Магия «деления пополам», которая превращает поиск иголки в стоге сена из месячной работы в 20 простых вопросов. Разбираем алгоритм, который вы используете, даже не зная его названия.
В прошлый раз мы узнали, что такое алгоритм и познакомились с языком эффективности — нотацией Big O. Сегодня мы возьмём наш первый реальный, мощный и элегантный алгоритм, который в одиночку демонстрирует всю красоту компьютерного мышления. Это бинарный поиск (binary search). Если бы алгоритмы были супергероями, он был бы не самым сильным, но самым умным — тем, кто побеждает не грубой силой, а хитростью. Его суть проста до гениальности: чтобы найти что-то в отсортированном списке, не нужно смотреть на каждый элемент. Нужно постоянно делить область поиска пополам. Так находили номер в бумажной телефонной книге толщиной в тысячу страниц, так ищет слово ваш компьютер в огромном словаре, и так же вы интуитивно отгадываете число в игре «Загадай число от 1 до 100». Давайте разберём эту магию по косточкам, поймём, почему её сложность O(log n) — это почти волшебство, и узнаем, где она прячется в вашем смартфоне и почему без неё интернет бы захлебнулся в данных.
Представьте ту самую бумажную телефонную книгу на 1000 страниц с фамилиями, отсортированными по алфавиту. Вам нужен номер Иванова. Глупый, но прямой способ (линейный поиск) — начать с первой страницы и просматривать все фамилии по порядку. В худшем случае, если Иванов в конце, вы пролистаете все 1000 страниц. В среднем — около 500. Ваше время и усилия прямо пропорциональны размеру книги: больше книга — дольше поиск. Это O(n), как мы выяснили в пошлой статье.
Теперь способ умный. Вы знаете, что книга отсортирована. Это ключевое предварительное условие бинарного поиска, без него он не работает. Вы делаете следующее:
- Откройте книгу ровно посередине (на 500-й странице).
- Посмотрите на фамилию на этой странице. Допустим, там «Кузнецов».
- Задайте вопрос: «Иванов» идёт в алфавитном порядке до «Кузнецова» или после? До. Значит, все страницы справа от 500-й (с «Кузнецовым» и далее) нам точно не нужны. Иванов там быть не может.
- Физически оторвите и выбросьте всю правую половину книги (от 501-й до 1000-й страницы). У вас в руках осталось 500 страниц.
