
Задача
Сравнить производительность СУБД расположенных в одной облачной среде на разных гипервизорах, гостевых ОС и разных версиях СУБД.
Предыдущие работы по теме
Конфигурации ВМ
Виртуальная машина 06
- CPU = 2
- RAM = 2GB
- Astra Linux 1.7
- PostgreSQL 15
Виртуальная машина 12
- CPU = 8
- RAM = 8GB
- Red OS Murom 7.3
- PostgreSQL 17
Конфигурация СУБД
Виртуальная машина 06
Параметры по умолчанию
Виртуальная машина 12
Параметры по умолчанию + shared_buffers = 2GB
Сценарий тестирования и нагрузка на СУБД
Mix
- Select only : 50% нагрузки
- Select + Update : 30% нагрузки
- Insert only : 15% нагрузки
Нагрузка
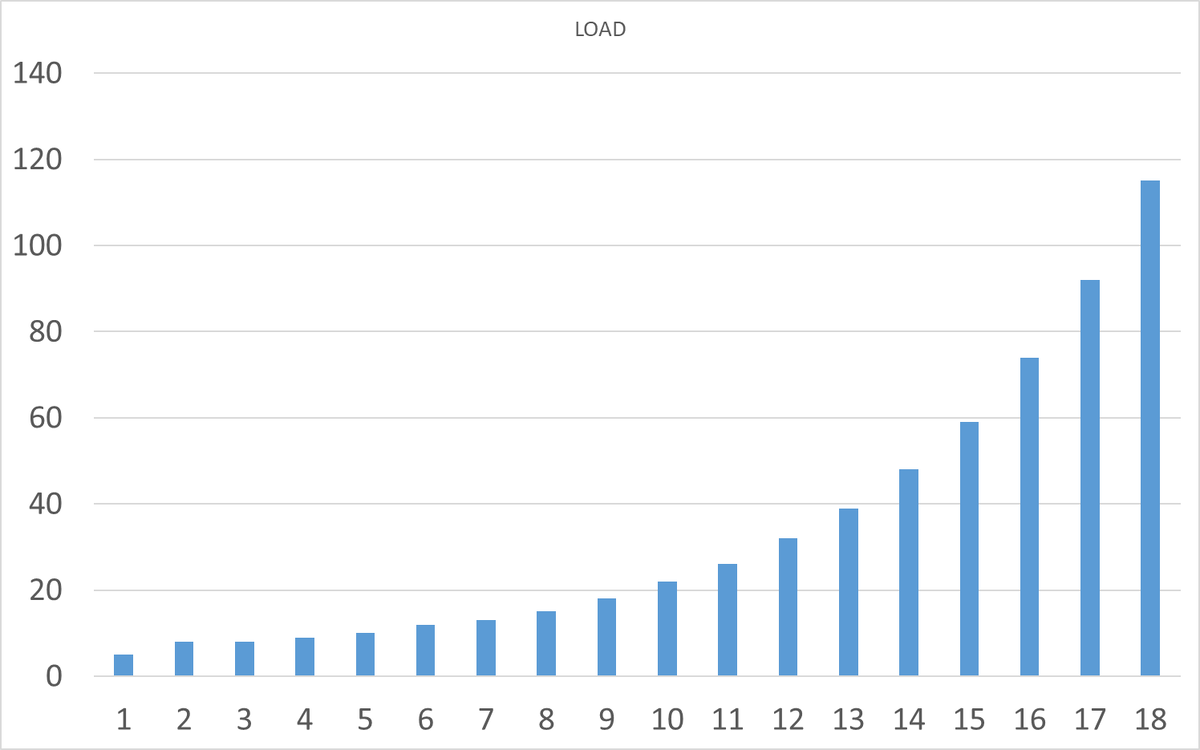
Результаты нагрузочного тестирования
Зависимость операционной скорости от нагрузки на СУБД
Среднее снижение операционной скорости в эксперименте-12 составило 46%.
