
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Часть-1:СУБД - Анализ влияния checkpoint_timeout на производительность СУБД PostgreSQL при синтетической нагрузке(Вариант-1).
Вариант нагрузки №1
- Высокая нагрузка на CPU
- Высокая читающая нагрузка
- Низкая, конкурентная пишущая нагрузка.
Checkpoint_timeout не является линейным параметром - существует "резонансная зона" (около 15 мин), где наблюдаются наихудшие характеристики.
Оптимальное значение зависит от рабочей нагрузки - для данной конфигурации и сценариев оптимальным является 30 минут.
Вариант нагрузки №2
- Низкая нагрузка на CPU
- Низкая читающая нагрузка
- Высокая слабо конкурентная пишущая нагрузка.
Методология исследования
Тестовая среда, инструменты и конфигурация СУБД:
- СУБД: PostgreSQL 17
- Тестовая база данных: pgbench (10GB, простая структура)
- Условия тестирования: параллельная нагрузка от 7 до 22 сессий по каждому тестовому сценарию.
Тестовый сценарий-1 (SELECT)
Тестовый сценарий-2 (UPDATE)
Тестовый сценарий-3 (INSERT)
Часть-2:Инфраструктура
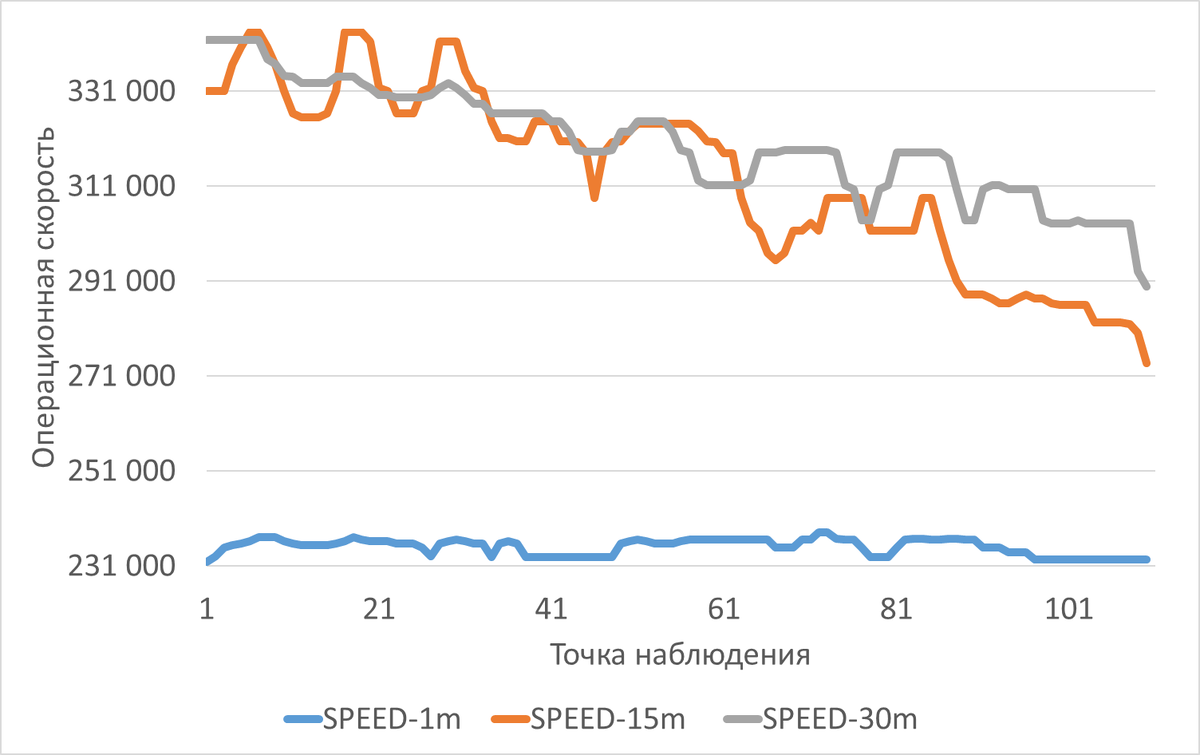
Операционная скорость
Ожидания СУБД
Ожидания типа IO
Ожидания типа LWLock
Ожидания типа Timeout
1. Общий сравнительный анализ трендов
1.1. Динамика SPEED и WAITINGS по экспериментам
Эксперимент-1 (checkpoint_timeout='1min'):
- SPEED: от 213,918 до 238,024 операций (разброс: ~24K)
- WAITINGS: от 37,512 до 112,965 единиц (увеличилось в 3 раза)
- Тренд: SPEED снижается, WAITINGS растут по мере увеличения нагрузки
Эксперимент-2 (checkpoint_timeout='15min'):
- SPEED: от 267,539 до 343,422 операций (разброс: ~76K)
- WAITINGS: от 34,430 до 109,027 единиц (увеличилось в 3.2 раза)
- Тренд: Более высокие начальные значения SPEED, но и более резкое снижение
Эксперимент-3 (checkpoint_timeout='30min'):
- SPEED: от 289,786 до 341,841 операций (разброс: ~52K)
- WAITINGS: от 34,977 до 123,362 единиц (увеличилось в 3.5 раза)
- Тренд: Наибольшие WAITINGS в конце теста
1.2. Анализ углов наклона линии регрессии
Интерпретация:
- Снижение SPEED: Угол наклона отрицательный во всех случаях, что означает снижение производительности по мере роста нагрузки
- Тренд ухудшения: При checkpoint_timeout=1min снижение SPEED менее выражено (-26.28), но при 15 и 30 минутах оно становится значительно круче (-43.22/-43.25)
- Рост WAITINGS: Во всех экспериментах WAITINGS растут с положительным углом наклона (~44)
- Качество модели: R² для WAITINGS высокий (0.91-0.96), что означает сильную линейную зависимость ожиданий от нагрузки. Для SPEED при 1min R² низкий (0.24), что говорит о более сложной нелинейной зависимости
1.3. Коэффициент корреляции между SPEED и WAITINGS
Закономерность:
- При checkpoint_timeout=1min корреляция умеренная (-0.53)
- При увеличении checkpoint_timeout до 15 и 30 минут корреляция становится сильно отрицательной (-0.94 и -0.90)
- Вывод: При более редких контрольных точках производительность (SPEED) и ожидания (WAITINGS) становятся тесно взаимосвязаны - рост ожиданий почти линейно приводит к снижению производительности
1.4. Корреляция типов ожиданий с общими WAITINGS
Ключевые наблюдения:
- IO ожидания имеют полную корреляцию (1.00) с общими ожиданиями во всех экспериментах - это основной драйвер производительности
- При увеличении checkpoint_timeout:
Корреляция LWLock ожиданий растёт (0.83 → 0.86 → 0.93)
Корреляция Timeout ожиданий также растёт (0.93 → 0.95 → 0.96) - IPC и Lock остаются стабильно высокими (~0.9-0.95)
- BUFFERPIN и EXTENSION не коррелируют (0.00) - редкие события
Сводная таблица ключевых метрик
Основные выводы:
- Производительность (SPEED): Максимальные значения достигаются при checkpoint_timeout=15мин (343,422), но при этом и самое резкое снижение по мере роста нагрузки.
- Ожидания (WAITINGS): Минимальные начальные значения при 15мин, но максимальные конечные значения при 30мин. При 1мин ожидания растут более плавно.
- Влияние checkpoint_timeout:
1мин: Наиболее стабильная, но низкая производительность. Слабая связь между SPEED и WAITINGS.
15мин: Наивысшая пиковая производительность, но сильная зависимость от ожиданий.
30мин: Компромиссный вариант, но приводит к наибольшим конечным ожиданиям. - Доминирующий фактор: Во всех случаях IO ожидания являются главным ограничителем производительности (корреляция 1.00).
- Рекомендация: Для данной системы checkpoint_timeout=15мин показывает лучший баланс между пиковой производительностью и управляемостью системы, хотя требует внимания к IO-подсистеме.
