксперимент-1: 12:53 - 13:11 (18 минут)
- Эксперимент-2: 15:54 - 16:04 (10 минут)
- Эксперимент-3: 18:46 - 18:56 (10 минут)
Корреляции в пиковый период:
С procs_b (процессы в состоянии ожидания):
- Эксперимент-1: procs_b растет с 11 до 19
- Эксперимент-2: procs_b растет с 19 до 22
- Эксперимент-3: procs_b растет с 18 до 22
- Вывод: Чем больше checkpoint_timeout, тем больше процессов в состоянии ожидания в пиковый период.
С cpu_wa (время ожидания I/O):
- Эксперимент-1: cpu_wa снижается с 29% до 18%
- Эксперимент-2: cpu_wa снижается с 26% до 16%
- Эксперимент-3: cpu_wa снижается с 27% до 14%
- Парадокс: Во время пиковой нагрузки cpu_wa не растет, а снижается! Это говорит о том, что система в этот период уже не успевает обрабатывать I/O запросы так интенсивно.
С memory_free (свободная память):
- Эксперимент-1: memory_free падает с 184MB до 160MB
- Эксперимент-2: memory_free стабильна на уровне 138MB
- Эксперимент-3: memory_free падает с 161MB до 136MB
- Вывод: Наиболее стабильное использование памяти в Эксперименте-2.
2.3. Изменение поведения системы при увеличении checkpoint_timeout:
Частота и амплитуда всплесков I/O:
- checkpoint_timeout=1 мин: Частые, низкоамплитудные всплески io_bo (каждые 1-5 минут, амплитуда 3-5 тыс.)
- checkpoint_timeout=15 мин: Более редкие (каждые 10-15 минут), но более амплитудные всплески (амплитуда 5-8 тыс.)
- checkpoint_timeout=30 мин: Самые редкие (каждые 20-30 минут) и самые амплитудные всплески (амплитуда 8-10 тыс.)
Стабильность использования CPU:
- cpu_us (пользовательское время):
Эксперимент-1: 46-69% (разброс 23%)
Эксперимент-2: 46-72% (разброс 26%)
Эксперимент-3: 47-70% (разброс 23%)
Наиболее стабильный: Эксперимент-1 - cpu_sy (системное время):
Все эксперименты: 5-7% (минимальный разброс)
Стабильность одинаковая
Динамика использования кеша и буферов:
- memory_cache:
Эксперимент-1: 7032-7156 MB (разброс 124 MB)
Эксперимент-2: 7066-7209 MB (разброс 143 MB)
Эксперимент-3: 7047-7186 MB (разброс 139 MB)
Наиболее стабильный кеш: Эксперимент-1 - memory_buff:
Эксперимент-1: 6-37 MB (большой разброс)
Эксперимент-2: 3-4 MB (очень стабильный)
Эксперимент-3: 3-32 MB (большой разброс)
Наиболее стабильные буферы: Эксперимент-2
2.4. Ответы на вопросы:
При каком checkpoint_timeout система демонстрирует наименьшую латентность I/O?
- Наименьший средний cpu_wa:
Эксперимент-1: ~26%
Эксперимент-2: ~24%
Эксперимент-3: ~22% - Наименьшие пиковые значения cpu_wa:
Эксперимент-1: 31%
Эксперимент-2: 32%
Эксперимент-3: 32% - Вывод: Эксперимент-3 (30 мин) показывает наименьшую среднюю латентность I/O, но все эксперименты имеют схожие пиковые значения.
Когда наблюдается наибольшая утилизация CPU в пользовательском режиме?
- Максимальные значения cpu_us:
Эксперимент-1: 69% (в конце теста)
Эксперимент-2: 72% (в конце теста)
Эксперимент-3: 70% (в конце теста) - Средние значения cpu_us:
Эксперимент-1: ~57%
Эксперимент-2: ~59%
Эксперимент-3: ~58% - Вывод: Эксперимент-2 (15 мин) показывает наибольшую пиковую и среднюю утилизацию CPU в пользовательском режиме.
