Почему самый простой способ упорядочить хаос работает мучительно долго, и что это говорит о вашем подходе к задачам. Разбираем первый и самый честный алгоритм сортировки.
В прошлый раз мы восхищались скоростью и хитростью бинарного поиска. Но был нюанс: он требует, чтобы данные были уже отсортированы. А что, если они в хаосе? Откуда берётся этот порядок? Сегодня мы спустимся с небес мгновенного поиска на грешную землю, где царит беспорядок, и познакомимся с самым простым, прямолинейным и… мучительно медленным способом навести порядок — сортировкой выбором (Selection Sort). Если бинарный поиск — это умный детектив, то сортировка выбором — это педантичный библиотекарь-перфекционист. Его метод безупречно логичен и прост для понимания: он находит самый маленький (или самый большой) элемент и ставит его на правильное место. Затем находит следующий и ставит его. И так далее, пока всё не будет идеально. Именно эта простота делает его идеальным учебным полигоном. Здесь мы воочию увидим, как работает пресловутый вложенный цикл, и на конкретных цифрах поймём, почему сложность O(n²) — это не просто буквы, а приговор для работы с большими данными. Готовьтесь — вы узнаете алгоритм, который вы используете, разбирая вещи после переезда, и который никогда не стоит использовать для сортировки вашей фонотеки.
Итак, у нас есть массив (список) в случайном порядке: [64, 25, 12, 22, 11]. Наша задача — расположить числа по возрастанию. Как подошёл бы к этому перфекционист? Он бы сказал: «Первое место в отсортированном массиве должно занимать самое маленькое число. Найду его и поставлю туда». Алгоритм сортировки выбором делает ровно это, повторяя один и тот же шаг.
Шаг перфекциониста (он же основной цикл алгоритма):
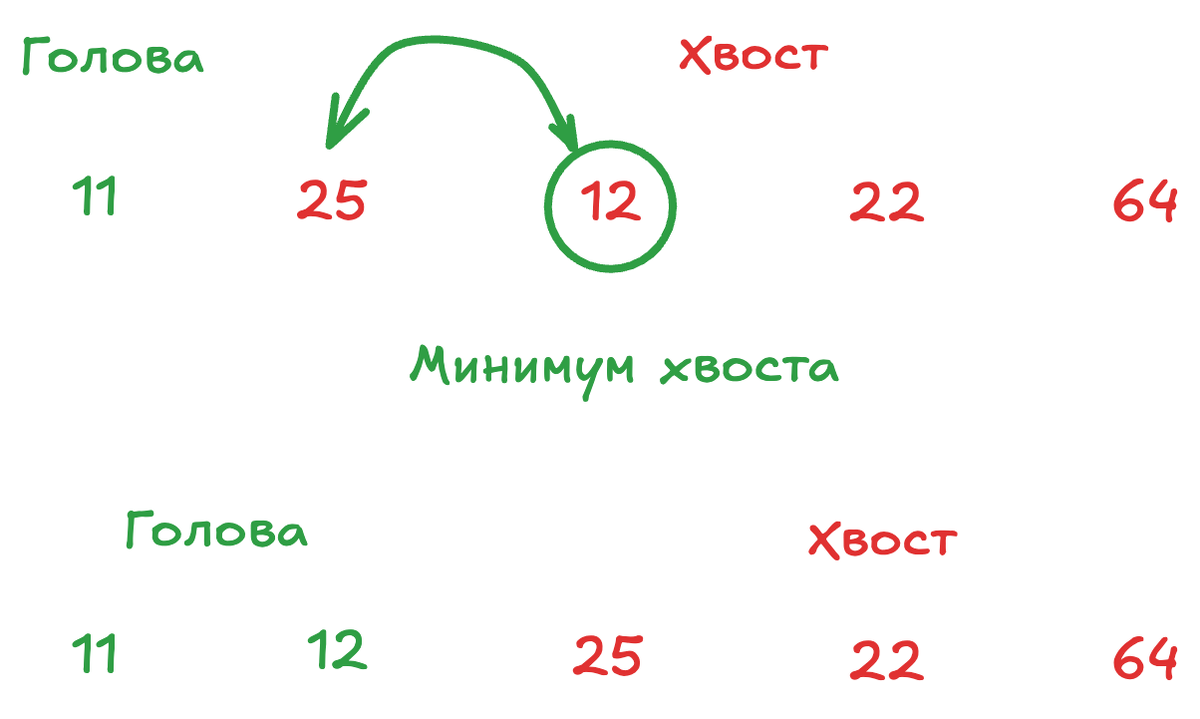
- Взгляд на оставшуюся кучу. Представьте, что у вас есть неотсортированный «хвост» массива и уже готовый «голова».