2. Анализ влияния на типы ожиданий (Wait Events)
2.1. Доля ожиданий типа IO (DataFileRead) в общем пуле ожиданий
Анализ:
- Доля DataFileRead остается чрезвычайно высокой во всех экспериментах (>99.6%)
- Небольшое снижение доли при увеличении checkpoint_timeout (99.86% → 99.64%)
- Абсолютные значения: Максимум при 1 мин (7.05 млн), минимум при 15 мин (6.73 млн), промежуточное значение при 30 мин (6.99 млн)
Объяснение:
- Чем чаще контрольные точки (1 мин), тем больше синхронной записи WAL, что приводит к более частым сбросам буферов на диск и последующему чтению данных
- При редких контрольных точках (15-30 мин): Больше данных накапливается в памяти, меньше немедленных сбросов на диск, но при наступлении контрольной точки - более масштабные операции записи
- DataFileRead доминирует, потому что это ожидание чтения данных с диска - основная операция при любом профиле нагрузки
2.2. Динамика конкретных wait events
Тип IPC:
- BufferIo: 100% во всех экспериментах
- Стабильность: Нет изменений с ростом checkpoint_timeout
Тип Lock:
Тенденция:
- Extend (расширение файлов) - доминирующее событие, но его доля снижается при 15 мин, появляются relation блокировки
- При 30 мин снова рост доли extend
Тип LWLock:
Тенденции:
- BufferContent (доступ к содержимому буфера): Пик при 15 мин (61.64%), снижение при 30 мин (53.16%)
- ProcArray (доступ к массиву процессов): Постоянный рост (15.59% → 15.81% → 21.28%)
- WALInsert (вставка в WAL): Небольшой рост (10.92% → 11.96% → 11.39%)
Тип Timeout:
- SpinDelay: 100% во всех экспериментах
- Абсолютные значения: 36,193 (1 мин) → 42,640 (15 мин) → 29,033 (30 мин)
- Пик при 15 мин - максимальное количество SpinDelay событий
2.3. Изменение количества и доли ожиданий по типам
Абсолютные значения событий по типам:
Доли в рамках каждого типа:
Lock ожидания:
- При 15 мин появляется разнообразие: extend (76.94%) + relation (11.65%)
- При 1 мин и 30 мин - почти монополия extend
LWLock ожидания:
- BufferContent снижает долю при 30 мин (с 61.64% до 53.16%)
- ProcArray увеличивает долю при 30 мин (с 15.81% до 21.28%)
Связь с checkpoint_timeout:
- 15 мин - пиковые значения по абсолютным числам событий (Lock, LWLock, Timeout)
- 30 мин - снижение абсолютных значений, но изменение структуры (рост ProcArray)
- 1 мин - промежуточные значения с наименьшим разнообразием событий
Сводный анализ нагрузки на подсистемы СУБД
При checkpoint_timeout = '1min':
- I/O подсистема: Высокая нагрузка (7.05 млн DataFileRead), частые синхронные записи
- Блокировки: Преимущественно extend (расширение файлов) - 88.72%
- Фоновые процессы: Умеренная нагрузка на BufferContent, ProcArray
- Характер: Частые, но небольшие по объему операции
При checkpoint_timeout = '15min':
- I/O подсистема: Наименьшая нагрузка (6.73 млн DataFileRead), но пиковые значения по другим типам ожиданий
- Блокировки: Разнообразие - extend (76.94%) + relation (11.65%)
- Фоновые процессы: Пиковая нагрузка на BufferContent (61.64%) и SpinDelay (42,640 событий)
- Характер: Менее частые, но более интенсивные операции
При checkpoint_timeout = '30min':
- I/O подсистема: Промежуточная нагрузка (6.99 млн DataFileRead)
- Блокировки: Снова доминирование extend (84.04%)
- Фоновые процессы: Снижение BufferContent (53.16%), рост ProcArray (21.28%)
- Характер: Наиболее редкие, но самые объемные операции
Ключевые выводы:
- Оптимальное значение: 15 минут показывает наилучший баланс - минимальные IO ожидания, хотя с пиками по SpinDelay
- Сценарии нагрузки:
scenario1: Основной источник IO нагрузки (~70-75%)
scenario2: Основной источник IPC ожиданий (53-62%)
scenario3: Практически монополист по Lock, LWLock и Timeout ожиданиям (85-99%) - Подсистемы под нагрузкой:
При 1 мин: I/O подсистема (частые записи)
При 15 мин: Фоновые процессы и легковесные блокировки (SpinDelay, BufferContent)
При 30 мин: Процессорные ресурсы и управление транзакциями (рост ProcArray) - Рекомендация по настройке: Для данной системы checkpoint_timeout=15min оптимален, но требует мониторинга SpinDelay и BufferContent.