Как влияет увеличение checkpoint_timeout на общую стабильность нагрузки?
- Стабильность LOAD: Все эксперименты показывают схожий рост LOAD, но:
Эксперимент-1: Более плавный рост
Эксперимент-3: Более ступенчатый рост - Стабильность памяти:
Эксперимент-1: Наиболее стабильный memory_cache
Эксперимент-2: Наиболее стабильный memory_buff и memory_free - Стабильность I/O:
Эксперимент-1: Более частые, но менее амплитудные всплески
Эксперимент-3: Более редкие, но более амплитудные всплески - Общая оценка стабильности:
Наиболее стабильная система: Эксперимент-2 (15 мин) - баланс между стабильностью памяти, CPU и I/O
Наименее предсказуемая: Эксперимент-3 (30 мин) - самые резкие изменения в метриках
Ключевой вывод:
Оптимальный баланс между производительностью и стабильностью достигается при checkpoint_timeout = 15 минут.
Эта конфигурация показывает:
- Достаточно низкую латентность I/O
- Высокую утилизацию CPU
- Наибольшую стабильность использования памяти
- Умеренные всплески I/O активности
3.Сводка по производительности и рекомендации
3.1. Сравнительная таблица по экспериментам:
Выводы:
1. Как checkpoint_timeout влияет на:
а) Частоту записи на диск:
- 1 мин: Частые записи (каждые 1-5 мин), небольшие объемы данных за раз
- 15 мин: Умеренная частота (10-15 мин), средние объемы данных
- 30 мин: Редкие записи (20-30 мин), большие объемы данных за раз
б) Использование CPU:
- Пользовательское время (cpu_us): Наивысшее при 15 мин (72%), среднее при 1 мин (69%)
- Системное время (cpu_sy): Стабильно 5-7% во всех экспериментах
- Время ожидания I/O (cpu_wa): Все высокие (до 32%), но средняя латентность снижается с увеличением timeout
в) Общую стабильность системы:
- LOAD: Схожий рост во всех экспериментах, достигают одинакового максимума
- Память: Наиболее стабильная при 1 мин, наименее стабильная при 30 мин
- I/O: Более предсказуемые паттерны при 1 мин, более "рваные" при 30 мин
3.2. Рекомендации:
а) Оптимальный checkpoint_timeout для данной конфигурации:
- Рекомендуется: 15 минут
- Причины:
Баланс между стабильностью памяти и производительностью
Умеренные всплески I/O
Высокая утилизация CPU без экстремальных пиков
Наиболее стабильные буферы памяти (memory_buff)
б) Дополнительные параметры для улучшения производительности:
- Увеличить RAM: Текущие 7.5 GB недостаточны (используется своп до 221 MB)
- Настроить shared_buffers: Рекомендуется 25% от RAM (~1.9 GB)
- Установить checkpoint_completion_target = 0.9: Для более плавного завершения checkpoint
- Рассмотреть SSD для WAL: Высокое cpu_wa (до 32%) указывает на медленные диски
- Настроить wal_buffers = 16MB: Для улучшения производительности WAL
в) Признаки нехватки ресурсов:
- Нехватка памяти: Использование свопа во всех экспериментах (81-221 MB), минимальная свободная память 129 MB
- Дисковая перегрузка: Высокое cpu_wa (до 32%), частые всплески io_bo
- Ограничения CPU: cpu_id падает до 1-2% в пиках, система полностью загружена
Итоговые рекомендации:
- Немедленные действия: Увеличить объем RAM с 7.5 GB до минимум 16 GB
- Оптимальная настройка: checkpoint_timeout = 15 min
- Дополнительная настройка:
shared_buffers = 4GB (после увеличения RAM)
checkpoint_completion_target = 0.9
wal_buffers = 16MB - Аппаратные улучшения: Рассмотреть переход на SSD для дисков WAL и данных
Система демонстрирует признаки ограничений по памяти и дисковому I/O, что делает любую настройку checkpoint_timeout субоптимальной без решения этих фундаментальных проблем.