Ключевые метрики мониторинга
Чтобы держать руку на пульсе системы и вовремя принимать решения по работе инфраструктуры, необходимо отслеживать ряд параметров.
Состояние оборудования. Контроль температуры и энергопотребления — важные метрики работы серверов. Сбой в системе охлаждения и иные факторы могут вывести оборудование из строя.
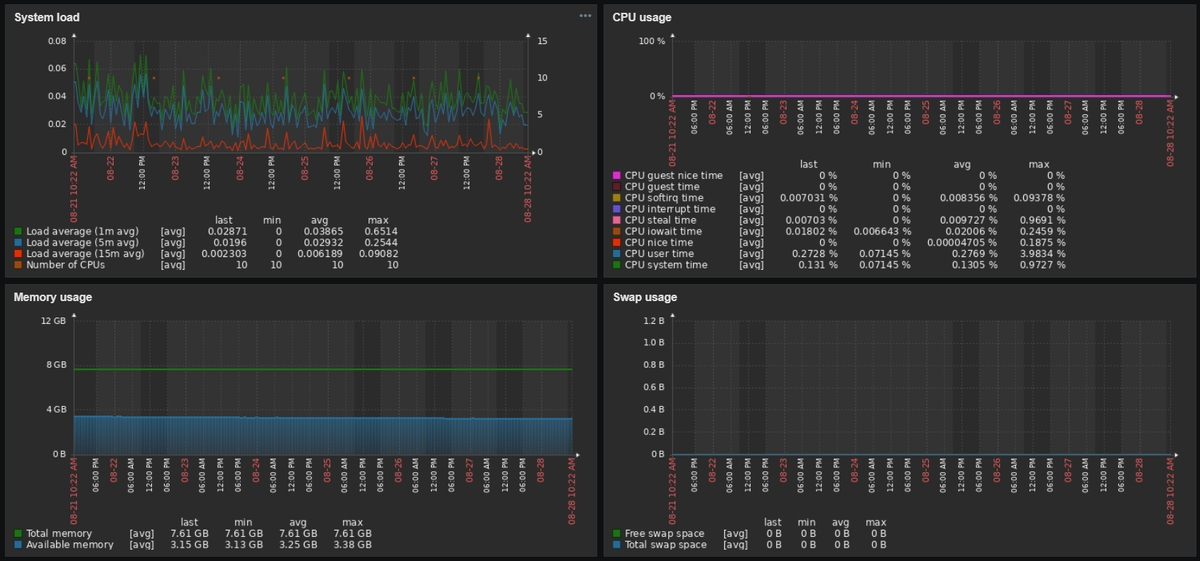
Использование CPU. Центральный процессор — мозг всей IT-инфраструктуры. От степени его загрузки зависит скорость обработки запросов. Отслеживание показателей CPU позволяет определить, какие задачи и в какое время потребляют больше всего процессорного времени. Сориентироваться помогают несколько важных метрик:
- Текущая загрузка отражает реальное положение дел;
- Пиковая — показывает, как система справляется с самыми напряженными ситуациями;
- Средняя — отображает среднее значение нагрузки за последние 1, 5 или 15 минут.
- Uptime — время непрерывной работы сервера.
Объем RAM. Нехватка оперативной памяти серьезно снижает работоспособность системы и замедляет серверные задачи. Мониторинг доступного объема ОЗУ поможет своевременно оптимизировать нагрузку, отключить определенные процессы или же увеличить запас оперативной памяти.
Uptime. Используется для отслеживания периодов доступности. Может отображать количество дней бесперебойной работы или выражаться в процентах. Во время технических работ сервер обычно отдыхает. Поэтому, даже если с системой всё хорошо, uptime может составлять, например 99,95%.
Дисковое пространство. Важно учитывать свободное место на диске, чтобы при необходимости его вовремя расширить, а также отслеживать и другие параметры. Диагностика состояния дискового пространства и скорости чтения и записи поможет своевременно выявить и устранить неисправности.
Доступность сети. Чтобы ресурс стабильно работал, и посетители могли использовать его различные функции, необходимо следить за техническими показателями обмена информацией. Например, за скоростью передачи входящего и исходящего трафика, уровнем задержи при отправке запросов серверу, а также различными сетевыми ошибками.
Состояние серверных элементов. Благодаря мониторингу можно всегда оставаться в курсе ключевых событий на сервере. Например, следить за логом ошибок, чтобы оперативно исправлять различные сбои. Или вовремя заметить и устранить снижение производительности базы данных.
Метрики работы СУБД MySQL:
Пример метрик работы системы кэширования Memcached:
Также нужно отслеживать метрики работы самих онлайн-проектов: сайтов, приложений и других сервисов.
- Время отклика (Response time) — важный критерий производительности, который показывает, как быстро обрабатывается запрос.
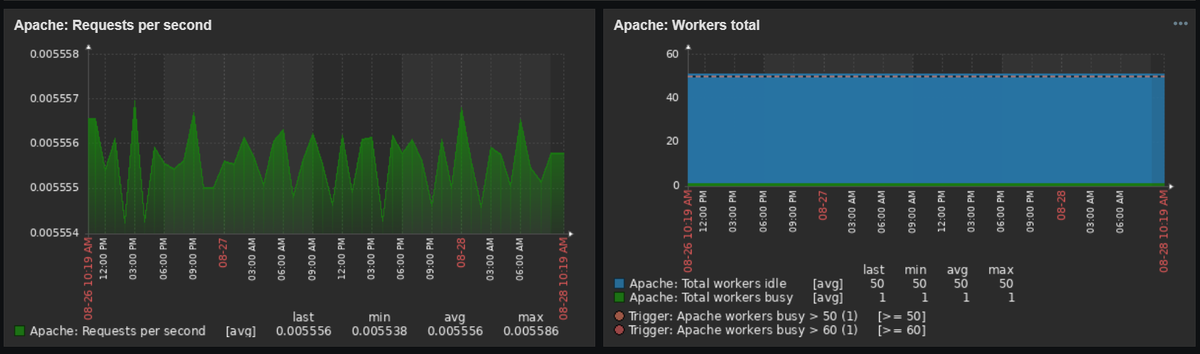
- Количество запросов в секунду (RPS). Даже небольшой сайт может одновременно посещать около 100 пользователей. И каждое их действие на ресурсе — это запросы к серверу. А чем выше пропускная способность сайта, тем с большей нагрузкой он сможет справиться.