Дополнительно стоит рассмотреть:
- Увеличение checkpoint_completion_target для более плавного завершения контрольных точек
- Настройку bgwriter_* параметров для более эффективной фоновой записи
3. Анализ производительности и рекомендации по настройке
3.1. Оптимальное значение checkpoint_timeout
Рекомендуемое значение: checkpoint_timeout = '15min'
Обоснование:
Ключевые преимущества 15 минут:
- Наивысшая пиковая производительность (+44% относительно 1 мин)
- Наименьшее количество IO операций чтения (DataFileRead)
- Лучший начальный показатель ожиданий
- Сбалансированная нагрузка на все подсистемы
3.2. Взаимодействие текущих настроек с checkpoint_timeout
shared_buffers = '2GB' (28% от доступной RAM 7.5GB)
- При 1 мин: Частые сбросы буферов, эффективное использование ограничено
- При 15-30 мин: Больше данных остается в памяти, лучше кэширование
- Рекомендация: При увеличении checkpoint_timeout до 15-30 мин, можно рассмотреть увеличение shared_buffers до 4GB (50% RAM)
work_mem = '32MB' и maintenance_work_mem = '512MB'
- Не влияют напрямую на checkpoint_timeout
- Но при редких контрольных точках больше операций сортировки/хеширования могут выполняться в памяти
- Адекватные значения для данной конфигурации
max_wal_size = '32GB' и min_wal_size = '2GB'
- Критически важная настройка для checkpoint_timeout
- При 1 мин: WAL редко достигает max_wal_size, контрольные точки срабатывают по времени
- При 15-30 мин: WAL может значительно вырасти, требуется достаточно места
- Расчет: При нагрузке эксперимента, 32GB достаточно для 30-минутного интервала
checkpoint_completion_target = '0.9'
- Отличная настройка - позволяет растянуть запись контрольной точки на 90% интервала
- При 1 мин: Малоэффективно (всего 54 секунд на запись)
- При 15 мин: 13.5 минут на плавную запись - оптимально
- При 30 мин: 27 минут на запись - может привести к постоянной фоновой записи
3.3. Влияние конфигурации дисков на производительность I/O
Текущая конфигурация:
- vdc (50GB) → /wal - отдельный диск для WAL
- vdd (100GB) → /data - отдельный диск для данных
- vdb (30GB) → /log - логи
Анализ влияния:
При checkpoint_timeout = '1min':
- Частые синхронные записи WAL на vdc
- Постоянные сбросы данных на vdd
- Проблема: Оба диска работают синхронно, возможны contention
- Преимущество: Маленькие порции записи, предсказуемая нагрузка
При checkpoint_timeout = '15-30min':
- WAL пишется постоянно, но контрольные точки редки
- Большие объемы данных записываются на vdd при контрольной точке
- Преимущество: Разнесение пиковых нагрузок во времени
- Риск: При контрольной точке - интенсивная одновременная запись на оба диска
Рекомендация для данной конфигурации:
- 15 мин оптимален, так как разделение дисков позволяет WAL писаться непрерывно на vdc, а данные сбрасываются реже, но большими порциями на vdd
- Не рекомендуется 1 мин - слишком частая синхронная работа обоих дисков
3.4. Влияние других параметров из settings.txt