- Повторите шаги 1-4 с оставшейся половиной. Откройте её посередине (на 250-й странице). Смотрите фамилию. Если там «Горшков», а Иванов — после, отбрасываем левую половину (1-250). И так далее.
Вы не просматриваете страницы. Вы отбрасываете половину неподходящих данных за один шаг. Каждое ваше действие сокращает поле поиска в геометрической прогрессии. Это и есть бинарный (двоичный) поиск: «бинарный» — потому что мы на каждом шаге имеем два варианта (левая половина или правая), а «поиск» — потому что ищем.
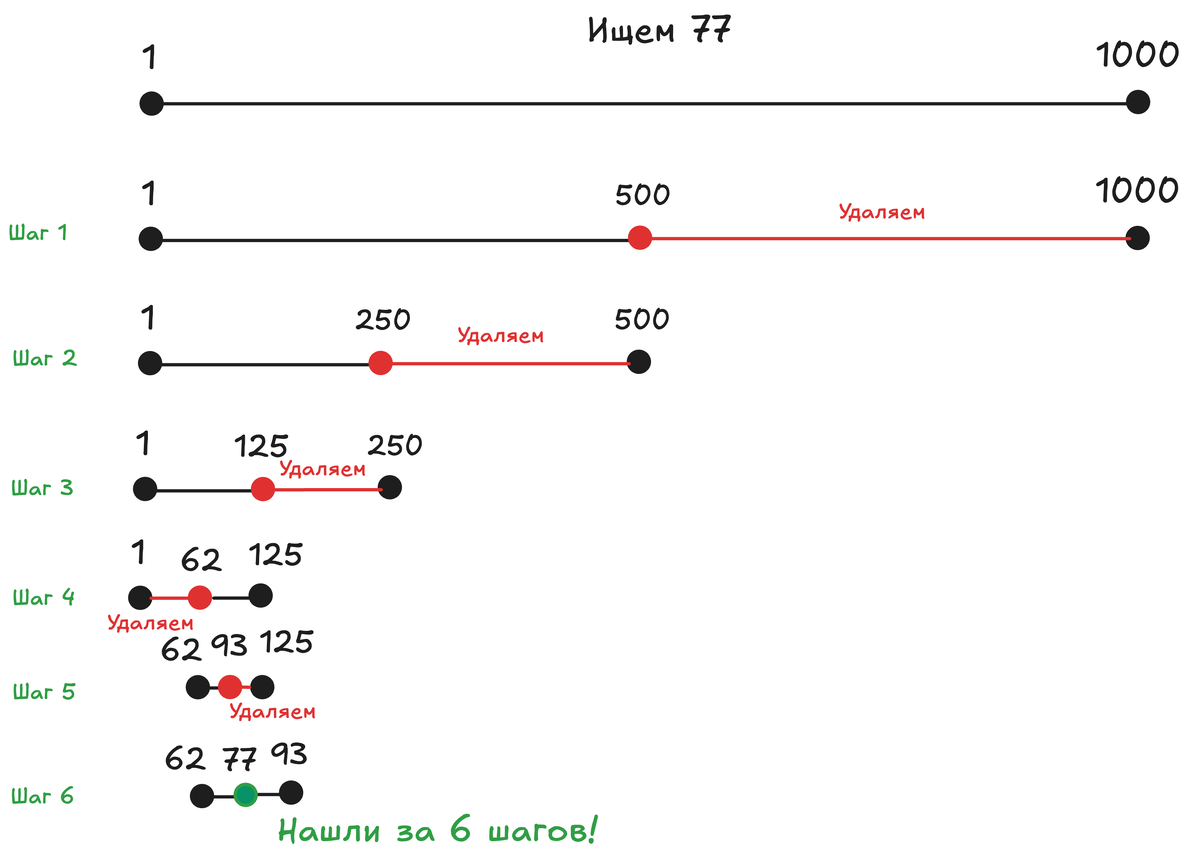
Это мы удачно попали, но давай посмотрим сколько максимально шагов может быть. 1000 -> 500 -> 250 -> 125 -> 62 -> 31 -> 15 -> 8 -> 4 -> 2 -> 1. От 1000 страниц до одной — всего за 10 шагов!
Давайте формализуем это для компьютера. У нас есть отсортированный массив (список) чисел или слов. Мы ищем элемент target.
- Объявляем две переменные-указателя: low (нижняя граница, сначала 0) и high (верхняя граница, сначала индекс последнего элемента).
- Пока low не стал больше high (пока границы не сошлись):
а. Находим средний индекс: mid = (low + high) / 2 (целочисленное деление).
б. Сравниваем элемент в позиции mid с нашим target.
в. Если они равны — ура, нашли! Возвращаем mid.
г. Если target больше элемента в mid, значит, искомое в правой половине. Сдвигаем нижнюю границу: low = mid + 1.
д. Если target меньше, сдвигаем верхнюю границу: high = mid - 1. - Если границы сошлись, а элемент не найден, значит, его в массиве нет.
Вот как это выглядит в действии для массива [1, 3, 5, 7, 9, 11, 13, 15] и поиска числа 9:
- Шаг 1: low=0, high=7. mid = (0+7)/2 = 3. array[3] = 7. 9 > 7? Да. Сдвигаем low = 4.
- Шаг 2: low=4, high=7. mid = (4+7)/2 = 5. array[5] = 11. 9 < 11? Да. Сдвигаем high = 4.
- Шаг 3: low=4, high=4. mid = 4. array[4] = 9. 9 == 9? Нашли! Индекс 4.
Всего 3 шага для массива из 8 элементов. Линейный поиск в худшем случае сделал бы 8 шагов.
А теперь главное — магия логарифмической сложности O(log n). Логарифм по основанию 2 (log₂) отвечает на вопрос: «В какую степень нужно возвести 2, чтобы получить N?». Или, в нашем контексте: «Сколько раз нужно разделить N пополам, чтобы получить 1?».
- В книге на 1000 страниц: 1000 -> 500 -> 250 -> 125 -> 62 -> 31 -> 15 -> 8 -> 4 -> 2 -> 1. 10 шагов. log₂(1000) ≈ 10.
- Массив из 1 000 000 элементов? log₂(1 000 000) ≈ 20 шагов.
- Массив из 1 000 000 000 (миллиард!) элементов? log₂(1 000 000 000) ≈ 30 шагов.
Подумайте об этом. Чтобы найти одну запись среди миллиарда, бинарному поиску нужно задать всего 30 вопросов «больше или меньше?». Линейному поиску в худшем случае — миллиард сравнений. Это разница между секундой и годами работы компьютера. Вот что значит O(log n) на практике. Это не просто «быстро». Это невероятно, экспоненциально быстро на больших данных.
Где же живёт бинарный поиск в современном мире? Он везде, где есть отсортированные данные и нужен быстрый поиск.
- В вашей операционной системе: Для поиска файла в отсортированном каталоге, для поиска процесса в списке.
- В базах данных: Для поиска по индексу (индекс — это и есть отсортированная структура, позволяющая искать не во всей таблице, а бинарно).
- В играх: Для поиска объекта в отсортированном списке, для определения попадания луча, для нахождения нужного значения в таблицах настроек.
- В системах контроля версий (Git): Для поиска конкретного коммита по хешу или метке.
- В любом приложении, где есть автодополнение или поиск по отсортированному списку контактов, песен, товаров.
Но у волшебства есть свои правила и ограничения. Главный недостаток бинарного поиска — требование сортировки. Если данные не отсортированы, алгоритм не работает. А сортировка сама по себе — операция не бесплатная. Поэтому бинарный поиск выгоден, когда вы один раз отсортировали данные (или они приходят уже отсортированными), а потом много-много раз ищете в них. Как та же телефонная книга — её один раз напечатали в отсортированном виде, а потом по ней ищут миллионы раз.
Ещё один тонкий момент: бинарный поиск работает только на структурах данных с произвольным доступом (как массив), где мы можем за O(1) получить элемент по его индексу. В связном списке, где чтобы добраться до середины, нужно пройти от начала, бинарный поиск теряет весь смысл.
Итак, что мы вынесли? Бинарный поиск — это не просто алгоритм. Это философия эффективного решения проблем. Это умение использовать структуру данных (отсортированность) для кардинального сокращения перебора. Он учит нас, что иногда лучший способ что-то найти — не бежать вперёд, а остановиться, оценить ситуацию и отбросить заведомо ложные пути. В мире, где данных становится всё больше, эта способность — делить задачу пополам и отсекать лишнее — становится бесценной. В следующий раз, когда вы будете искать песню в алфавитном списке плейлиста или товар в интернет-магазине с фильтром «сортировка по цене», вспомните: где-то там, под капотом интерфейса, тихо и неустанно работает старый добрый бинарный поиск, превращая ваше нетерпение в мгновенный результат. Он — настоящий невидимый герой цифрового века.
👍 Ставьте лайки если хотите разбор других интересных тем.
👉 Подписывайся на IT Extra на Дзен чтобы не пропустить следующие статьи
Если вам интересно копать глубже, разбирать реальные кейсы и получать знания, которых нет в открытом доступе — вам в IT Extra Premium.
Что внутри?
✅ Закрытые публикации: Детальные руководства, разборы сложных тем (например, архитектура высоконагруженных систем, глубокий анализ уязвимостей, оптимизация кода, полезные инструменты объяснения сложных тем простым и понятным языком).
✅ Конкретные инструкции: Пошаговые мануалы, которые вы сможете применить на практике уже сегодня.
✅ Без рекламы и воды: Только суть, только концентрат полезной информации.
✅ Ранний доступ: Читайте новые материалы первыми.
Это — ваш личный доступ к экспертизе, упакованной в понятный формат. Не просто теория, а инструменты для роста.
👉 Переходите на Premium и начните читать то, о чем другие только догадываются.
👇
Понравилась статья? В нашем Telegram-канале ITextra мы каждый день делимся такими же понятными объяснениями, а также свежими новостями и полезными инструментами. Подписывайтесь, чтобы прокачивать свои IT-знания всего за 2 минуты в день!