Операционная скорость
Среднее снижение операционной скорости в эксперименте-12 составило 45.07%.
Ожидания СУБД
Среднее увеличение ожидания в эксперименте-12 составило 58%.
Итог
- Ожидания СУБД для "виртуальной машины 12" кардинально возросли.
- Производительность СУБД в "виртуальной машины 12" кардинально снизилась.
Гипотеза о причинах более низкой производительности "Виртуальной машины 12"
Парадокс, когда более мощная ВМ ("Сильная СУБД") показывает вдвое худшую производительность PostgreSQL по сравнению с менее мощной ("Слабая СУБД"), требует глубокого анализа.
Ключевые направления для исследования:
Критические факторы, требующие немедленной проверки
Конкуренция за ресурсы гипервизора:
- "Шумные соседи": "Сильная ВМ" (8vCPU/8GB RAM) с большой вероятностью находится на физическом хосте с более высоким уровнем загрузки другими ВМ.
Проверка гипервизора во время тестов:
- CPU Steal Time (st в vmstat, sar, top на гипервизоре или через облачный мониторинг): Высокий st (>5-10%) указывает, что гипервизор отбирает CPU у вашей ВМ для других задач. Это главный подозреваемый.
- Дисковый I/O Latency: Общий латентный I/O на физическом диске/LUN из-за других ВМ убивает производительность СУБД. await (в iostat) на обеих ВМ. Высокий await на "Сильной" при низкой нагрузке от самой PostgreSQL - явный признак.
Конфигурация PostgreSQL (shared_buffers - Недооцененная проблема):
- shared_buffers=2GB на 8GB RAM - это МАЛО для "Сильной" ВМ: Это всего 25% RAM. По best practices для выделенных серверов БД рекомендуется 25-40% от общей RAM. На "Слабой" ВМ (2GB RAM) shared_buffers по умолчанию - всего 128MB (~6.25%), что неоптимально, но терпимо. На "Сильной" 2GB - это серьезная недооценка.
- Проблема: Ядро PostgreSQL не может кэшировать достаточно данных, полагаясь на кэш ОС. Red OS может иметь другие настройки кэша файловой системы, чем Astra Linux.
- vmstat 1 во время теста. Огромное количество страниц (si/so - swap in/out) или высокий wa (I/O wait) при низкой загрузке CPU (us+sy) - признак нехватки RAM для кэша.
- Решение: Увеличение shared_buffers до 3-3.5GB на "Сильной" ВМ. Это первое, что нужно сделать!
Конфигурация ОС (Red OS vs Astra Linux):
- Настройки виртуальной памяти (VM): Значения vm.dirty_*, vm.swappiness по умолчанию в Red OS могут быть существенно хуже для СУБД, чем в Astra Linux (которая часто оптимизируется для гос. задач и может иметь лучшие дефолты для серверов).
- sysctl -a | grep vm.dirty и sysctl -a | grep vm.swappiness на обеих ВМ. swappiness=60 - стандарт, но для СУБД часто ставят 1 или 10. Высокие dirty_background_ratio/bytes и dirty_ratio/bytes могут вызывать лавинообразную запись "грязных" страниц, блокируя работу.
- Настройки I/O Scheduler: Разные дистрибутивы используют разные шедулеры по умолчанию (deadline, cfq, noop, mq-deadline). Для виртуализированных блочных устройств (особенно в облаке) none или noop часто лучше, чем cfq.
- cat /sys/block/[xv]d[a-z]/queue/scheduler (активный помечен []).
- HugePages: Включены ли? Настроены ли правильно под PostgreSQL? (См. postgresql.conf - huge_pages, вывод grep Huge /proc/meminfo).
- VM и I/O на Red OS в соответствие с best practices для PostgreSQL. Начать с swappiness=1, dirty_background_bytes=67108864 (64MB), dirty_bytes=536870912 (512MB). Проверьте и настройте HugePages.