- Найти минимум. Вы просматриваете весь хвост от начала до конца, чтобы найти самый маленький элемент.
- Поменять местами. Вы меняете этот найденный минимум с самым первым элементом хвоста.
- Сдвинуть границу. Теперь первый элемент хвоста стоит на своём окончательном месте. Вы мысленно (или в коде) сдвигаете границу: то, что было «хвостом», теперь чуть меньше, а отсортированная «голова» — чуть больше.
- Повторить для нового, уменьшенного хвоста.
Давайте пройдём пошагово для нашего массива [64, 25, 12, 22, 11]:
- Проход 1: Весь массив — хвост. Ищем минимум. Это 11 на позиции 4. Меняем его с первым элементом (64). Массив стал: [11, 25, 12, 22, 64]. Первое место теперь точно занято самым маленьким числом.
- Проход 2: Хвост теперь [25, 12, 22, 64] (элементы с индексами 1..4). Ищем минимум в хвосте. Это 12 на позиции 2. Меняем его с первым элементом хвоста (25). Массив: [11, 12, 25, 22, 64]. Первые два места заняты правильно.
- Проход 3: Хвост [25, 22, 64]. Минимум — 22. Меняем с 25. Массив: [11, 12, 22, 25, 64].
- Проход 4: Хвост [25, 64]. Минимум — 25. Он уже на первом месте хвоста. Менять не нужно.
- Проход 5: Хвост [64]. В хвосте один элемент — он же минимум. Сортировка завершена.
Вы видите шаблон? На каждом проходе мы гарантированно ставим один элемент на его окончательное место. Для массива из n элементов нужно сделать n-1 проход (последний элемент автоматически встанет на своё место).
Теперь давайте заглянем под капот и увидим того самого монстра — вложенный цикл. Внешний цикл отвечает за проходы (за шаг перфекциониста «сдвинуть границу»). Он выполнится n-1 раз. А внутри него, на каждом проходе, работает внутренний цикл, который ищет минимум в хвосте. И вот здесь начинается драма.
На первом проходе внутренний цикл просматривает n элементов.
На втором — n-1.
На третьем — n-2.
...
На последнем — 1 элемент.
Общее количество сравнений (это основная операция в сортировке выбором) — это сумма арифметической прогрессии: n + (n-1) + (n-2) + ... + 1. Есть известная формула для такой суммы: S = n * (n + 1) / 2.
Если раскрыть скобки, получим: S = (n² + n) / 2.
