NVIDIA подробнее рассказала о своём новейшем графическом процессоре Blackwell Ultra. Графический процессор создавался для ускорения рабочих нагрузок, связанных с обучением и логическими выводами искусственного интеллекта (ИИ) в крупномасштабных средах, которые в NVIDIA называют ИИ-фабриками.

Источник изображения: Logan Voss, Unsplash
Графический процессор Blackwell Ultra состоит из двух кристаллов с размерами, близкими к пределам фотолитографической маски, но при этом функционирует как единый ускоритель, программируемый с помощью NVIDIA CUDA. Кристаллы сообщаются посредством интерфейса NVIDIA High-Bandwidth Interface (NV-HBI) с пропускной способностью до 10 ТБ/с. Производится графический процессор на мощностях TSMC по специально оптимизированной для NVIDIA технологии 4NP.
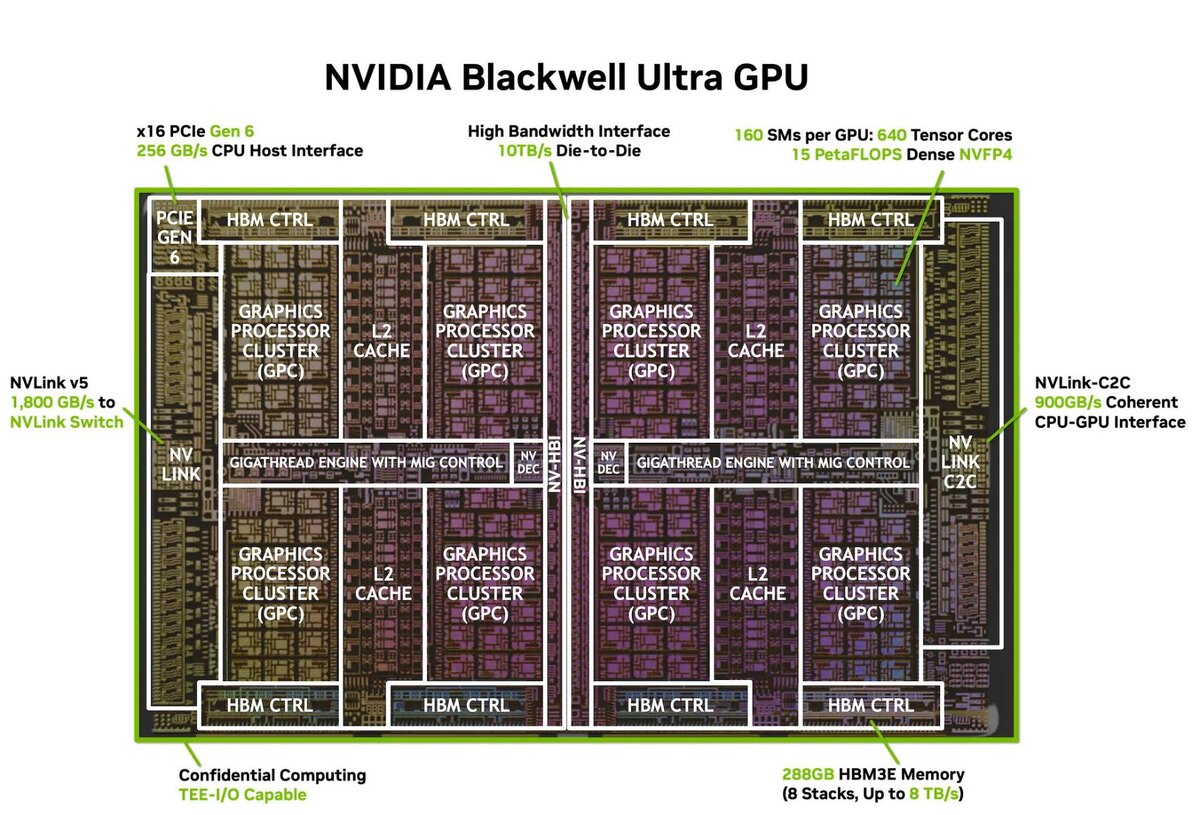
Основные блоки NVIDIA Blackwell Ultra. Источник изображения: NVIDIA
Blackwell Ultra содержит 208 млрд транзисторов, 8 графических кластеров (Graphics Processing Cluster, GPC), каждый из которых в полной конфигурации объединяет 160 потоковых мультипроцессоров (Streaming Multiprocessors, SM). Каждый SM является автономным вычислительным блоком. В случае с Blackwell Ultra в состав каждого такого блока входит 128 CUDA ядер, 4 тензорных ядра пятого поколения, 256 КБ тензорной памяти (Tensor Memory, TMEM) и специальные функциональные блоки (Special Function Unit, SFU) для трансцендентной математики и особых операций, связанных с ИИ.
Потоковый мультипроцессор NVIDIA Blackwell Ultra. Источник изображения: NVIDIA
Всего в Blackwell Ultra насчитывается 20480 CUDA ядер и 640 тензорных ядер пятого поколения. Производительность тензорных ядер NVIDIA оценивает в 15 петафлопс при использовании чисел формата NVFP4 — в 1,5 раза выше, по сравнению с Blackwell. NVFP4 — это новый формат, поддержка которого впервые появилась в архитектуре Blackwell. Используя преимущества новых тензорных ядер формат NVFP4 обеспечивает точность, практически эквивалентную FP8, сокращая объем используемой памяти примерно в 1,8 раза. NVIDIA называет NVFP4 оптимальным форматом для низкоточного вывода ИИ.
В Blackwell Ultra память TMEM поддерживает двухпоточную блочную обработку операций умножения матриц с одновременным добавлением (Matrix Multiply-Accumulate, MMA), когда парные SM взаимодействуют в рамках одной операции. Удвоена пропускная способность SFU для инструкций, имеющих ключевое значение для ускорения механизма внимания в моделях-трансформерах, особенно для рассуждающих моделей с большим контекстным окном, где этап Softmax может стать узким местом для задержки. Также используется Transformer Engine второго поколения с более высокой пропускной способностью и меньшей задержкой.
Графический процессор оснащается 288 ГБ памяти HBM3e с общей шиной 8192 бит и общей пропускной способностью 8 ТБ/с. Такой огромный объём памяти позволяет размещать модели с количеством параметров более 300 млрд, значительно увеличивать длину контекста.
Среди прочего: поддержка NVIDIA NVLink пятого поколения для связи между графическими процессорами (1800 ГБ/с), NVLink-C2C для взаимодействия с центральным процессором NVIDIA Grace (900 ГБ/с) и интерфейс PCIe Gen6 x16 для подключения к центральным процессорам (256 ГБ/с). Новые ускорители эффективнее, поддерживают новые функции корпоративного уровня, обеспечивают повышенную безопасность и надёжность — подробнее в техническом блоге NVIDIA.



















