Магия, которая стоит за мгновенным входом в соцсети, умной телефонной книгой и быстрым кешем DNS. Как структура данных, придуманная полвека назад, до сих пор остаётся самым популярным инструментом для сверхбыстрого поиска.
Мы с вами уже научились быстро сортировать данные и молниеносно искать в них бинарным поиском. Но представьте: у вас есть массив из 10 миллионов пользователей, и вам нужно за микросекунду проверить, не забанен ли конкретный человек с логином «super_cat_2025». Бинарный поиск потребует около 24 сравнений (log₂(10M)), что быстро, но не мгновенно. А что если нам нужно не просто найти, а моментально получить доступ к целому профилю по его уникальному email? Перебирать 10 миллионов записей — немыслимо. Именно здесь, на сцену выходит герой, который не сортирует и не ищет в привычном смысле, а просто… знает ответ. Он превращает любую сложную сущность (логин, номер паспорта, название города) в адрес ячейки памяти, где лежит нужное значение. Его зовут хеш-таблица. Это не просто структура данных, это философия прямого доступа. Это волшебный переводчик, который на ваш вопрос «Где лежат данные для ключа "super_cat_2025"?» отвечает не «Поищу», а «Сразу в ячейке 42». Сегодня мы разберём, как работает эта магия, что такое хеш-функция — её сердце, почему иногда случаются «аварии» (коллизии) и как инженеры с ними борются. И самое главное — поймём, почему в идеальном случае поиск в хеш-таблице занимает время O(1), то есть не зависит вообще от количества данных. Это уровень, где миллиард записей обрабатывается так же быстро, как и десять.
Всё начинается с простой, но гениальной идеи. Давайте отвлечёмся от компьютеров. Представьте библиотеку с миллионом книг, расставленных просто по порядку поступления. Чтобы найти книгу по её названию, вам придётся пройти весь миллион — O(n). Если книги отсортированы по алфавиту, поможет бинарный поиск за O(log n). Но есть способ лучше.
Представьте, что вы — гениальный библиотекарь. Вы устанавливаете правило: каждая книга ставится на полку, номер которой вычисляется по её названию. Ваше правило (алгоритм) таково: «Возьми название, сосчитай сумму кодов всех букв, раздели на 1000 и возьми остаток». Например, для книги «Война и мир» сумма букв (в условных единицах) равна 1432. Остаток от деления на 1000 — 432. Значит, книга ставится на полку №432. Теперь, когда приходит читатель и спрашивает «Войну и мир», вы не идёте искать. Вы просто применяете своё правило к названию, получаете число 432 и идёте прямиком к полке 432. Это и есть основа хеш-таблицы.
- Ключ (Key): То, по чему мы ищем (название книги, логин пользователя, номер паспорта). Это наша входная строка или объект.
- Значение (Value): Данные, которые мы хотим хранить и быстро находить (сама книга, профиль пользователя, информация о человеке).
- Хеш-функция (Hash Function): Это тот самый алгоритм библиотекаря. Она берёт ключ любой длины и сложности и превращает его в число фиксированного диапазона — хеш (hash). Математически: hash = h(key).
- Хеш-таблица (Hash Table): Массив (обычно), где каждая ячейка (их часто называют «корзиной» или «bucket») имеет индекс. Вычисленный хеш — это и есть индекс в этом массиве, по которому должно храниться значение для данного ключа.
Идеальная картина: для каждого уникального ключа хеш-функция выдаёт уникальный индекс. Кинул в аппарат логин «super_cat_2025» — получил индекс 42. Пошёл к 42-й ячейке массива, а там уже лежит готовый профиль. Поиск, вставка и удаление выполняются за время вычисления хеш-функции (очень быстрое) и одного обращения к массиву по индексу (мгновенное). Это и есть заветное O(1) — постоянное время, не зависящее от n.
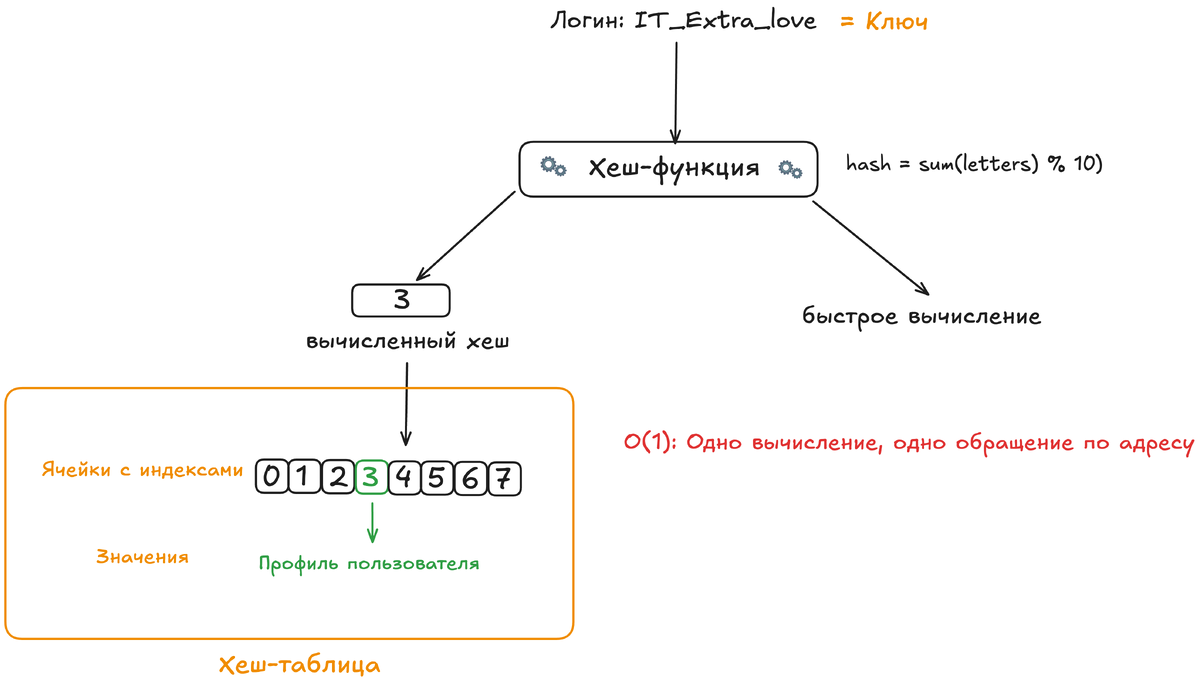
Но в реальном мире на пути к идеалу стоят две большие проблемы. Первая — размер таблицы. Мы не можем иметь бесконечный массив на все возможные ключи. Наша хеш-функция выдаёт число в ограниченном диапазоне (например, остаток от деления на 1000 — значит, диапазон от 0 до 999). А ключей (названий книг) может быть миллион. Из этого следует неизбежная вторая проблема — коллизии.
Коллизия — это ситуация, когда две разные книги по нашему правилу получают один и тот же номер полки. Например, для книг «Код Да Винчи» и «Мастер и Маргарита» наша простенькая хеш-функция могла бы выдать одно число. И вот вы приходите на полку 555, а там уже стоит «Код Да Винчи». Куда деть «Мастера и Маргариту»? Именно то, как хеш-таблица решает коллизии, и определяет её практическую эффективность.
Самый распространённый и наглядный метод — метод цепочек (chaining). Он представляет каждую ячейку (корзину) массива не как место для одного значения, а как начало цепочки (связного списка). Если в ячейку с индексом 555 пришла первая книга, мы создаём там маленький список из одного элемента. Когда приходит вторая книга с тем же хешом 555, мы просто добавляем её в этот же список. Теперь в ячейке 555 висит список из двух пар «ключ-значение».
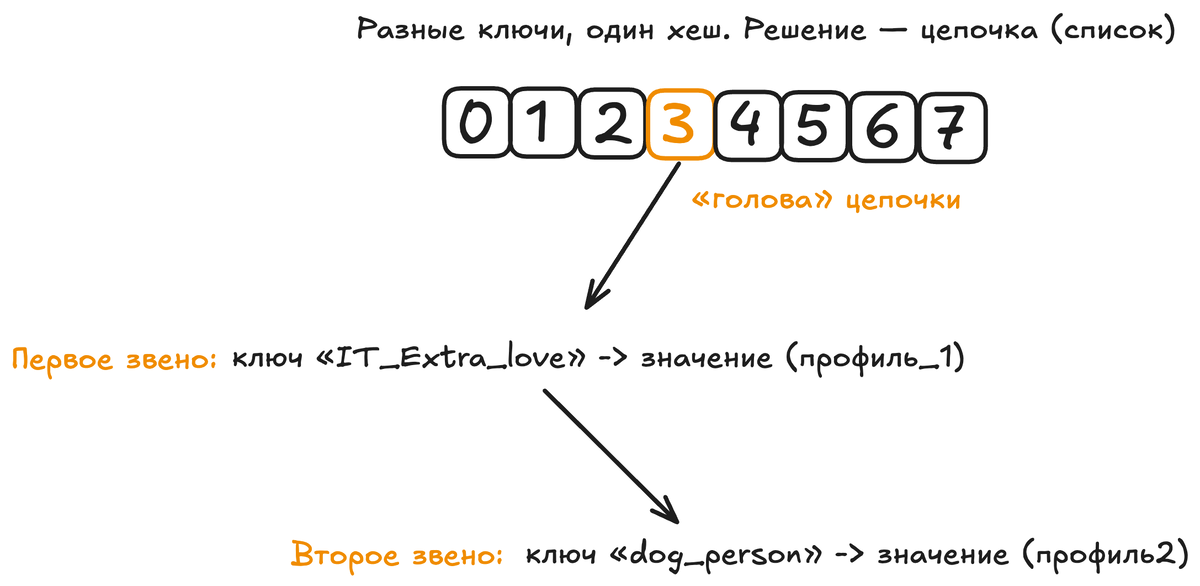
Что происходит при поиске теперь? Вы хотите найти профиль для «dog_person».
- Вычисляете хеш: h("dog_person") = 3.
- Идёте к ячейке 3. Видите, что там не одно значение, а цепочка.
- Проходитесь по этой цепочке и сравниваете ключи: сначала видите «cat_lover» — не то. Переходите к следующему звену, видите «dog_person» — совпало! Берёте связанное значение.
В худшем случае, если все ключи угодили в одну и ту же ячейку (например, хеш-функция очень плохая и для всех ключей возвращает 3), цепочка превратится в список из n элементов. Поиск в таком списке будет O(n). Поэтому качество хеш-таблицы напрямую зависит от двух вещей: качества хеш-функции и коэффициента заполнения.
Хорошая хеш-функция должна:
- Распределять ключи равномерно по всем ячейкам таблицы, минимизируя коллизии. Это как если бы наш библиотекарь придумал такое сложное правило, что книги расставлялись почти случайно, но предсказуемо для него.
- Быстро вычисляться. Иначе выигрыш в поиске пропадёт.
- Быть детерминированной: для одного и того же ключа всегда возвращать один и тот же хеш.
Коэффициент заполнения — это отношение количества хранимых элементов к размеру таблицы (α = n / size). Если таблица маленькая, а элементов много, цепочки будут длинными. Умные реализации хеш-таблиц (как в Java HashMap или Python dict) следят за этим коэффициентом. Когда он превышает порог (часто 0.75), происходит рехеширование: создаётся новая таблица, примерно в 2 раза больше, все существующие элементы заново пропускаются через хеш-функцию (учитывая новый размер) и размещаются в новой таблице. Эта операция дорогая (O(n)), но происходит редко, и в среднем сложность операций остаётся O(1).
Есть и другой популярный метод разрешения коллизий — открытая адресация (линейное или квадратичное пробирование). Его суть в том, что если ячейка занята, алгоритм ищет следующую свободную ячейку по определённому алгоритму (например, проверяет i+1, i+2, i+3…). Но для понимания сути метод цепочек нагляднее.
При хорошей хеш-функции и адекватном размере таблицы, цепочки в каждой ячейке будут очень короткими. В идеально равномерном распределении, если у нас 10 миллионов элементов и таблица на 1 миллион ячеек, в каждой ячейке в среднем будет по 10 элементов (α = 10). Даже в этом случае поиск — это вычисление хеш-функции (O(1)) + проход по короткому списку из ~10 элементов (это тоже константа, O(10) = O(1)). Увеличение данных в 10 раз (до 100 млн) при увеличении таблицы пропорционально (до 10 млн ячеек) сохраняет среднюю длину цепочки на том же уровне (~10). Время поиска не растёт с ростом n, оно зависит только от коэффициента заполнения, который мы поддерживаем константой. Вот суть O(1).