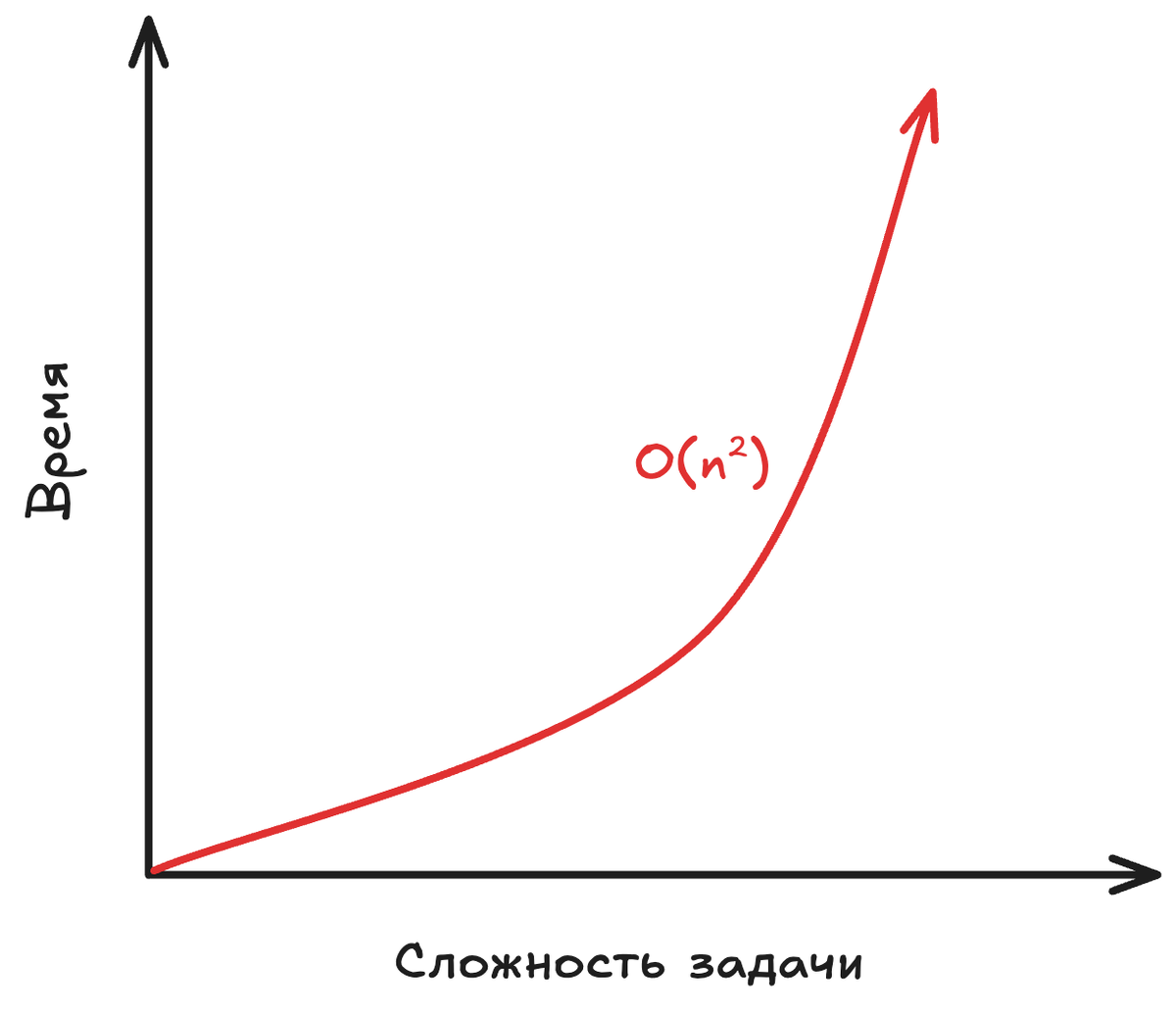
Вот мы и встретились с ним — квадратичный член n². В нотации Big O мы отбрасываем константы (деление на 2) и несущественные для больших n слагаемые (тот самый n рядом с n²). Почему? Потому что когда n становится огромным (тысячи, миллионы), n² будет в миллионы раз больше, чем n. Итог: сортировка выбором имеет временную сложность O(n²).
Что это значит на практике? Давайте представим, что вы — процессор, и одно сравнение двух чисел занимает у вас 1 наносекунду (нс).
- Для n = 100 элементов: S ≈ (100²)/2 = 5000 сравнений. Это 5 микросекунд. Мгновенно!
