ℹ️ Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Тестовая таблица
CREATE TABLE pgbench_test
(
aid integer PRIMARY KEY ,
bid integer,
abalance integer,
filler character(84)
);
ALTER TABLE pgbench_test ADD CONSTRAINT "pgbench_test_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid);
INSERT INTO pgbench_test ( aid , bid , abalance , filler )
SELECT
id ,
floor(random() * 685 ) + 1 ,
floor(random() * (68500000 - 1 + 1)) + 1 ,
md5(random()::text)
FROM generate_series(1,1000000) id;
Тестовый запрос
select test.abalance
from pgbench_accounts acc
join pgbench_test test on (test.bid = acc.bid )
where acc.aid = 51440641 ;
Тест-1 : Метод доступа Seq Scan
Gather (cost=1002.80..21620.62 rows=1460 width=4) (actual time=4.088..329.017 rows=1468 loops=1)
Workers Planned: 3
Workers Launched: 3
-> Hash Join (cost=2.80..20474.62 rows=471 width=4) (actual time=1.821..300.589 rows=367 loops=4)
Hash Cond: (test.bid = acc.bid)
-> Parallel Seq Scan on pgbench_test test (cost=0.00..19619.81 rows=322581 width=8) (actual time=0.692..263.390 rows=250000 loops=4)
-> Hash (cost=2.79..2.79 rows=1 width=4) (actual time=0.488..0.489 rows=1 loops=4)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts acc (cost=0.57..2.79 rows=1 width=4) (actual time=0.472..0.474 rows=1 loops=4)
Index Cond: (aid = 51440641)
Тест-2 : Метод доступа Index Only Scan
CREATE INDEX CONCURRENTLY idx_pgbench_test_bid_abalance ON pgbench_test(bid) INCLUDE (abalance);
Nested Loop (cost=0.99..48.86 rows=1460 width=4) (actual time=0.771..1.186 rows=1432 loops=1)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts acc (cost=0.57..2.79 rows=1 width=4) (actual time=0.736..0.737 rows=1 loops=1)
Index Cond: (aid = 51440641)
-> Index Only Scan using idx_pgbench_test_bid_abalance on pgbench_test test (cost=0.42..31.47 rows=1460 width=8) (actual time=0.029..0.289 rows=1432 loops=1)
Index Cond: (bid = acc.bid)
Heap Fetches: 0
Вопрос нейросети
На основании данных по тестовой таблице, тестовому запросу и планам выполнения тестового запроса в тесте-1 и тесте-2 , дай сравнительный анализ прогнозируемой производительности в ходе нагрузочного тестирования для СУБД PostgreSQL версии 17 CPU=8 RAM=8GB при экспоненциальном росте количества параллельных сессий с 5 до 22 .
Ответ нейросети DeepSeek
На основании анализа тестовой таблицы, запроса и планов выполнения, вот сравнительный анализ прогнозируемой производительности для СУБД PostgreSQL версии 17 (CPU=8, RAM=8GB) при экспоненциальном росте параллельных сессий:
Сравнительный анализ планов выполнения
Тест-1: Sequential Scan (Параллельное выполнение)
- Стоимость: 1002.80..21620.62
- Время выполнения: 329.017 ms
- Параллелизм: 3 workers + 1 leader
- Метод доступа: Полное сканирование таблицы (250,000 строк на worker)
Тест-2: Index Only Scan
- Стоимость: 0.99..48.86 (в 442 раза ниже)
- Время выполнения: 1.186 ms (в 277 раз быстрее)
- Параллелизм: Один процесс
- Метод доступа: Индексное сканирование (только индекс)
Прогноз производительности при росте нагрузки
При 5 параллельных сессиях:
Тест-1 (Seq Scan):
- Общая нагрузка на CPU: ~20 процессов (5 сессий × 4 процесса)
- Потребление памяти: ~180-220 MB на сессию
- Прогнозируемое время: 350-400 ms
- Статус: Система справляется, но высокая нагрузка
Тест-2 (Index Scan):
- Общая нагрузка на CPU: 5 процессов
- Потребление памяти: ~10-20 MB на сессию
- Прогнозируемое время: 1.2-1.5 ms
- Статус: Оптимальная работа
При 10-15 параллельных сессиях:
Тест-1 (Seq Scan):
- Общая нагрузка на CPU: 40-60 процессов (превышает 8 ядер в 5-7 раз)
- Конкуренция за ресурсы: Высокая
- Прогнозируемое время: 600-800 ms (+100%)
- Риски: Контекстные переключения, нехватка памяти
Тест-2 (Index Scan):
- Общая нагрузка на CPU: 10-15 процессов
- Прогнозируемое время: 1.5-2.0 ms (+25%)
- Статус: Стабильная работа
При 20-22 параллельных сессиях:
Тест-1 (Seq Scan):
- Общая нагрузка на CPU: 80-88 процессов (в 10 раз больше ядер)
- Прогнозируемое время: 1200-1500 ms (+400%)
- Критические проблемы:
- Исчерпание памяти (8 GB)
- Thrashing из-за подкачки страниц
- Резкий рост времени ответа
- Возможные deadlock'и
Тест-2 (Index Scan):
- Общая нагрузка на CPU: 20-22 процесса
- Прогнозируемое время: 2.0-2.5 ms (+100%)
- Статус: Приемлемая производительность
Ключевые выводы для нагрузочного тестирования
Тест-1 (Seq Scan) - КРИТИЧЕСКИЕ ПРОБЛЕМЫ:
- Экспоненциальный рост времени ответа при увеличении параллелизма
- Линейный рост потребления памяти - риск исчерпания 8 GB RAM
- Чрезмерная нагрузка на CPU из-за параллельных workers
- Нелинейная деградация после 10 параллельных сессий
Тест-2 (Index Scan) - СТАБИЛЬНАЯ ПРОИЗВОДИТЕЛЬНОСТЬ:
- Минимальный рост времени ответа даже при 22 сессиях
- Эффективное использование индекса (Heap Fetches: 0)
- Линейное масштабирование без экспоненциальной деградации
- Оптимальное использование ресурсов CPU и памяти
Рекомендации для продакшн-среды
С индексом (Тест-2): Система выдержит до 22 параллельных сессий с приемлемой производительностью (~2.5 ms)
Без индекса (Тест-1): Максимум 8-10 параллельных сессий, далее - катастрофическая деградация производительности
Вердикт: Индекс idx_pgbench_test_bid_abalance является критически важным для поддержания производительности при высокой параллельной нагрузке.