Они везде.
- Ваша телефонная книга в смартфоне: Ключ — имя «Мама», значение — номер телефона. Поиск контакта происходит почти мгновенно, не сортируя все контакты заново.
- Кеш DNS интернета: Превращает понятный человеку адрес «dzen.ru» (ключ) в IP-адрес сервера (значение). Без этой гигантской распределённой хеш-таблицы интернет бы ползал.
- Ассоциативные массивы в языках программирования: dict в Python, HashMap в Java, object в JavaScript — всё это хеш-таблицы под капотом.
- Сеты для проверки уникальности: Например, проверка, не посещал ли алгоритм уже эту вершину графа. Ключ — ID вершины, значение — true. Поиск за O(1) вместо O(n) в списке.
- Кеширование веб-страниц: Ключ — URL страницы, значение — сохранённая HTML-разметка. Позволяет не генерировать страницу заново.
Хеш-таблица — это структура данных, которая обеспечивает практически мгновенный доступ к значению по ключу за счёт хеш-функции. Эта функция выступает «переводчиком», преобразующим любой сложный ключ в числовой индекс — адрес ячейки в массиве. Коллизии (ситуации, когда разным ключам соответствует один индекс) решаются с помощью цепочек или открытой адресации. При поддержании равномерного распределения ключей и оптимального коэффициента заполнения таблицы, средняя сложность операций поиска, вставки и удаления остаётся O(1), то есть постоянной, не зависящей от количества хранимых данных.
Используйте хеш-таблицы, когда ваша основная задача — частый и быстрый поиск, добавление или удаление данных по уникальному ключу. Это идеальный инструмент для кешей, словарей, систем индексации, проверки принадлежности элемента к множеству. Избегайте или подумайте дважды, если:
- Вам критически важен порядок элементов (в классической хеш-таблице его нет).
- Вам нужен быстрый поиск по диапазону ключей (например, найти всех пользователей с фамилией на букву «А»). Здесь эффективнее дерево.
- Память сильно ограничена — хеш-таблица для эффективности требует запас свободных ячеек, что ведёт к избыточному расходу памяти.
- Ключи или хеш-функция плохи и ведут к множественным коллизиям, вырождая поиск в O(n).
Хеш-таблица — это торжество инженерной мысли. Она жертвует строгим порядком и немного памятью ради того, что ценится в современном мире больше всего — скорости. Это тот фундамент, на котором построена мгновенность нашей цифровой жизни. Когда вы в следующий раз за миллисекунду войдёте в приложение, просто помните: где-то внутри сработал волшебный переводчик, превративший ваш логин в адрес памяти. Не искал. Вычислил.
👍 Ставьте лайки если хотите разбор других интересных тем.
👉 Подписывайся на IT Extra на Дзен чтобы не пропустить следующие статьи
Если вам интересно копать глубже, разбирать реальные кейсы и получать знания, которых нет в открытом доступе — вам в IT Extra Premium.
Что внутри?
✅ Закрытые публикации: Детальные руководства, разборы сложных тем (например, архитектура высоконагруженных систем, глубокий анализ уязвимостей, оптимизация кода, полезные инструменты объяснения сложных тем простым и понятным языком).
✅ Конкретные инструкции: Пошаговые мануалы, которые вы сможете применить на практике уже сегодня.
✅ Без рекламы и воды: Только суть, только концентрат полезной информации.
✅ Ранний доступ: Читайте новые материалы первыми.
Это — ваш личный доступ к экспертизе, упакованной в понятный формат. Не просто теория, а инструменты для роста.
👉 Переходите на Premium и начните читать то, о чем другие только догадываются.
👇
Понравилась статья? В нашем Telegram-канале ITextra мы каждый день делимся такими же понятными объяснениями, а также свежими новостями и полезными инструментами. Подписывайтесь, чтобы прокачивать свои IT-знания всего за 2 минуты в день!