Как хаос превратить в порядок за секунды, даже если данных — миллионы. От педантичной медлительности к революционной скорости через гениальную идею «разделяй и властвуй».
В прошлый раз мы разобрали сортировку выбором — алгоритм честный, простой, но мучительно медленный на больших данных. Мы увидели, как вложенные циклы ведут к катастрофе сложности O(n²) и заставили наш воображаемый процессор ждать миллиарды наносекунд. Вы наверняка задались вопросом: «Неужели нет способа умнее? Неужели чтобы разложить миллион книг по полкам, нужно обязательно перебирать их миллиарды раз?». Есть. И сегодня мы познакомимся с одним из самых элегантных и мощных алгоритмов в истории — быстрой сортировкой. Это не просто очередной способ упорядочить числа. Это философия решения сложных задач. Вместо того, чтобы в лоб, как наш перфекционист-библиотекарь, искать минимум в огромной куче, быстрая сортировка действует как гениальный стратег: она дробит большую неподъёмную проблему на маленькие, лёгкие, решает их по отдельности — и побеждает. Она виртуозно соединяет две мощные концепции, о которых мы уже говорили: рекурсию (функцию, вызывающую саму себя) и стратегию «разделяй и властвуй». Готовьтесь — сейчас вы увидите, как изящная идея позволяет сортировать миллионы элементов за время, которое нужно сортировке выбором всего для нескольких тысяч. Это алгоритм-разрушитель барьеров масштаба.
Итак, у нас есть тот же неупорядоченный массив: [64, 25, 12, 22, 11]. Но на этот раз наш подход будет принципиально иным. Вместо поиска минимума мы поступим хитро.
Основная идея: «Разделяй и властвуй»
- Разделяй: Выбери один элемент массива — он называется опорным. Теперь переставь все остальные элементы так, чтобы те, что меньше опорного, оказались слева от него, а те, что больше — справа. Сам опорный элемент после этого оказывается на своём окончательном, правильном месте! Массив теперь разделён на две независимые части.
- Властвуй: Примени этот же процесс рекурсивно к левой части (элементы меньше опорного и к правой части (элементы больше опорного).
- Объединяй: А вот и самое красивое — объединять ничего не нужно! Поскольку на каждом шаге опорный элемент встаёт на своё итоговое место, а левая и правая части сортируются независимо, то когда рекурсия дойдёт до конца (когда части будут состоять из одного или нуля элементов), весь массив окажется отсортированным.
