
Предисловие:
Стоимостная модель планировщика запросов PostgreSQL — основной инструмент для прогнозирования производительности. Но насколько точны ее предсказания в условиях реальной высокой параллельной нагрузки? Эксперимент с сравнением методов доступа Seq Scan и Index Only Scan выявил систематическое расхождение между прогнозом и практическими результатами. Это исследование анализирует глубинные причины этого несоответствия и предлагает методику для более точного предсказания поведения СУБД.
ℹ️ Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Сравнительный анализ методов доступа и расхождение с прогнозом
Подробности и детали эксперимента
Методология эксперимента
Для проведения нагрузочного тестирования была создана тестовая таблица pgbench_test с 1 млн записей. Ключевой тестовый запрос выполнял соединение с фильтрацией по первичному ключу. Сравнивались два метода доступа к данным:
- Последовательное сканирование (Seq Scan) с параллельным выполнением.
- Только индексное сканирование (Index Only Scan) с использованием специально созданного покрывающего индекса idx_pgbench_test_bid_abalance.
Исходный прогноз, основанный на анализе планов выполнения (EXPLAIN ANALYZE), был однозначен: Index Only Scan ожидался в сотни раз эффективнее из-за значительно меньшей стоимости (0.99..48.86 против 1002.80..21620.62) и времени выполнения (1.186 ms против 329.017 ms).
Результаты нагрузочного тестирования и анализ аномалии
Реальные данные продолжительного тестирования с числом параллельных сессий от 5 до 22 опровергли первоначальный прогноз. Вместо катастрофической деградации Seq Scan и стабильной работы индекса, была зафиксирована обратная динамика. Хотя Index Only Scan в среднем сохранял преимущество в 9%, в финальной фазе теста производительность Seq Scan в отдельных замерах превысила индексный доступ на 0.66-6.42%.
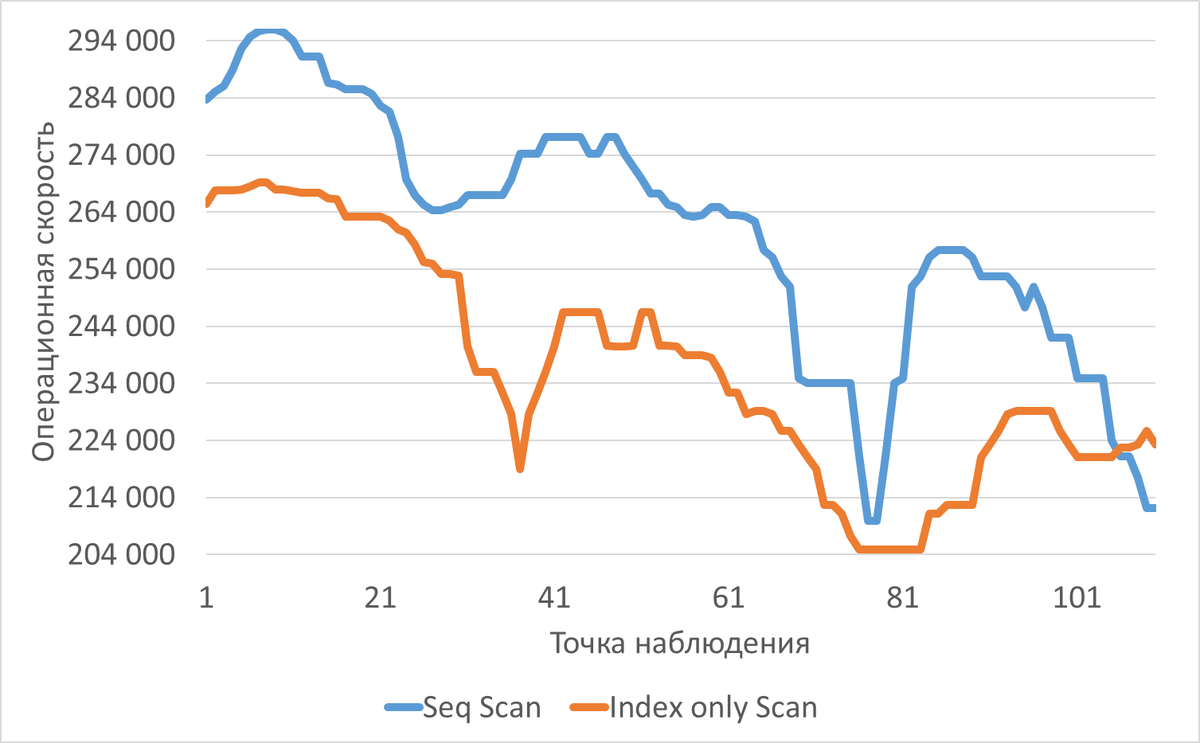
Ключевые причины расхождения прогноза с реальностью:
- Эффект кэширования данных. Статическая модель не учитывала, что при длительной нагрузке данные таблицы полностью помещаются в буферный кэш (shared_buffers). Seq Scan, считавшийся "тяжелым", переставал выполнять физический I/O и начинал работать исключительно в памяти, нивелируя свое главное слабое место.
- Конкуренция за доступ к индексным страницам (Contention). Прогноз переоценил масштабируемость Index Only Scan. В условиях высокой параллельности множество сессий одновременно обращались к одним и тем же страницам B-дерева, что приводило к блокировкам и росту времени ожидания. Напротив, параллельные workers при Seq Scan работали с разными участками таблицы, снижая конкуренцию.
- Накладные расходы обслуживания индекса. Модель не принимала во внимание затраты на обеспечение целостности индекса в многопоточной среде, включая механизм Multiversion Concurrency Control (MVCC) и дополнительные операции для проверки видимости записей, которые отсутствуют при последовательном сканировании.
- Адаптивность планировщика и управления ресурсами. Динамические алгоритмы PostgreSQL по управлению памятью и планированию задач оказались эффективнее, чем предполагалось в статической модели. Система успешно перераспределяла ресурсы, предотвращая исчерпание памяти при использовании Seq Scan.
Заключение и рекомендации
Проведенный эксперимент демонстрирует, что стоимостная модель планировщика PostgreSQL, будучи точной для изолированного выполнения запроса, может давать систематические ошибки при прогнозировании производительности в условиях высокой конкурентной нагрузки.
Практические рекомендации:
- Для коротких OLTP-запросов предпочтение следует отдавать индексному доступу.
- Для длительных аналитических нагрузок и отчетов эффективнее может оказаться последовательное сканирование на прогретых данных.
- Нагрузочное тестирование должно обязательно проводиться на прогретой базе данных с продолжительным "прогревом" и моделированием реальной конкуренции за ресурсы.
- Мониторинг должен включать наблюдение за статистикой конкурентного доступа к индексам (например, через pg_stat_all_indexes).
Таким образом, выбор оптимального метода доступа требует не только анализа плана запроса, но и учета характера нагрузки, продолжительности работы и степени параллелизма в рабочей среде.