Дисклеймер
Планировал написать средних размеров статью, а получилось вот это.. Кажется, что всех основных важных аспектов коснулся. Надеюсь будет не скучно.
Статья является сокращенной выжимкой курса по распилу монолита для корп. универа IBS, который на момент выхода татьи готовиться к выходу. настоятельно советую примотреться к курсам IBS.
Введение.
Разработка программного обеспечения — это процесс, состоящий из последовательных этапов, таких как планирование, проектирование, реализация, тестирование и сопровождение (в рамках SDLC или более защищённого варианта — SSDLC). На каждом из этих этапов могут возникать сложности, требующие тщательной проработки. Архитектурные решения, принимаемые на ранних стадиях, являются одними из самых ресурсозатратных: они требуют значительных интеллектуальных и временных вложений, а ошибки, допущенные на этом уровне, могут оказаться чрезвычайно дорогими в исправлении. Тем не менее, и этап тестирования — quality assurance (QA) — также способен стать узким местом, особенно если подход к нему не выстроен системно. Как и другие этапы разработки, тестирование требует баланса между затратами, временем и качеством результата. Важно понимать, что невозможно протестировать всё: необходимо выбирать, что и на каком уровне следует проверять, исходя из критичности, риска и бизнес-ценности.
Особое значение тестирование приобретает в условиях микросервисной архитектуры. Этот стиль построения систем предполагает высокую степень модульности, распределённости и независимости компонентов. Он требует не только изменения подхода к проектированию и развертыванию, но и радикального пересмотра процессов тестирования. В микросервисной среде тестирование должно учитывать особенности взаимодействия между сервисами, стандартизацию интерфейсов, независимость релизов и необходимость обеспечения отказоустойчивости на уровне всей системы. В этой статье мы подробно рассмотрим, как тестирование встраивается в микросервисную архитектуру, какие типы тестов применяются, как они соотносятся с архитектурными решениями и какие паттерны позволяют выстроить эффективную, устойчивую и масштабируемую практику контроля качества в распределённых командах разработки.
Смысловая составляющая.
Цель тестирования — не в достижении абсолютного, стопроцентного качества программного продукта, а в том, чтобы обеспечить ожидаемый уровень надёжности, соответствующий целям и требованиям бизнеса. Это означает, что задача QA не в том, чтобы устранить все возможные ошибки, а в том, чтобы обеспечить контроль над рисками и подтвердить соответствие системы заданным критериям. Иными словами, тестирование — это не поиск идеала, а проверка реалистичных ожиданий.
С точки зрения определения, тестирование — это процесс проверки требований. При этом важно подчеркнуть, что требования для тестирования формируются не из кода, а из архитектурных артефактов: спецификаций, схем, описаний интерфейсов и бизнес-сценариев. Код — это реализация, а не источник требований. Такая постановка вопроса смещает фокус QA-инженера с кода на дизайн: на то, что было задумано, спроектировано и согласовано до начала реализации.
Именно поэтому важен принцип транзита ответственности и подход design-first. Каждый артефакт, созданный на предыдущем этапе, должен быть полезен и применим на следующем — без дополнительных пояснений или переосмыслений. В контексте качества это означает, что архитектура и её артефакты должны быть структурированы так, чтобы QA-инженер мог интерпретировать их однозначно, понимать, что и как должно работать, и использовать эту информацию как основу для построения тестов — вручную или в автоматизированном виде.
В идеальной ситуации тестировщик, получив задачу на проверку функциональности, не должен обращаться ни к разработчику, ни к архитектору за пояснениями. Вся необходимая информация должна быть изложена в доступных, формализованных и согласованных источниках. Это не только повышает эффективность тестирования, но и снижает зависимость команды от "носителей знаний", минимизируя коммуникационные издержки и риски недопонимания.
Таким образом, можно сформулировать ключевой принцип: архитектура информационной системы должна быть устроена таким образом, чтобы обеспечивать возможность воспроизводимого и независимого тестирования, достаточного для достижения необходимого уровня надёжности и уверенности в работоспособности продукта.
Что мы тестируем?
Когда речь заходит о тестировании, важно понимать: проверке подвергается не просто «работает ли это», а насколько система соответствует сформулированным ожиданиям — функциональным, архитектурным и бизнесовым. В условиях ограниченных ресурсов — а в большинстве проектов именно такая ситуация — невозможно тестировать всё с одинаковой глубиной. Поэтому ключевая задача заключается в определении приоритетов: что критично, а что допустимо проверять выборочно или частично.
В основе такого подхода лежит понимание различий в значимости компонентов. Одни участки системы реализуют core-функциональность — ключевые сценарии, влияющие на основной бизнес-результат. Другие играют вспомогательную роль или обслуживают внутренние процессы. Очевидно, что core-компоненты должны тестироваться глубже и регулярнее, чем, например, элементы административного интерфейса. Но чтобы это было возможно, архитектура должна способствовать такой дифференциации — как минимум, обеспечивать модульность, ясные границы и слабую связанность между зонами ответственности.
Для этого важно реализовать архитектурную декомпозицию, обеспечивающую разделение обязанностей (separation of concerns) и минимизацию скрытых зависимостей. В микросервисной архитектуре это особенно критично: каждый сервис должен быть тестируем независимо, чтобы команды могли развиваться автономно и выпускать инкременты без необходимости ожидания других команд.
Ключевым ориентиром здесь становится риск-ориентированный подход. Не все части системы равноценны по рискам: модули, работающие с финансовыми транзакциями, авторизацией, персональными данными или внешними интеграциями, требуют более тщательной проверки и более частого тестирования — вне зависимости от того, входят ли они в «ядро» бизнес-логики.
Ещё один важный аспект — автоматизируемость как архитектурное качество. При проектировании интерфейсов, контрактов и взаимодействий необходимо учитывать, насколько просто эти элементы можно будет протестировать. Интерфейсы должны быть стабильными, легко мокируемыми, предсказуемыми. Это снижает стоимость автоматизации, упрощает встраивание тестов в пайплайны CI/CD и делает проверку повторяемой.
Также стоит помнить о рисках архитектурного расползания: когда один компонент начинает выполнять задачи, выходящие за его рамки. Это негативно сказывается не только на масштабируемости и сопровождении, но и на тестируемости: чем больше у компонента обязанностей, тем сложнее его изолировать и тем больше усилий требуется для создания тестов.
Таким образом, качество архитектурной проработки напрямую определяет возможности тестирования. Структурированная, атомарная архитектура позволяет проектировать более избирательную и эффективную QA-стратегию: где и как тестировать, на каком уровне автоматизировать, какие контракты фиксировать, и какие сценарии запускать в end-to-end проверках.
Такой подход не только упрощает реализацию тестов, но и создаёт основу для работы с метриками качества: определение уровней покрытия, выбор целевых сценариев, приоритизация автоматизации. Всё это позволяет выстроить систему тестирования как управляемый, повторяемый и измеряемый процесс — что особенно важно в масштабной микросервисной среде.
Стоимость/полезность различных типов тестов.
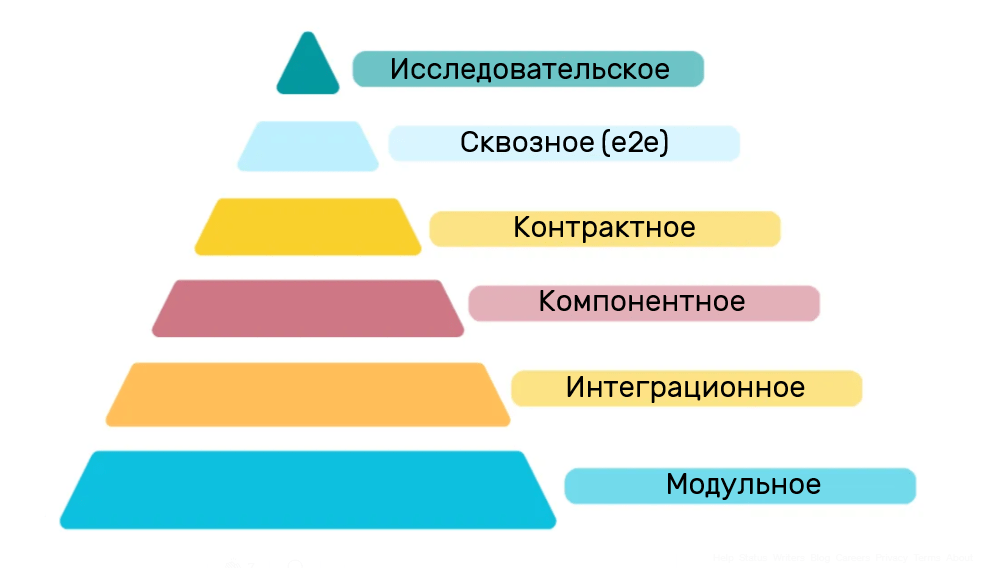
Одним из ключевых аспектов эффективного тестирования является осознанный выбор типов тестов, их соотношение и глубина. Наиболее распространённой моделью, описывающей это соотношение, является пирамида тестирования. Она предлагает простой принцип: чем ниже уровень теста (например, модульный), тем дешевле его реализация, выше скорость выполнения и проще сопровождение. Верхние уровни тестирования (например, end-to-end или UI-тесты), напротив, дают более широкий охват, но стоят дороже, сложнее в автоматизации и нестабильны по определению.
Однако важно понимать, что пирамида — это не жёсткая инструкция, а метафора баланса между затратами и выгодой. Например, баги в бизнес-логике могут быть легко выявлены на уровне модульных тестов, в то время как ошибки во взаимодействии сервисов или пользовательских сценариях проявляются только на более высоких уровнях. Поэтому нельзя ориентироваться только на количественные показатели (вроде покрытия кода), не учитывая масштаб и критичность багов, которые может выявить тот или иной тип тестов.
Также стоит учитывать, что сама пирамида описывает в первую очередь тесты внутри одного цикла разработки — например, спринта. Она не охватывает всю палитру возможных подходов к тестированию, таких как нагрузочное тестирование, тестирование потоков данных (data flow), проверку инфраструктуры, хаос-тестирование и прочие сложные сценарии. Эти виды проверок требуют иных инструментов и ресурсов, зачастую выходящих за рамки обычного CI/CD пайплайна.
С архитектурной точки зрения, каждый тип тестов предъявляет свои требования. Их нужно учитывать при проектировании: предусматривать изолируемость компонентов, возможность мокирования, стабильные контракты, наличие тестовых данных и управляемое состояние системы. Ниже мы подробно рассмотрим основные классы тестов, применяемые в микросервисной архитектуре, и то, как архитектура должна быть подготовлена к их использованию — как в ручном, так и в автоматическом виде.
Коротко пройдемся по типам тестов.
Smoke-тесты: проверка готовности к тестированию
Smoke-тестирование (также называемое sanity check или дымовое тестирование) — это первый и наиболее базовый тип проверки, проводимый после сборки и запуска приложения. Его задача — подтвердить, что система в принципе работоспособна и готова к более глубокому тестированию. Smoke-тесты не направлены на поиск багов в бизнес-логике, их цель — зафиксировать минимальный уровень «жизни» системы.
Для микросервисов это означает, что:
- сервис успешно собрался;
- запустился без фатальных ошибок;
- поднял интерфейсы (например, REST API или gRPC);
- подключился к необходимым зависимостям (например, БД или сервис-дискавери).
С точки зрения архитектуры, поддержка smoke-тестирования требует определённой подготовки, как в ручном тестировании, так и в автоматизированных пайплайнах.
В ручном режиме:
- Должна существовать инструкция по запуску сервиса в минимальной жизнеспособной конфигурации: как собрать, какие переменные окружения задать, как эмулировать зависимости.
- Необходимо явно задокументировать признаки «готовности» сервиса к тестированию: например, успешный запуск, доступность API, регистрация в системе обнаружения сервисов.
- Разработчик или QA-инженер должны иметь возможность проверить эти условия вручную.
В автоматизированной среде:
- Архитектура должна предусматривать readiness и liveness пробы (например, в Kubernetes), которые позволяют внешним системам понять, что сервис жив и готов к приёму трафика.
- Должны быть определены критерии успешного старта — например, ответ API на GET /health с кодом 200.
- Эти критерии интегрируются в пайплайн CI/CD как часть автоматической проверки сборки.
- Архитектура должна поддерживать быстрый деплой минимальной версии сервиса — в том числе через feature-флаги и другие средства изоляции незавершённого функционала.
Smoke-тесты не входят в тестовую пирамиду, поскольку не направлены на покрытие логики, но они являются обязательной точкой входа в любое серьёзное тестирование. Они критичны для быстрой диагностики: если упал smoke-тест, значит, нет смысла запускать более сложные проверки — система физически не готова.
Эффективное smoke-тестирование — это гарантия того, что среда работает, сборка прошла успешно, а тестировщик (или пайплайн) может переходить к следующим этапам контроля качества.
Unit-тесты: фундамент быстрой обратной связи
Модульные тесты (unit-тесты) проверяют поведение минимально тестируемых единиц кода — отдельных функций, методов или классов. Это самый «низкоуровневый» и в то же время самый быстрый и дешёвый тип тестов. Их главная цель — убедиться, что каждый отдельный компонент работает корректно в изоляции, вне зависимости от окружения или других компонентов системы.
Unit-тесты формируют основание тестовой пирамиды. Они обеспечивают быструю обратную связь: позволяют быстро выявлять ошибки в логике, предотвращают регрессии при рефакторинге, работают как форма документации. Особенно важны они в системах, активно развивающихся в параллельных потоках — как это часто бывает в микросервисной архитектуре.
Однако эффективность unit-тестирования во многом определяется тем, насколько архитектура поддерживает изоляцию и возможность контролировать окружение.
Архитектурные предпосылки для ручного тестирования:
- Поддержка инъекций зависимостей (Dependency Injection): тестируемый компонент должен позволять подставлять заглушки или моки вместо настоящих зависимостей. Это невозможно, если код плотно связан с конкретными реализациями или инфраструктурой.
- Документированная структура модулей: для ручного тестирования крайне полезно иметь описание публичных контрактов, понимание связей между компонентами и чёткое разграничение ответственности.
- Изолируемая логика: логика тестируемого модуля должна быть независимой от внешних систем — базы данных, сети, файловой системы и т. д.
Архитектурные предпосылки для автоматизированного тестирования:
- Модульность и слабая связанность: архитектура должна поощрять явные зависимости и избегать «магии» — скрытых связей, глобальных синглтонов и других антипаттернов, затрудняющих изоляцию.
- Использование интерфейсов и абстракций: вместо жёстких привязок к реализациям следует использовать контракты (например, интерфейсы, абстрактные классы), которые легко подменяются при тестировании.
- Инфраструктурная нейтральность бизнес-логики: логика не должна быть встроена в контроллеры, ORM или фреймворк-зависимые классы.
- Интеграция с CI/CD: unit-тесты должны запускаться автоматически на каждом pull request или коммите, до сборки артефактов, как часть быстрой проверки качества.
Если архитектура не обеспечивает этих условий, то даже простейшие тесты становятся громоздкими, медленными или попросту невозможными. Например, при использовании функциональных языков без поддержки DI, или при жёсткой связке бизнес-логики с базой данных, попытка написать unit-тест приводит к эмуляции целой системы — что противоречит самой идее модульности.
Важно помнить: unit-тесты — это не просто проверка функций. Это способ формализовать архитектурное обещание: если компонент спроектирован как самостоятельный, он должен быть тестируем в отрыве от остальной системы. А если не получается — это сигнал к пересмотру архитектуры.
Контрактные тесты: гарантия взаимопонимания между сервисами
Контрактные тесты (contract tests) проверяют, что интерфейс одного компонента (обычно микросервиса) соответствует ожиданиям других компонентов, которые от него зависят. В отличие от модульных тестов, которые изолируют и проверяют логику внутри компонента, контрактные тесты сосредоточены на поведении интерфейсов — то есть на том, как сервис «разговаривает» с внешним миром.
Это особенно важно в микросервисной архитектуре, где сервисы активно взаимодействуют друг с другом по сетевым протоколам (REST, gRPC, messaging и т. д.). Отсутствие или нарушение контракта между сервисами может привести к сбоям, которые проявляются только на стыке — и зачастую только в продакшене. Контрактные тесты помогают избежать этого, зафиксировав ожидания и проверяя их в автоматическом режиме.
Что считается контрактом?
- Спецификации API (OpenAPI, Protobuf, GraphQL).
- Описания схем сообщений (Kafka, RabbitMQ).
- Семантика и структура ответов (статусы, поля, типы).
- Поведение в граничных ситуациях (ошибки, таймауты, недоступность).
Контрактные тесты бывают односторонними (проверяется, что реализация соответствует контракту) и взаимными (consumer-driven), когда потребитель фиксирует ожидания, и провайдер обязан их удовлетворить.
Архитектурные предпосылки для ручного тестирования:
- Интерфейсы должны быть документированы и стабильны. QA-инженер должен иметь возможность сверяться с формализованной спецификацией (например, OpenAPI).
- Версионирование API должно быть предусмотрено: без этого невозможна проверка обратной совместимости.
- При необходимости — наличие sandbox-режима или тестового стенда, на котором можно воспроизводить сценарии потребления интерфейса.
Архитектурные предпосылки для автоматизированного тестирования:
- Спецификации API должны быть источником правды, а не «документами после реализации». Это может быть достигнуто через API-first подход, когда сначала создаются спецификации, а затем — реализация.
- Желательно, чтобы спецификации служили основой для генерации кода и валидации (codegen), чтобы исключить рассинхронизацию между описанием и поведением.
- Необходимо поддерживать фреймворки контрактного тестирования — такие как Pact, Spring Cloud Contract, TestContainers + OpenAPI. Эти инструменты позволяют проверять соответствие поведения реализаций спецификации.
- В случае событийной архитектуры (event-driven) — схемы сообщений должны быть описаны, версионируемы и проверяемы.
Контрактное тестирование особенно эффективно, когда используется в взаимной форме (consumer-driven contract testing): потребитель описывает свои ожидания (например, через Pact), провайдер валидирует, что их удовлетворяет. Это создаёт децентрализованную гарантию совместимости, позволяя командам развивать микросервисы независимо, без риска нарушить работу потребителей.
Однако следует понимать, что контрактные тесты работают на границе компонентов. Они не проверяют внутреннюю реализацию, но позволяют быть уверенными, что внешние ожидания соблюдаются. Поэтому их роль особенно велика в масштабных системах, где взаимодействует множество независимых команд и релизов.
Архитектура, поддерживающая контрактное тестирование, — это архитектура, в которой интерфейсы:
- стабильны и прогнозируемы,
- зафиксированы в спецификациях,
- валидируемы средствами автоматизации.
В результате контрактные тесты становятся надёжным барьером: они сигнализируют, когда изменение в реализации способно нарушить поведение потребителей, тем самым предотвращая регрессии ещё на этапе сборки.
Интеграционные тесты: проверка взаимодействия компонентов
Интеграционные тесты проверяют, как различные части системы взаимодействуют друг с другом. В отличие от unit- и контрактных тестов, которые сфокусированы на изолированных элементах, интеграционные тесты проверяют «сцепку» — то, насколько корректно один компонент вызывает другой, как передаются данные, как обрабатываются ошибки и как система ведёт себя в более реалистичном окружении.
В микросервисной архитектуре это особенно важно, поскольку взаимодействие между сервисами происходит через сеть, с участием API, брокеров сообщений, баз данных и других инфраструктурных компонентов. Здесь может пойти что угодно не так: от несовпадений в форматах данных до неустойчивых сетевых вызовов, таймаутов, недоступности зависимостей и ошибок сериализации.
Интеграционные тесты позволяют выявить проблемы, которые не видны на уровне интерфейса (контракта), но проявляются при реальном вызове сервисов друг другом, особенно если есть сторонние зависимости.
Архитектурные предпосылки для ручного тестирования:
- Документированные интерфейсы между сервисами: включая не только API, но и описание ошибок, таймаутов, форматов данных и контекстов вызова.
- Возможность развернуть изолированное тестовое окружение, включающее только необходимые зависимости.
- Поддержка моков или эмуляторов для недоступных или нестабильных компонентов (например, внешних API, шлюзов оплаты).
Архитектурные предпосылки для автоматизированного тестирования:
- Возможность запуска сервисов в составе окружения: чаще всего это достигается с использованием docker-compose, Kubernetes namespaces или тест-контейнеров.
- Архитектура должна предусматривать механизмы отслеживания вызовов и ошибок — например, распределённую трассировку (OpenTelemetry, Jaeger), логирование, метрики.
- Зависимости должны быть заменяемы на тестовые экземпляры: поднятие отдельных инстансов БД, брокеров (Kafka, RabbitMQ), мок-сервисов.
- Необходимо наличие retry-механизмов, таймаутов, стратегий деградации — и возможность проверить их в тестах.
Интеграционные тесты важны не только как инструмент проверки, но и как индикатор зрелости архитектуры. Архитектура, допускающая лёгкий запуск интеграционного окружения, отражает хорошую изоляцию сервисов, слабую связанность и предсказуемое поведение. Напротив, если для проверки взаимодействия нужно разворачивать весь продакшен-ландшафт, это говорит о скрытых связях и архитектурном долге.
Важно: интеграционные тесты не должны подменять собой контрактные. Контрактные тесты фиксируют ожидания, а интеграционные — проверяют поведение в реальной связке. Оба типа тестов необходимы, но решают разные задачи.
Кроме того, интеграционные тесты — основа для проверки инфраструктурных аспектов: корректности конфигурации, сетевой доступности, поведения при сбоях. Это позволяет не только убедиться в корректности кода, но и протестировать «инфраструктуру как код» в безопасных условиях.
Функциональные и регрессионные тесты: уверенность в поведении системы
Функциональные тесты направлены на проверку того, что система выполняет бизнес-функции в соответствии с ожиданиями. Они отвечают на вопрос: «Может ли пользователь (или внешний потребитель) выполнить нужный сценарий от начала до конца?» Эти тесты ориентированы на результат: не как работает внутри, а работает ли то, что нужно пользователю.
К функциональным тестам обычно относят:
- Проверку бизнес-сценариев (создание заказа, начисление скидки, авторизация пользователя и т. д.).
- Проверку логики обработки ошибок (например, недоступность внешнего провайдера, недостаток баланса).
- Тесты с валидными и невалидными данными.
Отдельно стоит упомянуть регрессионные тесты — это проверка того, что существующий функционал не пострадал после внесения изменений. Они особенно важны при работе с микросервисами, где изменения одного компонента могут неожиданно затронуть другие. Регрессионные тесты помогают выявить такие побочные эффекты до выхода в продакшен.
Архитектурные предпосылки для ручного тестирования:
- Документированная бизнес-функциональность, связанная с конкретными сервисами. Тестировщик должен понимать, где реализована логика того или иного сценария.
- Предсказуемые интерфейсы — например, REST API, спроектированные в соответствии с архитектурными стандартами (например, пирамида Ричардсона, HATEOAS), позволяют уверенно строить запросы и понимать, как сервис реагирует.
- Наличие тестовых данных и сценариев: fixtures, demo-режимы, примеры входных/выходных данных, граничные случаи.
Архитектурные предпосылки для автоматизированного тестирования:
- Система должна поддерживать инициализацию и сброс состояния — то есть управление тестовой БД, возможность «очистить» и «перезапустить» состояние между тестами.
- Должны быть предусмотрены механизмы генерации тестовых данных, подмены контекста, переключения флагов (например, для разных ролей пользователей).
- Idempotency и изолированность тестов — каждый тест должен быть независим от других, иметь повторяемый результат.
- Возможность запуска в CI: предварительное наполнение БД, контроль схем, управление фича-флагами и состоянием окружения.
Функциональные и регрессионные тесты могут выполняться на разных уровнях — как модульно (на уровне бизнес-логики), так и интеграционно (с участием нескольких сервисов). Важно лишь, чтобы они соответствовали прикладной логике, а не внутренним реализациям.
С архитектурной точки зрения, такие тесты особенно выигрывают от чёткой сегментации бизнес-функций по сервисам. Если логика «размазана» по микросервисам, или сценарий требует участия десятка компонентов — тестирование становится хрупким и неустойчивым. Напротив, если каждый сервис несёт понятную бизнес-ответственность — тестирование становится не только проще, но и ближе к реальному использованию.
Кроме того, автоматизация функционального тестирования — основа для быстрой поставки: именно они чаще всего входят в release-гейты и выполняются перед мержем, чтобы не допустить появления критических дефектов.
UI-тесты: проверка пользовательского взаимодействия
UI-тесты проверяют, как система ведёт себя через пользовательский интерфейс. Это может быть как ручное исследование поведения визуальных компонентов, так и автоматизированные сценарии кликов, переходов, валидации форм и навигации. UI-тесты — наглядны и приближены к пользовательскому опыту, но при этом являются одними из самых трудоёмких и нестабильных видов тестов.
Причина проста: они зависят от среды исполнения (браузеры, платформы, экраны), сложны в поддержке (изменение разметки может «сломать» тест), и часто медленно выполняются. Тем не менее, полностью исключить их нельзя — именно через UI конечные пользователи взаимодействуют с системой, и ошибки здесь сразу отражаются на восприятии продукта.
UI-тесты бывают:
- визуальными (проверка внешнего вида и расположения элементов);
- поведенческими (проверка сценариев, например: пользователь нажимает кнопку — происходит переход);
- тестами доступности и кросс-браузерности.
Архитектурные предпосылки для ручного тестирования:
- Предсказуемость интерфейса: UI должен быть детерминирован — условия появления элементов, последовательность действий, реакция на события должны быть понятны и документированы.
- Наличие документации по состояниям компонентов: описание, когда и какие элементы появляются, как навигация устроена, какие данные ожидаются на экране.
- Поддержка тестовых данных и режимов: возможность переключиться в демо-режим, использовать специфические учётные записи, запустить страницу с заранее известным состоянием.
Архитектурные предпосылки для автоматизированного тестирования:
- Стабильные селекторы элементов: использование data-testid, aria-label, role, чтобы тесты не зависели от классов или структуры DOM.
- Компонентная архитектура UI: модульность интерфейса (например, с использованием React/Vue + компонентных библиотек) позволяет изолировать и тестировать части интерфейса независимо.
- Управление состоянием через store (Redux, Vuex и др.): чёткое хранилище состояния облегчает предсказуемость поведения интерфейса.
- Механизмы очистки и сброса состояния UI между тестами.
- Поддержка headless-режимов (например, Puppeteer, Playwright, Cypress) — для быстрой и параллельной проверки в CI/CD.
UI-тесты — это верхушка тестовой пирамиды, и потому их нужно использовать сдержанно и осознанно. Нельзя заменить ими все остальные уровни тестирования — они слишком дорогие, медленные и нестабильные. Но для проверки критичных пользовательских сценариев и визуальных регрессий они необходимы.
Также важно избегать избыточного дублирования: если бизнес-логика уже покрыта на уровне unit и функциональных тестов, не стоит повторять её в UI-обёртке — это создаёт хрупкое дублирование без прироста пользы.
Грамотно выстроенная архитектура фронтенда — с модульностью, декларативным состоянием, предсказуемыми API и надёжными селекторами — позволяет сделать UI-тестирование менее болезненным и более системным.
End-to-End тесты: проверка сквозных пользовательских сценариев
End-to-End (E2E) тесты — это высший уровень тестирования, направленный на проверку сквозных бизнес-сценариев системы в максимально приближённом к реальному окружении. Они имитируют поведение пользователя, проходящего через интерфейс или API всей системы от начала до конца. Цель — убедиться, что все слои системы, от UI до базы данных, работают согласованно и обеспечивают нужный результат.
Примеры E2E-сценариев:
- пользователь регистрируется, добавляет товар в корзину и оформляет заказ;
- администратор редактирует контент, а пользователь видит обновлённую информацию;
- пользователь инициирует возврат товара, и процесс проходит через сервисы логистики, биллинга и уведомлений.
Эти тесты особенно важны в микросервисной архитектуре, где задействовано множество независимых сервисов. Даже если каждый из них работает корректно по отдельности, сквозной сценарий может сломаться на стыках: из-за несовпадения форматов, различий в логике обработки ошибок, проблем с синхронизацией и другими тонкостями взаимодействия.
Архитектурные предпосылки для ручного E2E-тестирования:
- Наличие описанных бизнес-сценариев (user journey), покрывающих ключевые пути пользователя, с указанием желаемого результата и вариантов ошибок.
- Возможность вручную приводить систему в нужное состояние: например, переключить статус заказа, симулировать оплату, активировать пользователя.
- Архитектура должна обеспечивать трассируемость запроса от UI до backend, чтобы тестировщик мог диагностировать, где именно возникает проблема при прохождении сценария.
Архитектурные предпосылки для автоматизации E2E-тестов:
- Поддержка стабильных, управляемых окружений: например, namespace в Kubernetes, предсобранные сценарные данные, реплики сервисов.
- Возможность инициализации и сброса состояния системы (reset API, фикстуры, «тестовый часовой пояс», управляемые фича-флаги).
- Изолированность и предсказуемость данных — чтобы один тест не мешал другому и чтобы результат не зависел от внешнего флуктуационного состояния.
- Обязательная интеграция с системой мониторинга и алертинга: при падении критичных E2E-сценариев система должна сигнализировать команде немедленно.
Хотя E2E-тесты дают наивысшую степень уверенности, они не заменяют нижние уровни тестирования. Их назначение — не проверить всю систему, а подтвердить, что жизненно важные пользовательские сценарии работают как ожидается.
Ключевая рекомендация — фокусироваться на небольшом, стабильном наборе самых ценных сценариев, которые должны проходить всегда. Эти тесты могут запускаться как «smoke-regression» после каждого релиза, и в случае сбоя сразу сигнализировать о нарушении пользовательского опыта.
Архитектурно, поддержка E2E-тестирования означает:
- минимизацию скрытых зависимостей и «магических» состояний;
- способность системы быть восстановленной или перезапущенной в любом состоянии;
- прозрачность взаимодействий между сервисами.
При правильном подходе E2E-тесты становятся не просто инструментом тестирования, а своего рода договором между архитектурой и бизнесом: «вот те сценарии, которые точно должны работать — всегда».
Стратегия тестирования.
Отдельного внимания заслуживает документ под названием «Стратегия тестирования» — ключевой артефакт, обеспечивающий системный, управляемый и воспроизводимый процесс проверки качества. Он не просто описывает, как тестировать, но задаёт рамки и принципы, по которым команда принимает решения в условиях ограниченности времени, ресурсов и изменчивости требований. Типовое содержание такой стратегии включает:
- Цели и охват тестирования — какие аспекты системы проверяются: функциональность, производительность, безопасность, устойчивость к сбоям и т. д.;
- Подходы и уровни тестирования — выбор методов (юнит, интеграционные, контрактные, end-to-end и пр.), баланс между ручными и автоматизированными проверками;
- Инструменты и ресурсы — используемые фреймворки, среды, пайплайны, а также распределение усилий внутри команды;
- Планирование и контроль — критерии начала и окончания тестирования, порядок обработки дефектов, расписание запусков;
- Управление рисками — приоритеты, зоны повышенной уязвимости, планы на случай сбоев или неполных данных.
При наличии качественно сформированной стратегии команда понимает что, где, когда и зачем проверяется, и может заранее спланировать процесс, сделать его повторяемым и масштабируемым. Это особенно важно в распределённых командах и микросервисной архитектуре, где тестирование невозможно централизовать, а релизы происходят асинхронно.
Однако на практике подходы к тестированию нередко варьируются от команды к команде. Это объясняется как разной зрелостью процессов, так и неоднородностью компетенций внутри QA-функции и смежных ролей (разработчиков, аналитиков, архитекторов). Поэтому стратегия тестирования не может быть универсальной — она всегда отражает специфику конкретной команды, системы и организационной среды.
Отсюда ключевой вывод: качество и полнота архитектурных артефактов, как и выбор инструментов тестирования, напрямую зависят от процессов и зрелости команды. Архитектура может быть «тестируемой по умолчанию» только в том случае, если в команде есть общая договорённость о подходах и уровне автоматизации.
Наконец, важно понимать, что Quality Assurance — это не просто набор тестов, а широкая инженерная дисциплина, включающая в себя архитектуру тестирования, мониторинг, управление окружениями, автоматизацию CI/CD, анализ дефектов, стратегию работы с данными и многое другое. Разработка стратегии тестирования — это не шаблонная задача, а инженерное проектирование под конкретные ограничения и цели.
В рамках данной статьи мы не будем углубляться в процессный и инструментальный уровень QA, так как он выходит за рамки архитектурной ответственности. Однако архитекторы должны чётко понимать, в чём суть стратегии тестирования, какие зависимости она порождает и как она влияет на архитектурные решения. Это знание критично для того, чтобы архитектура и тестовая стратегия дополняли друг друга, а не конфликтовали.
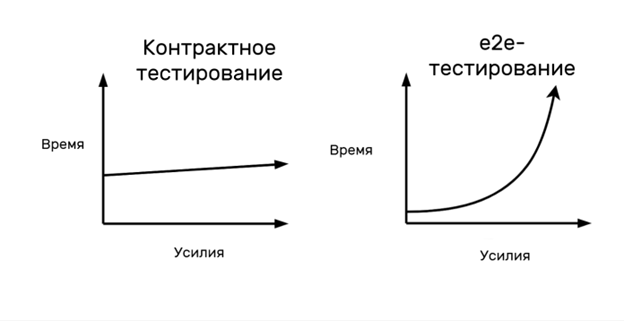
Однако для наглядности приведу интерпретацию пирамиды тестирования из статьи Onur Baskirt (https://habr.com/ru/companies/serverspace/articles/690578/):
Нагрузочное тестирование: проверка устойчивости под давлением
Нагрузочное тестирование позволяет оценить, как система ведёт себя при возрастающем объёме нагрузки — будь то рост числа пользователей, запросов, объёма обрабатываемых данных или операций в единицу времени. Это критически важный этап, позволяющий выявить узкие места производительности ещё до выхода в продакшен: замедление отклика, нарастание ошибок, деградация отдельных компонентов или полные отказы.
Цель нагрузочного тестирования — не просто зафиксировать предел возможностей, а проверить, соответствует ли система ключевым нефункциональным требованиям: по скорости отклика, стабильности, способности масштабироваться. Полученные в ходе таких тестов метрики становятся базой для решений об оптимизации архитектуры, инфраструктуры и кода. Это помогает команде предотвратить проблемы, а не устранять их в условиях боевой эксплуатации.
Нагрузочное тестирование также даёт возможность проектировать сценарии контролируемой деградации — когда система при достижении предельной нагрузки сохраняет стабильность, временно отключая или упрощая работу неключевых функций (например, отключение вторичной аналитики, кеширование блоков, переключение в режим ограниченной функциональности). Это требует сознательного проектирования на уровне архитектуры: выделения критичного функционала, внедрения механизмов graceful degradation и управления приоритетами обработки.
Ключевые предпосылки нагрузочного тестирования:
Нагрузочные проверки — затратный и технически сложный процесс, требующий:
- Изолированного окружения, полностью контролируемого и независимого от продуктивной среды;
- Эмуляции внешних систем (провайдеров данных, API, брокеров), чтобы не перегружать настоящие интеграции;
- Компетентной команды — специалистов по performance testing, DevOps и системному проектированию;
- Средств анализа результатов — мониторинга, трассировки, профилирования узлов и сервисов.
На практике нагрузочному тестированию подвергается не вся система, а только ключевые цепочки — core-функциональность. Это логично: они критичны для бизнеса и первыми страдают при росте трафика. Но чтобы такое фокусное тестирование было возможно, архитектура должна явно выделять core-сценарии: как на уровне функционального проектирования (какие операции жизненно важны), так и на уровне системной архитектуры (какие сервисы обеспечивают их выполнение).