Всё гениальное просто? Давайте разбирать по косточкам, начиная с самого сердца алгоритма — процедуры разделения.
Шаг 1: Выбор опорного элемента
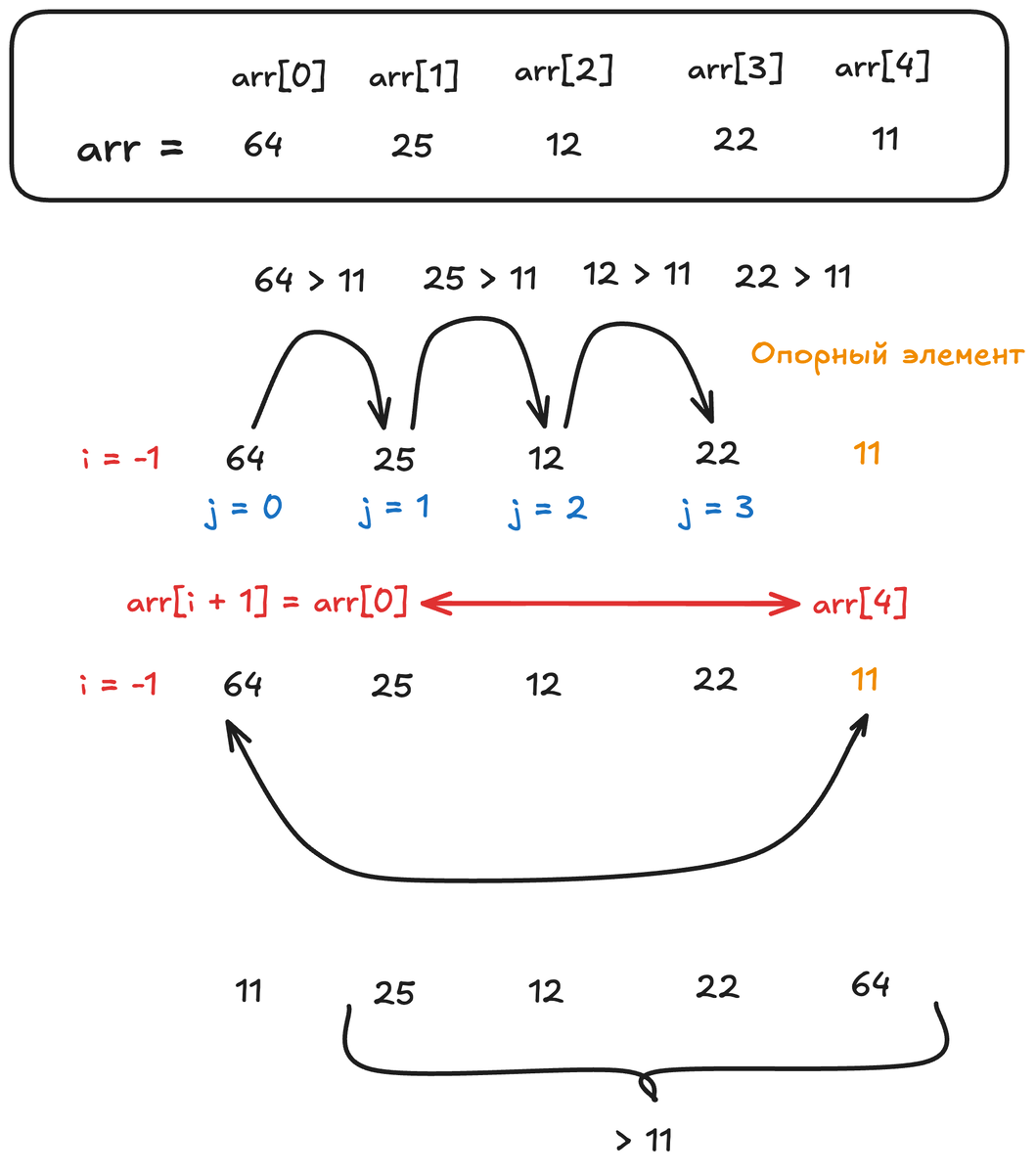
Опорным можно выбрать любой элемент: первый, последний, средний или случайный. От этого выбора сильно зависит эффективность, но для понимания сути возьмём последний элемент. Для массива [64, 25, 12, 22, 11] опорным (pivot) будет 11.
Шаг 2: Разделение — магия одной проходки
Нам нужно переместить все элементы меньше 11 влево, а все бóльшие — вправо. Делается это за один проход по массиву с помощью двух «указателей». Представьте, что вы расставляете мебель в комнате, условно разделённой на зоны «для маленьких» и «для больших». У вас есть индекс i, который отмечает границу «зоны меньших», и индекс j, который пробегает по всей комнате и смотрит на каждый предмет.
Алгоритм разделения для нашего массива ([64, 25, 12, 22, 11]):
- Граница «зоны меньших» (i) изначально стоит перед самым первым элементом (условно, на позиции -1).
- j идёт от начала массива до элемента, предшествующего pivot.
- Если элемент arr[j] меньше pivot, то граница i сдвигается на шаг вправо, и arr[i] меняется местами с arr[j]. Так мы «пододвигаем» меньший элемент в свою зону.
- После того как j дошёл до конца, i указывает на последний элемент в «зоне меньших». Осталось поставить сам pivot на своё законное место: нужно поменять arr[i+1] с pivotом (последним элементом).
Давайте промоделируем. Ищем элементы меньше 11.
- j=0: 64 > 11. Ничего не делаем. i остаётся = -1.
- j=1: 25 > 11. Ничего. i = -1.
- j=2: 12 > 11. Ничего. i = -1.
- j=3: 22 > 11. Ничего. i = -1.
j прошёл все элементы перед pivot. Ни одного элемента меньше 11 не нашлось. Значит, i так и остался -1. Теперь меняем arr[i+1] (то есть arr[0], число 64) с pivotом (11). Получаем массив: [11, 25, 12, 22, 64].
Вуаля! Pivot (11) оказался на своей итоговой позиции — первом месте в отсортированном массиве. Слева от него (условно) — пустая зона элементов меньше, справа — [25, 12, 22, 64] (все элементы больше 11).
Шаг 3: Рекурсия — сила самообращения
Теперь вспомним статью о рекурсии. У нас есть чёткий базовый случай: если подмассив для сортировки содержит 0 или 1 элемент, он уже отсортирован.
И шаг рекурсии: разбить задачу на подзадачи.
Наш текущий массив: [11, 25, 12, 22, 64].