- Пользовательский опыт. Например, стандарт Apdex (Application Performance Index) помогает предположить удовлетворенность скоростью работы приложения. Для этого нужно соотнести нормы загрузки страниц с тем, как быстро они открываются у пользователей в реальности.
- Crash rate — метрика, которая отображает, какой процент сессий завершился сбоями, например аварийным закрытием приложения.
- Время загрузки — скорость, с которой страница загружается в интерфейсе пользователя после клика по ссылке. Включает как время отклика сервера, так и длительность отрисовки контента. К скорости загрузки страниц внимательно относятся и пользователи, и поисковики.
Преимущества мониторинга IT-системы
IT-инфраструктура онлайн-проекта включает множество программных, аппаратных и сетевых элементов. И чтобы сайт или приложение быстро работали, а посетителям было комфортно пользоваться ресурсом, необходимо следить за состоянием системы. В этом помогут Zabbix, Prometeus и другие системы мониторинга. И их использование обеспечит проекту следующие преимущества.
Улучшение пользовательского опыта. Контроль за различными метриками помогает оперативно устранять сбои. За счет этого можно избежать финансовых потерь при длительном времени простоя. А оптимизация нагрузки и другие своевременные шаги улучшают скорость и доступность сервисов и, как следствие, пользовательский опыт.
Повышение производительности. Чем больше мощностей требуется ресурсу, тем выше будет нагрузка на серверы. Особенно это актуально для проектов с активным масштабированием. Например, можно вовремя оптимизировать настройки сервера, чтобы улучшить скорость, стабильность и эффективность его работы при росте числа пользователей или увеличении объема данных.
Помощь в планировании. Мониторинг позволяет заранее узнать о достижении лимита мощностей, чтобы вовремя расширить производительность инфраструктуры и избежать непредвиденных последствий. Благодаря подобным сервисам и системам можно заранее спланировать апгрейд инфраструктуры, например миграцию в облако.
Сокращение расходов. Системы мониторинга помогают определить, какие процессы или элементы инфраструктуры потребляют больше всего ресурсов, а какие и вовсе — простаивают впустую. Например, можно выявить неэффективно используемый сервер и сократить расходы на его обслуживание. А еще — оптимизировать издержки на исправление последствий после сбоев.
Как обеспечить мониторинг серверам и всей инфраструктуре?
У нас есть решения для обеспечения стабильной работы проектов любой сложности и масштаба.
В рамках услуги администрирования опытные системные инженеры обеспечат круглосуточный мониторинг ваших серверов. Услуга включает контроль за доступностью ресурсов, отслеживание и предотвращения сбоев. Мы настроим резервное копирование и предоставим для бэкапов от 250 Гб в зависимости от выбранного тарифа.
А если вам необходимо отслеживать состояние всей IT-инфраструктуры, воспользуйтесь нашей услугой IT-аутсорсинга. Например, мы настроили для одного проекта мониторинг на системе Zabbix. И для реализации этого кейса выполнили ряд шагов.
- Поставили на мониторинг серверы, СХД, коммутаторы, ОС приложения, поддерживающие сервисы и само приложение клиента.
- Развернули и настроили Zabbix, подключили алертинг и визуализировали вывод дашбордов.
- Оптимизировали шаблоны для всех элементов инфраструктуры. Для этого исключили ненужные метрики, настроили критически важные и определили их пороговые значения.
- В результате клиент получил возможность отслеживать доступность инфраструктуры с определением SLA сервиса.
При этом наши специалисты могут установить и множество других систем мониторинга, включая Nagios, Prometeus (PGL), Elasticsearch (ELK, EFK), Munin и Monitorix.
Мы работаем с широким стеком технологий и помогаем создать с нуля или оптимизировать IT-систему индивидуально под ваш запрос. В рамках DevOps-сопровождения настраиваем Docker, Kubernetes, Terraform и прочие платформы. А для решения задач CI/CD работаем с Jenkins, Gitlab CI, GitHub Actions и другими системами.
Больше решений для вашего проекта
Любой формат размещения. Предоставляем виртуальный хостинг, облачные и выделенные физические серверы. Работаете с персональными данными? Разместим ваш проект в аттестованном контуре.
Индивидуальные решения. По вашему запросу построим инфраструктуру с размещением в любой локации. Создадим частное облако. Построим отказоустойчивый кластер для всей системы или отдельных элементов, например баз данных.
Защита ресурсов. Высокая доступность инфраструктуры тесно связана с ее кибербезопасностью. Поэтому мы предоставляем собственное SaaS-решение для защиты от взломов, утечек данных и кибератак. А специалисты нашего центра кибербезопасности обеспечат мониторинг, предотвращение и расследование киберинцидентов.
Мониторинг облачной инфраструктуры. Уже размещаетесь в нашем облаке? Подключайте мониторинг виртуальной инфраструктуры в пару кликов и следите за всеми показателями системы в личном кабинете. А также настраивайте и получайте уведомления при достижении пороговых значений для различных метрик.