Архитектурные выводы:
Для того чтобы нагрузочное тестирование было не точечной акцией, а встроенной частью зрелого инженерного процесса, архитектура системы и архитектура решений должны быть связаны между собой. Это означает:
- наличие слоя бизнес-приоритизации в архитектурных артефактах;
- выделение критичного функционала и определение SLA/SLI;
- проектирование архитектуры с возможностью масштабирования и мониторинга;
- документирование и контроль производственных ограничений.
Таким образом, нагрузочное тестирование становится не просто технической активностью, а инструментом проверки архитектурной состоятельности, позволяющим подтвердить, что система спроектирована не только правильно, но и под реальные нагрузки.
Тестирование в условиях микросервисной архитектуры
Микросервисная архитектура накладывает на процесс тестирования ряд жёстких ограничений, связанных с распределённой природой системы и автономностью компонентов:
- Распределённая природа системы. Каждый сервис развёртывается и обновляется независимо, что усложняет сквозное тестирование. В итоге основное внимание смещается к интеграционным проверкам, обеспечивающим корректность взаимодействия между микросервисами.
- Сложность согласованности данных. В архитектуре, где разные сервисы могут использовать собственные базы данных и обмениваться сообщениями асинхронно, проверка целостности данных становится нетривиальной. Тестовые сценарии должны предусматривать частичные сбои, нарушения порядка сообщений и восстановление консистентности после отказов.
- Высокая степень связанности через API. Поскольку все взаимодействия происходят поверх чётко определённых контрактов, особенно критично организовать contract testing (например, Consumer-Driven Contract Testing). Это позволяет удостовериться, что изменения в одном сервисе не сломают потребителей его API.
- Частые релизы. Когда каждый микросервис может выходить в продакшен по собственному графику, без надёжной автоматизации тестирования и CI/CD-процессов сложно поддерживать стабильность всей системы. Автоматизированные сборки, тест-гейты и «зелёные» пайплайны становятся обязательными.
- Сложность отслеживания ошибок. Распределённые логи и трассировка запросов (distributed tracing) усложняют диагностику неполадок. На архитектурном уровне важно предусмотреть централизованные механизмы сбора метрик, единую систему логирования и инструмент трассировки (OpenTelemetry, Jaeger и др.), чтобы тесты могли фиксировать и передавать информацию об ошибках между сервисами.
- Разнородность технологий. Разные микросервисы могут быть написаны на разных языках, фреймворках и использовать разные подходы к хранению данных. Это усложняет стандартизацию процессa тестирования: требуется унификация форматов обмена, единые спецификации контрактов и единственный способ настроить окружение для запуска тестов.
- Требования к отказоустойчивости. В распределенной среде сбои отдельных сервисов — не исключение, а норма. Поэтому помимо интеграционных проверок необходимо включать в практику Chaos Engineering — контролируемое внесение отказов (например, выключение случайных экземпляров, нагружение сети, имитация недоступности БД и т. п.), чтобы убедиться, что система при этом сохраняет работоспособность. Ключевой принцип — проверка гипотезы: «Если сервис A не отвечает, сервис B должен переключиться на резервную логику и завершить сценарий без фатального сбоя».
- Управление версионностью. При параллельной работе старых и новых версий микросервисов необходимо проверять совместимость. Это касается миграций схем баз данных, контрактов API и последовательности событий в event-driven архитектуре. Архитектура должна предусматривать стратегию backward- и forward-совместимости, чтобы тестировать различные комбинации версий в изолированном окружении.
- Безопасность на уровне сервисов. Каждая точка входа (REST, gRPC, message broker) должна быть защищена. Тестирование авторизации, аутентификации и разграничения доступа становится критически важным, поскольку ошибка в одном сервисе может дать внешнему злоумышленнику широкий доступ к системе.
- Сложность воспроизведения окружений. Локально эмулировать весь ландшафт микросервисов с их зависимостями трудно. Архитектура должна поддерживать контейнеризацию (Docker, Kubernetes, Testcontainers), возможность использовать моки и эмуляторы, чтобы команда QA могла запускать интеграционные и нагрузочные тесты в изолированных, но близких к продакшену условиях.
Архитектурные выводы
- Единый источник правды. Все требования и договорённости между сервисами (контракты API, схемы событий, форматы данных) должны быть формализованы и доступны автоматизации. Это упрощает проверку требованиям («тестирование требований») и позволяет QA-инженеру работать без постоянных уточнений у разработчиков.
- Автоматизация ближе к основанию пирамиды. Чем проще читаются и интерпретируются требования (контракты, спецификации), тем дешевле автоматизировать тесты на более низких уровнях (модульные, контрактные). Контрактные тесты, как правило, легче автоматизировать, чем E2E.
- Быстрый feedback loop. Архитектура должна поддерживать непрерывную интеграцию: запуск unit-, контрактных и базовых интеграционных тестов при каждом PR. Лишь при «зелёном» результате CI/CD-пайплайна следует переходить к более тяжёлым проверкам (E2E, нагрузочные, хаос-эксперименты).
- Наблюдаемость и трассировка. Без централизованного логирования, метрик и распределённой трассировки невозможно быстро локализовать сбой. Архитектурный дизайн должен предусматривать единую систему наблюдаемости, на основе которой тесты могут фиксировать девиации и передавать информацию команде.
- Изолированные тестовые окружения. Использование контейнеров и моки-инфраструктуры позволяет запускать интеграционные и нагрузочные проверки без влияния на продуктив. Это сокращает риски и ускоряет обнаружение проблем.
Резюмируя: архитектурная зрелость микросервисов напрямую влияет на эффективность тестирования: чем прозрачнее контракты, модульнее компоненты и богаче механизмы наблюдаемости, тем быстрее и надёжнее команда сможет выявлять и исправлять дефекты.
Прекондишн: проверка спецификаций до написания кода
В архитектурно зрелых командах, придерживающихся подходов API-first или Design-first, проектирование API-интерфейсов выполняется до начала реализации инкремента. Такой подход позволяет верифицировать архитектурные решения, избежать избыточных зависимостей и заложить основу для автоматизированного тестирования ещё до написания кода.