Версия PostgreSQL (15 vs 17):
- Деградации: Хотя 17 обычно быстрее, в конкретных сценариях или на определенном железе могут быть регрессии. Провить release notes 17 на предмет известных проблем с производительностью.
- Различия в дефолтных настройках: Некоторые параметры могли изменить значения по умолчанию между версиями. Сравнить postgresql.conf обеих версий (особенно effective_cache_size, work_mem, max_parallel_workers_per_gather, настройки автоанализа/автовакуума, wal-настройки). effective_cache_size на "Сильной" ВМ должно быть ~6GB (75% RAM), а не значение по умолчанию.
- Временно установите PostgreSQL 15 на "Сильную" ВМ" с всеми остальными параметрами (ОС, RAM, CPU) неизменными. Если производительность придет в норму - проблема в версии 17 или ее конфигурации.
Work_mem и Параллельные Запросы:
- work_mem по умолчанию (4MB) на ВМ с 8 ядрами: PostgreSQL 17 активнее использует параллельные запросы. При большом количестве одновременных сессий и сложных сортировках/хеш-агрегациях суммарное потребление work_mem может превысить доступную RAM, вызывая своппинг. На "Слабой" ВМ с 2 ядрами параллельных запросов почти не будет, и эта проблема не проявится.
- Логи PostgreSQL на наличие сообщений о временных файлах (LOG: temporary file: path...). Мониторинг pg_stat_database (temp_files, temp_bytes). Наблюдайте за использованием RAM и свопом во время теста.
- Увеличить work_mem (например, до 8-16MB), но уменьшите max_parallel_workers_per_gather (например, до 2-4)
Другие важные моменты
- Дисковый ввод/вывод: ВМ используют абсолютно одинаковый тип дискового хранилища (SSD? Network-attached? Локальный?) с одинаковыми лимитами IOPS/пропускной способности. Протестируйте raw I/O (fio) на обеих ВМ.
- Статистика выполнения: log_min_duration_statement = 0 или используйте pg_stat_statements, auto_explain для анализа медленных запросов на обеих ВМ. Сравните планы выполнения одинаковых запросов (EXPLAIN ANALYZE).
Мониторинг во время теста: Обязательно собирайте на обеих ВМ во время тестов:
- vmstat 1 (CPU, память, I/O, swap)
- iostat -x 1 (дисковый I/O: %util, await, svctm)
- pidstat или top -H (потребление CPU/памяти отдельными потоками PostgreSQL)
- dstat -n (сеть)
- sar (общая статистика)
- free -m (использование памяти/свопа)
- pg_stat_activity, pg_stat_database, pg_stat_bgwriter
Рекомендуемый порядок действий:
- Проверьте "Шумных соседей" и Steal Time: Это самая вероятная причина в облаке. Если st высокий - проблема в окружении VK Cloud.
- Увеличьте shared_buffers на "Сильной" ВМ до 3-3.5GB.
- Приведите настройки VM ОС (Red OS) в порядок: swappiness, dirty_*, I/O scheduler, HugePages.
- Настройте effective_cache_size на "Сильной" ВМ (~6GB).
- Проанализируйте work_mem и параллельные запросы: Уменьшите параллельность, увеличьте work_mem осторожно.
- Сравните raw I/O производительность (fio).
- Попробуйте PostgreSQL 15 на "Сильной" ВМ".
- Тщательно сравните статистику мониторинга с обеих ВМ во время идентичных тестовых прогонов.
Основная гипотеза:
Комбинация конкуренции за ресурсы гипервизора (особенно CPU Steal) на более мощной ВМ + недостаточно настроенные shared_buffers и параметры ОС (Red OS) + потенциальные проблемы с параллелизмом в PG17 привела к тому, что дополнительные ресурсы "Сильной" ВМ не могли быть эффективно использованы, а накладные расходы на управление ими и конкуренция ухудшили производительность.