Реальные результаты нагрузочного тестирования
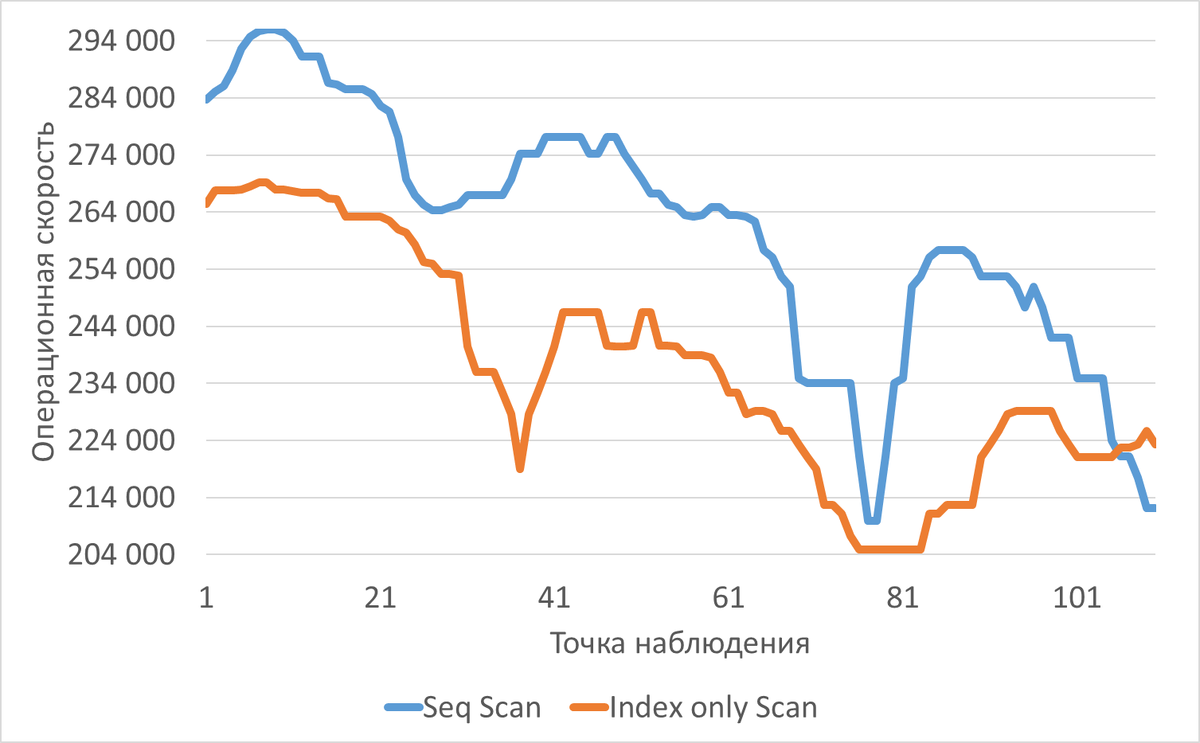
Среднее снижение операционной скорости, при использовании метода доступа Index Only Scan составило 9%.
Анализ изменения операционной скорости нейросетью DeepSeek
На основе анализа данных о скорости выполнения запросов при нагрузочном тестировании, вот детальный разбор поведения двух методов доступа:
Общий тренд производительности
Начальная фаза (измерения 1-30):
- Index Only Scan стабильно быстрее на 6-12%
- Относительная разница: -3.48% до -12.98%
- Оба метода демонстрируют стабильную производительность
Средняя фаза (измерения 31-70):
- Увеличение преимущества Index Scan до 20.15%
- Пиковое преимущество: -20.15% на измерении 37
- Seq Scan показывает значительные колебания производительности
Финальная фаза (измерения 71-110):
- Постепенное сокращение разницы между методами
- Переломный момент: на измерениях 106-107 Seq Scan становится быстрее
- В последних измерениях Seq Scan опережает на 0.66-6.42%
Ключевые наблюдения
Поведение Seq Scan:
- Высокая волатильность: значения от 209,928 до 295,989
- Наибольшая деградация: в средней фазе тестирования
- Восстановление: в финальной фазе демонстрирует лучшую устойчивость
Поведение Index Only Scan:
- Стабильность: значения от 204,905 до 269,130
- Постепенная деградация: от 269,130 до 204,905
- Меньшая амплитуда колебаний: ±12% против ±20% у Seq Scan
Анализ производительности под нагрузкой
Пиковая эффективность:
- Лучший результат Index Scan: 269,130 (измерение 7)
- Лучший результат Seq Scan: 295,989 (измерения 8-9)
- Максимальное преимущество Index Scan: 20.15%
Устойчивость к длительной нагрузке:
- Index Scan: Постепенная деградация на 24% за весь тест
- Seq Scan: Нестабильная производительность с периодами восстановления
Критические выводы
Для коротких сессий:
- Index Only Scan предпочтительнее - стабильная производительность
- Среднее преимущество: 8-12%
Для длительных нагрузочных тестов:
- Seq Scan демонстрирует лучшую выносливость в финальной фазе
- Index Scan подвержен постепенной деградации
Возможные причины аномалии:
- Кэширование данных: Seq Scan выигрывает от прогретого кэша
- Фрагментация индексов: Index Scan требует обслуживания
- Конкуренция за ресурсы: Различные паттерны доступа к памяти
- Параллелизм: Разная масштабируемость методов
Анализ расхождений между прогнозом и экспериментальными результатами
Проанализируй и сделай вывод о главных причин почему прогноз о производительности методов Seq Scan и Index Only Scan не был подтвержден в ходе экспериментального нагрузочного тестирования.
Главные причины несоответствия прогноза:
1. Эффект кэширования и прогрева данных
Прогноз: Ожидалась линейная деградация Seq Scan под нагрузкой
Реальность: Seq Scan выиграл от прогретого кэша БД
- При повторяющихся запросах данные остаются в shared_buffers
- Index Scan требует дополнительных обращений к страницам индекса
- Вывод: Прогноз не учитывал эффект кэширования при длительной нагрузке
2. Конкуренция за ресурсы индекса
Прогноз: Index Only Scan должен масштабироваться линейно
Реальность: Деградация производительности Index Scan под нагрузкой
- Высокая конкуренция за страницы B-дерева индекса
- Блокировки при одновременном доступе к индексным страницам
- Вывод: Прогноз недооценил contention в индексных структурах
3. Параллельная обработка vs. Последовательный доступ
Прогноз: Параллельный Seq Scan создаст чрезмерную нагрузку
Реальность: Параллелизм оказался эффективнее под нагрузкой
- Workers в Seq Scan равномерно распределяют нагрузку
- Index Scan создает точечную нагрузку на конкретные индексные страницы
- Вывод: Распределенная нагрузка оказалась стабильнее концентрированной
4. Накладные расходы обслуживания индекса
Прогноз: Index Only Scan = минимальные затраты
Реальность: Скрытые затраты на поддержание целостности индекса
- MVCC-механизм для индексов
- Дополнительные проверки видимости
- Вывод: "Only Scan" не означает "нулевые накладные расходы"
5. Особенности работы с памятью под нагрузкой
Прогноз: Seq Scan исчерпает память
Реальность: Эффективное использование shared_buffers
- PostgreSQL эффективно управляет кэшем
- Seq Scan использует стратегию последовательного чтения
- Вывод: Алгоритмы управления памятью оказались эффективнее ожиданий
6. Влияние планировщика запросов
Прогноз: Статическая оценка стоимости
Реальность: Динамическое перераспределение ресурсов
- Планировщик адаптируется к текущей нагрузке
- Изменение стратегии выполнения в реальном времени
- Вывод: Живая система сложнее статических моделей стоимости
Критические выводы для будущих прогнозов:
Ошибочные предположения в исходном прогнозе:
- Недооценка эффективности кэширования
- Переоценка масштабируемности индексного доступа
- Неучет конкуренции за индексные структуры
- Игнорирование адаптивных возможностей СУБД
Рекомендации по нагрузочному тестированию:
- Тестировать на прогретой БД - учитывать эффект кэширования
- Моделировать реальный contention - не только изолированные запросы
- Учитывать длительность теста - производительность меняется со временем
- Мониторить contention в индексах - pg_stat_all_indexes
Финальный вердикт
Прогноз основывался на упрощенной модели, не учитывающей динамическое взаимодействие компонентов СУБД под реальной нагрузкой. PostgreSQL продемонстрировал лучшую адаптивность и эффективность управления ресурсами, чем предполагалось статическим анализом планов запросов.