- Для n = 10 000 элементов: S ≈ (10 000²)/2 = 50 000 000 сравнений. Это 50 миллисекунд. Чувствуется, но терпимо.
- Для n = 1 000 000 (миллион, не так уж много для современной БД): S ≈ (1 000 000²)/2 = 500 000 000 000 сравнений. Это 500 секунд, или более 8 минут простоя!
- Для n = 1 000 000 000 (миллиард): S ≈ 5*10^17 сравнений. Это около 16 лет непрерывной работы.
Видите, как коварен O(n²)? Увеличение данных в 1000 раз (с 10 тыс. до 10 млн) увеличивает время работы не в 1000 раз, а примерно в миллион раз. Это и есть «плохо для больших данных». Алгоритм просто не масштабируется.
Но почему же этот алгоритм до сих пор изучают? Потому что у него есть неоспоримые достоинства для понимания:
- Простота реализации. Его может написать даже тот, кто только узнал про циклы.
- Минимум операций обмена. В отличие от других алгоритмов, сортировка выбором делает не более n-1 обменов. Это может быть важно, если операция обмена ресурсоёмка (например, вы сортируете не числа, а тяжёлые объекты в памяти, которые долго копируются).
- Сортировка на месте. Ей не требуется дополнительная память, сравнимая с размером входных данных. Она всё делает прямо в исходном массиве.
Где это можно встретить в жизни? Всякий раз, когда вы физически перекладываете предметы, выбирая самый подходящий. Сбор пазла, начиная с угловых и краевых элементов (выбор и размещение). Расстановка книг на полке по росту, беря каждый раз самую маленькую из оставшихся. Это наш естественный, интуитивный, но не оптимальный способ наведения порядка.
Итак, что мы вынесли из знакомства с сортировкой выбором? Мы увидели, как наивная, но понятная стратегия «найди и поставь на место» приводит к катастрофическому замедлению на больших объёмах из-за вложенных циклов. O(n²) — это не просто символ, это предупреждение: если в вашем алгоритме вы видите вложенный цикл по тем же данным, спросите себя — а нельзя ли иначе? Именно этот вопрос и привёл компьютерных учёных к созданию гораздо более умных алгоритмов сортировки, таких как быстрая сортировка и сортировка слиянием, которые работают за O(n log n) и справляются с миллионами элементов за секунды. Сортировка выбором — это важная ступенька. Она учит нас основам, заставляет уважать сложность и ценить элегантность решений, которые мы разберём в следующих статьях. Это алгоритм-учитель: медленный, педантичный, но честный, показывающий, как не стоит сортировать в реальном мире, если, конечно, вы не готовы ждать 16 лет.
👍 Ставьте лайки если хотите разбор других интересных тем.
👉 Подписывайся на IT Extra на Дзен чтобы не пропустить следующие статьи
Если вам интересно копать глубже, разбирать реальные кейсы и получать знания, которых нет в открытом доступе — вам в IT Extra Premium.
Что внутри?
✅ Закрытые публикации: Детальные руководства, разборы сложных тем (например, архитектура высоконагруженных систем, глубокий анализ уязвимостей, оптимизация кода, полезные инструменты объяснения сложных тем простым и понятным языком).
✅ Конкретные инструкции: Пошаговые мануалы, которые вы сможете применить на практике уже сегодня.
✅ Без рекламы и воды: Только суть, только концентрат полезной информации.
✅ Ранний доступ: Читайте новые материалы первыми.
Это — ваш личный доступ к экспертизе, упакованной в понятный формат. Не просто теория, а инструменты для роста.
👉 Переходите на Premium и начните читать то, о чем другие только догадываются.
👇
Понравилась статья? В нашем Telegram-канале ITextra мы каждый день делимся такими же понятными объяснениями, а также свежими новостями и полезными инструментами. Подписывайтесь, чтобы прокачивать свои IT-знания всего за 2 минуты в день!