🌟 TurboDiffusion: ускорение генерации видео в 100+ раз.
Суровая реальность нашего времени: вы хотите сгенерировать 5-секундное видео на большой SOTA-модели. Вы запускаете промпт, идете пить кофе, возвращаетесь, а процесс все еще идет. И зачастую генерация может занимать больше часа.
Главные виновники - чудовищная вычислительная сложность механизма внимания в трансформерах, необходимость сотен шагов денойзинга и огромный объем памяти для весов в полной точности.
Авторы проекта TurboDiffusion из Цинхуа и Беркли решили собрать все эффективные методы сжатия и ускорения в один пайплайн. Их идея заключалась в том, что разреженность и квантование — это техники, которые не мешают друг другу.
🟡Архитектура держится на 3-х китах оптимизации:
🟢Заменили стандартное внимание на гибрид из SageAttention2++ и Sparse-Linear Attention (SLA), который превратил квадратичную сложность в линейную. чтобы модель фокусировалась только на важных токенах.
🟢Дистиллировали сэмплинг через rCM - вместо стандартных 50–100 шагов модель приходит к результату всего за 3-4 шага без потери сути изображения.
🟢Перевели и веса и активации линейных слоев в INT8 используя блочное квантование, чтобы не потерять точность.
В довершении ко всему смогли объединить после файнтюнинга под SLA и дистилляции rCM веса в единую модель, избежав конфликтов.
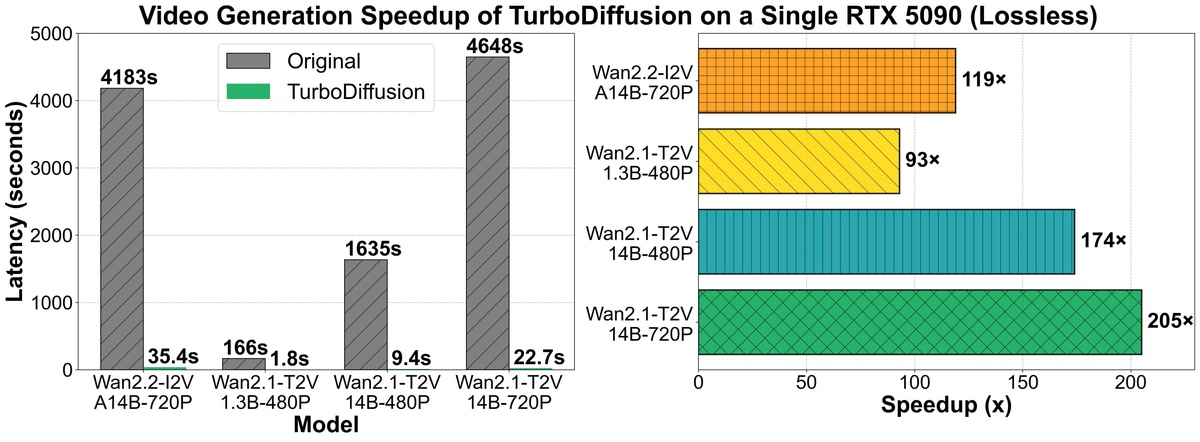
🟡Результаты бенчмарков выглядят как опечатка, но это не она.
На RTX 5090 время генерации для тяжелой модели Wan2.2-I2V 14B упало с 69 минут до 35.4 секунд. А для более легкой Wan 2.1-1.3B - с почти 3-х минут до 1.8 секунды.
Это ускорение больше чем в 100 раз.
При этом, судя по примерам, визуальное качество осталось практически неотличимым от оригинала.
📌Лицензирование: Apache 2.0 License.
#AI #ML #I2V #T2V #TurboDiffusion