Pivot 11 уже на месте. Нам нужно рекурсивно применить быструю сортировку к левой части (она пуста, базовый случай — ничего не делаем) и к правой части: [25, 12, 22, 64].
Запускаем quicksort([25, 12, 22, 64]):
- Pivot (последний) = 64.
- Разделение: переставляем элементы так, чтобы меньшие чем 64 ушли влево.
а) j смотрит 25, 12, 22. Все они меньше 64.
б) i будет последовательно увеличиваться, и эти числа будут оставаться на своих местах относительно друг друга, но в «зоне меньших».
в) После прохода i будет на последнем из них (22). Меняем arr[i+1] (то есть
i + 1 = 3 что соответствует 64) с pivotом(64) — по сути, pivot остаётся на месте.
г) Результат: [25, 12, 22, 64]. Pivot 64 встал на итоговое последнее место.
Теперь рекурсивно сортируем левую часть от 64: [25, 12, 22].
- Pivot = 22.
- Разделение:
j=0: 25 > 22. Ничего.
j=1: 12 < 22! Сдвигаем i с -1 на 0, меняем arr[0] (25) и arr[1] (12). Массив стал [12, 25, 22].
j завершил обход. i теперь = 0. Меняем arr[i+1] (25) с pivot (22).
Результат: [12, 22, 25]. Pivot 22 на своём месте.
Рекурсивные вызовы для [12] (слева от 22) и [25] (справа от 22) — базовые случаи.
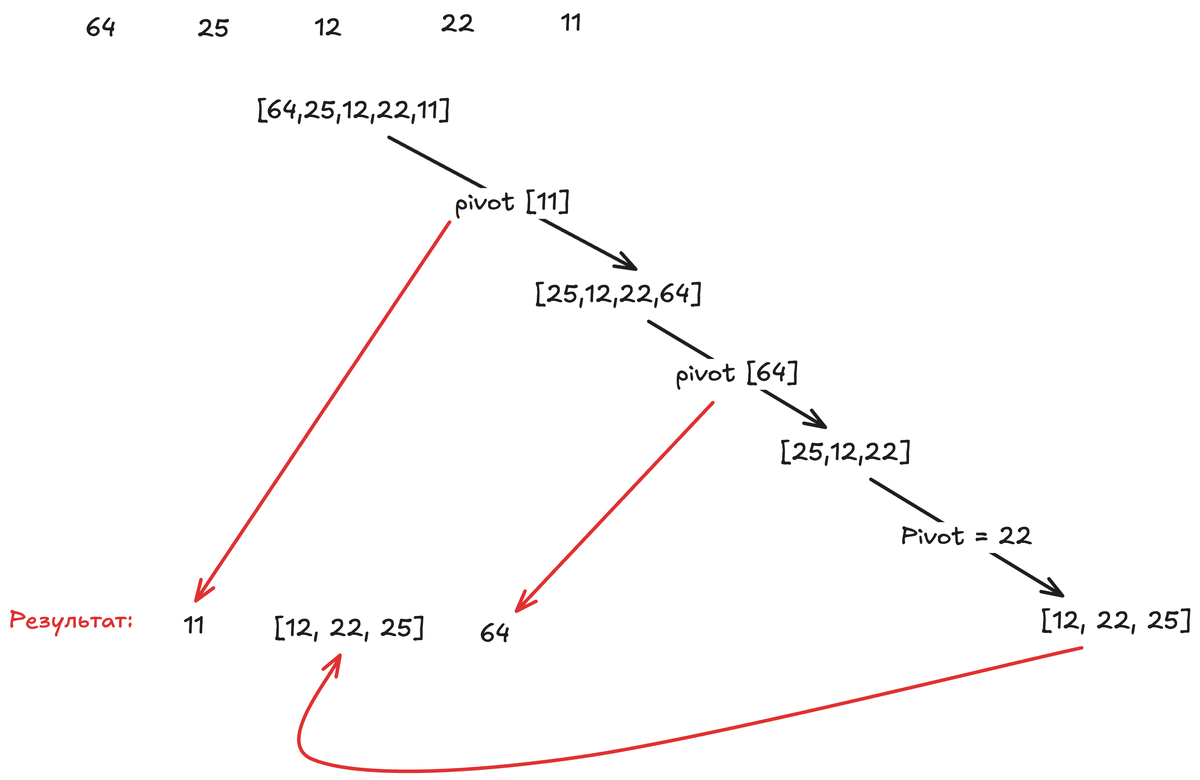
Цепочка рекурсивных вызовов схлопывается, и мы получаем полностью отсортированный массив: [11, 12, 22, 25, 64]. Обратите внимание: ни одна операция слияния не потребовалась.