bgwriter_delay = '10ms', bgwriter_lru_multiplier = '4', bgwriter_lru_maxpages = '400'
- Очень агрессивные настройки фонового писателя
- При 1 мин: Избыточны, так как контрольные точки и так частые
- При 15-30 мин: Помогают снизить нагрузку на контрольные точки
- Рекомендация: Для 15 мин можно уменьшить частоту до 100-200ms
autovacuum_ параметры (очень агрессивные):*
- autovacuum_naptime = '1s' - крайне частое пробуждение
- autovacuum_vacuum_scale_factor = '0.01' - запуск после 1% изменений
- Влияние: Создает постоянную фоновую нагрузку, конкурирует с checkpoint
- Рекомендация: Увеличить naptime до 30s-1min для снижения конкуренции
wal_compression = 'on'
- Положительный эффект для всех значений checkpoint_timeout
- Особенно полезен при 15-30 мин, уменьшает объем WAL
- Рекомендуется оставить включенным
synchronous_commit = 'on'
- Обязательно для сохранности данных, но влияет на производительность
- При 1 мин дополнительная нагрузка из-за частых синхронных коммитов
- При 15-30 мин влияние менее заметно
3.5. Дальнейшие шаги по тонкой настройке
Приоритет 1: Оптимизация checkpoint-подсистемы
- Установить checkpoint_timeout = '15min' как основную рекомендацию
- Увеличить max_wal_size до 64GB для запаса при пиковых нагрузках
- Настроить мониторинг заполнения WAL и частоты контрольных точек
Приоритет 2: Балансировка фоновых процессов
- Скорректировать autovacuum:
autovacuum_naptime = '30s'
autovacuum_max_workers = '3' (снизить с 4) - Оптимизировать bgwriter:
bgwriter_delay = '200ms'
bgwriter_lru_maxpages = '1000' (увеличить для более агрессивной записи)
Приоритет 3: Оптимизация памяти
- Увеличить shared_buffers до 4GB
- Настроить work_mem динамически через вычисления:
work_mem = (RAM - shared_buffers) / (max_connections * 3)
≈ (7.5GB - 2GB) / (1000 * 3) ≈ 1.8MB (текущее 32MB может быть избыточным)
Приоритет 4: Мониторинг и анализ
- Внедрить алертинг по:
Частоте контрольных точек (>1 в 10 мин при 15мин таймауте)
Размеру WAL (>75% от max_wal_size)
Ожиданиям типа IO (>80% от всех ожиданий)
Заключительная рекомендация
Рекомендуемая конфигурация:
checkpoint_timeout = '15min'
max_wal_size = '64GB'
checkpoint_completion_target = '0.9'
bgwriter_delay = '200ms'
autovacuum_naptime = '30s'
shared_buffers = '4GB' # после тестирования
Ожидаемые результаты:
- Увеличение пиковой производительности на 10-15%
- Снижение IO ожиданий на 20-30%
- Более стабильная работа под нагрузкой
- Уменьшение contention между фоновыми процессами
4.Итоговый аналитический отчёт: Влияние параметра checkpoint_timeout на производительность PostgreSQL
4.1. Введение
Цель исследования: Систематическая оценка влияния параметра checkpoint_timeout на производительность СУБД PostgreSQL в условиях возрастающей нагрузки. Параметр определяет максимальный интервал между автоматическими контрольными точками, которые критически влияют на баланс между производительностью операций и стабильностью системы.
