Предыдущая часть:
Осталось решить проблему определения наличия буквы в слове.
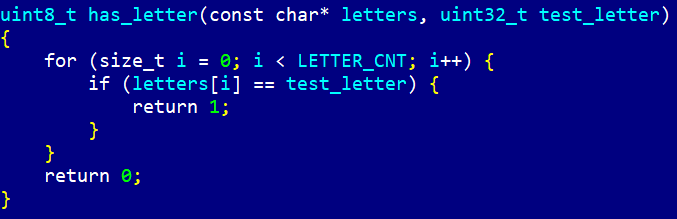
Это может показаться легко: если в слове есть буква, то она есть, что ещё надо? Напомню код функции has_letter():
Но букв может быть больше одной. Например, загадано слово ОСЕНЬ, а мы ввели ПОРОГ. В нашем слове есть две буквы О, а в загаданном одна буква. Кроме того, в нашем слове буквы О стоят не на правильных местах. Что мы должны показать в этом случае?
ПОРОГ
x-xxx
Данная схема говорит, что первая буква О стоит не на своём месте, а второй буквы О нет. Или надо по-другому?
ПОРОГ
xxx-x
Первой буквы О нет, а вторая стоит не на своём месте? В принципе без разницы, это не меняет решения.
Но что произойдёт в текущей реализации?
ПОРОГ
x-x-x
Для первой О она вернёт наличие, и для второй О тоже. Мы получим ответ, что две буквы О стоят не на своих местах, хотя в загаданном слове есть только одна.
Следовательно, функция проверки наличия буквы должна каким-то образом помнить, какие буквы уже проверялись.
Для этого мы можем посчитать, сколько раз встречается в слове каждая буква. Можно сделать это с помощью структуры:

Т.е. хранить букву и счётчик.
А можно сделать lookup-таблицу для всех букв алфавита:
uint8_t letter_cnt[33];
Памяти практически не ест, а пользоваться проще и поиск быстрее. Букв 32, но их коды начинаются с 1, поэтому нулевой индекс массива не используется, и его общий размер становится 33.
Для начала надо разобрать загаданное слово по буквам и по индексу каждой буквы инициализировать счётчик в таблице:
Далее в функцию has_letter() можно передавать уже не буквы слова, а эту таблицу:
Ну и теперь можно совсем отказаться от функции has_letter(), так как она эквивалентна одному запросу в lookup-таблицу.
Проверяя наличие буквы в слове, мы просто смотрим в таблицу: если счётчик не равен нулю, то буква в слове есть. И тогда мы уменьшаем счётчик на 1. Если потребуется проверить ещё одну такую же букву, счётчик покажет, сколько их осталось.
Но радоваться рано. Предположим, в слове есть одна буква O: СЫРОК. А мы ввели ОТВОД.
Тогда, проверяя буквы, мы определим, что первая О стоит не на своём месте, и обнулим счётчик для О, так как она одна. Но после этого мы дойдём до второй буквы О, которая стоит на своём месте. Но так как счётчик уже обнулён, то результатом будет, что вторая буква О отсутствует. Формально это так, но нам нужно, чтобы буква, стоящая на своём месте, была приоритетнее остальных.
Придётся переделать функцию проверки слова.
При инициализации счётчиков букв я сразу проверяю, не совпадают ли буквы в словах. Если совпадают, сразу ставлю им статус OK_LETTER, а в счётчики их не заношу – они уже посчитаны.
Оставшие проверки проверяют букву, только если она ранее не совпала.
Правильный random
Хотелось бы исправить ещё один момент. Генерация случайного номера слова происходит следующим образом:
Это пропорция, которая отображает диапазон значений rand() от 0 до RAND_MAX (типично 0..65535) на диапазон индексов массива слов от 0 до word_cnt - 1 (сейчас у нас 0..9). Значит на каждое значение из диапазона 0..9 приходится пропорциональное количество значений из диапазона 0..65536, это 6553.6.
Кроме самого последнего. Чтобы получить 9, нужно чтобы выпал ровно RAND_MAX. Если выпадет хотя бы RAND_MAX - 1, мы получим 8.999..., которое округлится до 8.
Как такового округления тут нет, просто отбрасывается дробная часть числа. Из-за этого получается, что выпадение 9 имеет шансы в тысячи раз ниже, чем у остальных.
Модифицируем формулу так:
rand_index = rand() * word_cnt / (RAND_MAX + 1);
Вместо диапазона 0..9 используем диапазон 0..10, но 10 никогда не будет достигнуто, так как rand() / (RAND_MAX + 1) всегда будет меньше 1.
Следовательно, мы в пределе получим дробь 9.999..., но за счёт отбрасывания дробной части у нас и получится искомое 9, у которого будут равные шансы с другими.
Хранение слов
В прошлой части я описал построение дерева из слов и поиск по нему. По дереву можно найти слово, но нельзя выбрать из него слово с произвольным индексом – они должны храниться в массиве. Поэтому нужно держать и дерево для поиска, и массив для выборки.
На это я уже идти не хочу, поэтому дерево оставлю как отдельный пример (оно так и сделано) и в игру включать не буду. Поиск слова будет осуществляться тупо перебором массива, как и предлагалось ранее.
Сам массив, однако, можно оптимизировать. Строки в файле хранятся в кодировке UTF-8, это по 2 байта на символ, но при чтении я могу их преобразовывать во внутренний 1-байтный формат. И так как все слова 5-буквенные, мне даже не надо держать их в массиве как строки с нулевым байтом окончания. Это будут структуры InputWord. И как я ранее говорил, пора их переименовать, так как они используются уже не только для ввода слов:
Объединю в одну структуру массив слов (представлен как указатель на выделенную память) и счётчик слов, чтобы они были вместе:
Добавлю в начало файла со словами количество строк в нём, чтобы можно было выделить память:
Теперь откроем файл, прочитаем количество строк, выделим память и прочитаем слова в массив:
Примитивный поиск слова перебором:
Теперь перед проверкой слова нужно найти его в хранилище, и если не нашлось, то просить пользователя ввести слово повторно.
А вот я случайно угадал слово МИКСТ (не знал, что оно есть, но по структуре больше ничего не подходило)
Полный текст программы: