В прошлый раз я говорил, что мы можем любой термин закодировать так, чтобы его смысл можно было понять по конкретным значениям семантических параметров. Если при описании какого-то человека параметр пола у нас 10, то речь явно о мужчине. Если параметр “власти” на нуле, то речь о какой-то прислуге или даже рабе. Допустим, значение 20 у параметра “волосы” говорит об их длине. И дальше в этом духе. Мы можем одним вектором описать все значимые характеристики любого понятия, объекта или действия.
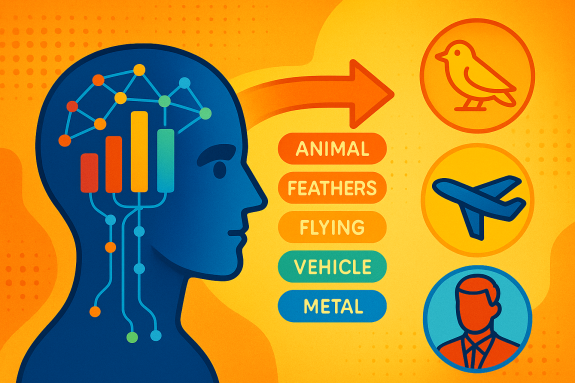
Но в каждом тексте под одним и тем же словом могут понимать совершенно разные вещи. В литературном произведении самолёт могут назвать птицей, иногда снабдив его эпитетом “стальной”. Но из самого текста должно быть понятно, о чём именно речь. Некоторый сервис начинает читать текст, выделяет в нём отдельные объекты, затем в рамках доступной информации выделяет всю суть и контекст этих понятий, обогащая некоторый семантический вектор. Сначала он увидит слово “птица”, внесёт параметры “животное”, “перья”, “летающее” и так далее. Затем по ходу чтения он поймёт, что это не животное, а самолёт, изменив исходные параметры на “самолёт”, “стальной” и так далее. И концу повествования у нас сложится чёткое понимание, о чём идёт речь. Ровно такая процедура будет проведена с каждым объектом, с каждым действием над этим объектом, а также с отношениями между ними.
Мышление категориями
Все такие формальные выражения могут быть записаны в виде так называемых Compressed Semantic Token (CST). Они должны быть стандартизированы для каждой области знаний. С литературными вопросами это будет провернуть сложно в силу тонкостей повествования и часто неуловимого смысла. Но в технических областях мы от этого свободны. Потому нет уж очень большой сложности, чтобы сформулировать исчерпывающий набор параметров понятий из, например, электродинамики. А если мы вдруг поймём, что собрали не всё, то просто добавим новый параметр, который будет пустым у части терминов.
Вместо того, чтобы “думать” словами, нейронная сеть сможет оперировать строго заданными понятиями, которые лишены проблем двоякой, а то и троякой трактовки. Если мы написали “сопротивление”, то должен быть явным образом указан контекст. Это сопротивление электрической цепи, как отдельный радиоэлемент. Никакого психологического или военного сопротивления. Никаких дополнительных шумов. Только строгие чистые понятия, лишённые всякой неоднозначности.
Это даёт нам возможность не запоминать кучу разных векторов слов со сложными взаимоотношениями между ними, которые в современных нейронных сетях называют Attention. Мы можем оперировать “чистыми” понятиями, обучая модели именно на них, а не на часто неполном и неоднозначном наборе слов, который может для каждого языка быть разным.
Единые правила игры
Такой подход решает очень важную системную задачу - стандартизация интерфейсов. Вопрос перевода текстов из слов в CST - это работа отдельного инструмента. Но если задача сформулирована в виде CST, то далее она решается универсальным инструментом, который знает, что делать. И этот инструмент будет решать поставленную задачу гораздо более эффективно и экономно, чем современные общие большие языковые модели. У нас чрезвычайно сильно экономится память из-за фактического отсутствия Attention-сегмента, а также есть инструмент, который обучался на строго заданных понятиях, где существенно снижаются искажение данных и галлюцинации, а также не нужно иметь сотни миллиардов параметров.
С помощью выделения семантических осей и стандартизации понятий из разных областей мы подготавливаем почву для дальнейшего строгого логического рассуждения. И эта задача тоже может быть решена нейронными сетями.
Оригинальная статья: https://zenodo.org/records/16901100