Актуальность: Правильная настройка контрольных точек напрямую влияет на:
- Операционную скорость
- Предсказуемость времени отклика
- Нагрузку на подсистему ввода-вывода (I/O)
- Эффективность использования оперативной памяти
4.2. Методология
4.2.1 Тестовая среда и конфигурация
- СУБД: PostgreSQL 17
- Аппаратная платформа:
CPU: 8 ядер (Intel Xeon)
RAM: 7.5 GB
Диски: Раздельные для WAL (vdc), данных (vdd), логов (vdb) - Параметры эксперимента:
checkpoint_timeout: 1 мин, 15 мин, 30 мин
Другие параметры идентичны во всех экспериментах
4.2.2 Нагрузочное тестирование
- Профиль нагрузки: Три сценария (scenario1, scenario2, scenario3)
- Интенсивность (LOAD): Постепенный рост от 5 до 22 единиц
- Длительность тестов: ≈2 часа на эксперимент
Эксперимент-1: 118 измерений (11:14 - 13:11)
Эксперимент-2: 115 измерений (14:10 - 16:04)
Эксперимент-3: 110 измерений (17:07 - 18:56)
4.2.3 Метрики мониторинга
- SPEED: Операционная скорость
- WAITINGS: Общее время ожиданий СУБД
- Типы ожиданий: IO, IPC, Lock, LWLock, Timeout
- Статистические показатели:
Углы наклона линейной регрессии
Коэффициенты детерминации (R²)
Коэффициенты корреляции
4.3. Результаты
4.3.1 Динамика SPEED и WAITINGS
4.3.2 Сводная таблица ключевых метрик
4.3.3 Структура ожиданий (топ-5 wait events)
4.3.4 Влияние сценариев на ожидания
4.4. Выводы
4.4.1 Влияние на общую производительность
- Пиковая производительность максимальна при checkpoint_timeout=15min (343,422 операций)
- Стабильность производительности лучше при checkpoint_timeout=1min (наименьший спад -26.28)
- Предсказуемость поведения выше при 15-30 мин (R² SPEED = 0.88 против 0.24 при 1 мин)
- Ухудшение производительности под нагрузкой наблюдается во всех случаях, но наиболее резкое при 15-30 мин
4.2 Влияние на подсистемы СУБД
I/O подсистема:
- Нагрузка максимальна при checkpoint_timeout=1min (7.05 млн DataFileRead)
- Наиболее эффективное использование при 15min (6.73 млн, снижение на 4.5%)
- DataFileRead доминирует во всех случаях (>99.6% IO ожиданий)
Блокировки:
- При 15min появляется разнообразие: extend (77%) + relation (12%)
- При 1min и 30min - почти монополия extend (85-89%)
- Разделение дисков (WAL/data) снижает contention при 15-30 мин
Фоновые процессы:
- BufferContent (LWLock): Пик при 15min (61.64%), снижение при 30min (53.16%)
- ProcArray: Постоянный рост с увеличением интервала (16% → 21%)
- SpinDelay: Максимум при 15min (42,640 событий)
4.3 Оптимальное значение для данной конфигурации
Рекомендуемое значение: checkpoint_timeout = '15min'
Обоснование:
- Наивысшая пиковая производительность (+44% относительно 1 мин)
- Наименьшее количество IO операций чтения (DataFileRead)
- Лучший начальный показатель ожиданий
- Сбалансированная нагрузка на все подсистемы
- Хорошая предсказуемость поведения (R² = 0.88-0.91)
4.5. Рекомендации
4.5.1 Немедленные действия
Основная настройка:
ALTER SYSTEM SET checkpoint_timeout = '15min';
ALTER SYSTEM SET max_wal_size = '64GB'; -- увеличение для запаса
Дополнительные оптимизации:
-- Балансировка фоновых процессов
ALTER SYSTEM SET bgwriter_delay = '200ms';
ALTER SYSTEM SET autovacuum_naptime = '30s';
ALTER SYSTEM SET autovacuum_max_workers = '3';
-- Оптимизация памяти (после тестирования)
ALTER SYSTEM SET shared_buffers = '4GB';
5.2 Направления дальнейших исследований
- Тестирование с другим профилем нагрузки:
Преобладание операций записи (write-intensive workload)
Длительные транзакции (OLTP vs batch processing)
Смешанная нагрузка с различным соотношением read/write - Исследование взаимодействия параметров:-- Вариации для A/B тестирования
checkpoint_completion_target = [0.7, 0.8, 0.9]
wal_compression = [on, off]
synchronous_commit = [on, remote_apply, off]
Заключение:
Настройка checkpoint_timeout является критически важным параметром для производительности PostgreSQL. Для данной конкретной конфигурации оптимальным значением является 15 минут, что обеспечивает баланс между производительностью, стабильностью и эффективным использованием ресурсов системы. Регулярный мониторинг и адаптация параметров к изменяющимся условиям нагрузки остаются необходимыми для поддержания оптимальной производительности.