Вот где происходит магия. В худшем случае (если pivot каждый раз оказывается минимальным или максимальным элементом, как в нашем первом шаге с 11), мы получим несбалансированное разбиение: одна часть пуста, а другая содержит n-1 элемент. Это приведёт к глубине рекурсии в n уровней и итоговой сложности O(n²) — как у сортировки выбором.
Но в среднем случае разбиение будет более-менее равномерным. Представьте, что pivot каждый раз делит массив пополам.
- На первом уровне рекурсии мы делаем операцию разделения для n элементов — это O(n) операций.
- На втором уровне у нас два подмассива размером ~n/2. Разделение каждого требует ~n/2 операций. В сумме снова ~O(n).
- На третьем уровне четыре подмассива по ~n/4, суммарно снова ~O(n).
Cколько таких уровней? Поскольку мы каждый раз (в идеале) делим пополам, количество уровней будет логарифмическим по основанию 2 от n. Это то самое log₂ n, которое мы видели в бинарном поиске.
Итак, мы выполняем O(n) операций на каждом из O(log n) уровней. Перемножаем: O(n) * O(log n) = O(n log n).
Давайте вернёмся к нашему мысленному процессору и наносекундам и сравним с сортировкой выбором (O(n²)):
Для n = 1 000 000:
- Сортировка выбором: ~500 млрд сравнений = 500 секунд (8+ минут).
- Быстрая сортировка (в среднем): ~n log₂ n ≈ 1 000 000 * 20 = 20 млн сравнений = 0.02 секунды.
Разница в 25 000 раз! Это не просто улучшение. Это переход в другой класс задач. Данные, которые раньше было невозможно обработать за разумное время, становятся подвластны.
Быстрая сортировка — это рекурсивный алгоритм, основанный на стратегии «разделяй и властвуй». Его суть — выбрать опорный элемент и переупорядочить массив так, чтобы все меньшие элементы оказались слева, а бóльшие — справа от него. После этой операции опорный элемент оказывается на своём окончательном месте в отсортированном массиве. Затем алгоритм рекурсивно применяется к левой и правой частям. В среднем случае это обеспечивает сложность O(n log n), что делает его невероятно эффективным для больших массивов данных.
Используйте этот алгоритм, когда вам нужна универсальная, эффективная сортировка в памяти для произвольных данных. Это «рабочая лошадка» в стандартных библиотеках многих языков (например, qsort в C, Arrays.sort() для примитивов в Java).
Избегайте или будьте осторожны, если:
1) Вы знаете, что данные уже почти отсортированы, а pivot выбирается плохо (ведёт к худшему случаю O(n²)). Решение — выбор случайного pivotа или медианы.
2) Вам требуется стабильность (сохранение порядка равных элементов) — быстрая сортировка нестабильна.
3) Память критична — из-за рекурсии в худшем случае глубина стека может быть O(n), хотя в среднем O(log n).
Быстрая сортировка — это больше чем алгоритм. Это доказательство того, что правильная стратегия — разделить неподъёмную проблему, победить каждую часть по отдельности и грамотно соединить результаты (или, как здесь, вообще не соединять) — является ключом к решению задач колоссального масштаба. Она не просто сортирует числа. Она стирает барьеры.
👍 Ставьте лайки если хотите разбор других интересных тем.
👉 Подписывайся на IT Extra на Дзен чтобы не пропустить следующие статьи
Если вам интересно копать глубже, разбирать реальные кейсы и получать знания, которых нет в открытом доступе — вам в IT Extra Premium.
Что внутри?
✅ Закрытые публикации: Детальные руководства, разборы сложных тем (например, архитектура высоконагруженных систем, глубокий анализ уязвимостей, оптимизация кода, полезные инструменты объяснения сложных тем простым и понятным языком).
✅ Конкретные инструкции: Пошаговые мануалы, которые вы сможете применить на практике уже сегодня.
✅ Без рекламы и воды: Только суть, только концентрат полезной информации.
✅ Ранний доступ: Читайте новые материалы первыми.
Это — ваш личный доступ к экспертизе, упакованной в понятный формат. Не просто теория, а инструменты для роста.
👉 Переходите на Premium и начните читать то, о чем другие только догадываются.
👇
Понравилась статья? В нашем Telegram-канале ITextra мы каждый день делимся такими же понятными объяснениями, а также свежими новостями и полезными инструментами. Подписывайтесь, чтобы прокачивать свои IT-знания всего за 2 минуты в день!