Одним из ключевых инструментов контроля качества на этом этапе становится линтер спецификаций API (например, для OpenAPI или AsyncAPI). Линтер позволяет автоматически проверять спецификацию не только на соответствие общепринятым стандартам (валидность схем, корректность структур, допустимые типы), но и на соблюдение внутренних командных соглашений и ограничений, сформулированных как часть архитектурной дисциплины. Как пример более жестких ограничений: https://dzen.ru/a/ZzNJcH1L9nyGemAj
Внутренние стандарты, как правило, жёстче общих. Они могут включать:
- запрет на вложенные схемы без референсов;
- требования к использованию определённых форматов идентификаторов;
- обязательность указания типов ошибок и семантики HTTP-кодов;
- требования к именованию параметров, структурированию путей, разделению read/write API;
- правила версионирования и совместимости между релизами.
Такие ограничения особенно актуальны, если команда использует code generation — автоматическую генерацию серверного и клиентского кода на основе спецификаций. В этом случае любая небрежность в описании API ведёт к сбоям на этапе сборки или к недетерминированному поведению в рантайме.
Линтинг спецификаций до начала разработки позволяет устранять ошибки проектирования интерфейсов на самом раннем этапе — до того, как они будут закодированы, протестированы и (что особенно опасно) задеплоены в продакшен. Это снижает стоимость исправления дефектов, повышает предсказуемость поведения сервисов и упрощает контрактное тестирование.
Кроме того, такая практика помогает выравнивать архитектурную культуру в масштабных командах, особенно при параллельной разработке микросервисов разными группами. Единый стиль описания интерфейсов, применяемый линтером, действует как архитектурный гейт: он формализует требования, снижает количество неоднозначностей и делает интерфейсы понятными как людям, так и машинам.
Валидация и линтинг API-спецификаций — это прекондишн архитектурной зрелости: минимальные требования к входу в реализацию. Они позволяют строить процесс проектирования интерфейсов как контролируемую инженерную практику — с прозрачными критериями качества, обратной связью и возможностью автоматизации.
Контрактные тесты: архитектурная альтернатива unit-тестированию
В системах, построенных по принципам чистой (луковой) архитектуры и при соблюдении дисциплины проектирования микросервисов, появляется интересная возможность: использовать контрактные тесты не только как дополнение, но и частичную альтернативу unit-тестам.
Если микросервис спроектирован корректно, его архитектура будет включать:
- чёткое разделение слоёв — внешний API, слой оркестрации (application), слой бизнес-логики (domain), слой доступа к инфраструктуре (persistence, messaging);
- тонкий слой адаптации на уровне API, не содержащий логики, а лишь делегирующий вызовы в application- или domain-слои;
- однородный и стандартизованный API-слой — с предсказуемыми REST или Async интерфейсами, описанными в OpenAPI/AsyncAPI спецификациях.
В такой архитектуре методы внешнего интерфейса с высокой степенью соответствия отражают публичные методы классов, реализующих бизнес-логику. Это означает, что, протестировав API контрактными тестами, можно с достаточной степенью уверенности проверить не только корректность взаимодействия с внешним миром, но и само поведение сервиса — вплоть до бизнес-правил.
Возможность заменить unit-тесты контрактными
Это подводит к архитектурному компромиссу: в ряде случаев контрактные тесты могут заменить часть unit-тестов, особенно если:
- логика микросервиса проста, а API полностью покрывает точки входа;
- бизнес-логика не содержит сложных внутренних ветвлений, которые невозможно протестировать извне;
- команда стремится ускорить разработку и сосредоточиться на интеграции и поведении на уровне интерфейсов.
Такой подход не даёт 100% покрытия кода, но обеспечивает практически полное покрытие сценариев использования — а именно это важно в сервисах, ориентированных на предсказуемую, декларативную логику. Кроме того, контрактные тесты проверяют не только вызовы, но и структуру, формат, типизацию, семантику ошибок и соответствие спецификации — то, чего unit-тесты не касаются.
Преимущества для разработки
- Контрактные тесты легко интегрируются в CI/CD, позволяя проверять стабильность интерфейсов при каждом изменении.
- Их можно писать и поддерживать прямо разработчиком, без отдельной фазы ручного тестирования.
- Они повышают надёжность взаимодействий между сервисами и снижают вероятность регрессий при обновлении API.
- С их помощью можно выявлять конфликты между потребителем и провайдером до интеграционного уровня, на этапе сборки.
Пример инструмента: Pact
Одним из наиболее известных инструментов для consumer-driven contract testing является Pact. Он позволяет описывать ожидания потребителя API, проверять их на стороне провайдера и встроить всю проверку в пайплайн CI. Pact подходит как для REST, так и для событийных систем (например, Kafka) и поддерживает различные языки.
Pact и его аналоги не только валидируют соответствие спецификации, но и могут сгенерировать мок-сервер, использовать контракты для симуляции зависимостей, а главное — гарантировать, что поведение сервиса остаётся стабильным при эволюции API.
Архитектурный выбор
Решение о замене части unit-тестов контрактными — архитектурное и командное. Оно должно приниматься осознанно, с пониманием покрытия, рисков и целей. Если микросервисы структурированы, API стандартизирован, а команда зрелая и дисциплинированная — такой подход может сильно ускорить разработку, сократить объём шаблонных unit-тестов и повысить общее качество взаимодействий.
Тем не менее он не отменяет необходимости unit-тестирования в случаях, где:
- логика сложна или имеет множество условий;
- требуется высокая точность локализации ошибок;
- нужно тестировать поведение вне интерфейса (например, внутренние расчёты или побочные эффекты).
Контрактные тесты — мощный инструмент, но, как и любой инструмент, работают эффективно только в контексте зрелой архитектуры.
Взаимное контрактное тестирование: синхронизация без интеграционных релизов
Взаимное контрактное тестирование (или consumer-driven contract testing) — это архитектурная практика, позволяющая выстроить взаимодействие между командами провайдеров и потребителей API без необходимости тесной синхронизации или интеграционных релизов. В условиях микросервисной архитектуры, где команды работают автономно и развивают сервисы независимо, это становится особенно актуальным.
Суть подхода — в формализации контракта между двумя сторонами: сервисом-провайдером (предоставляющим API) и сервисом-потребителем (использующим этот API). Контракт фиксирует ожидания потребителя от интерфейса и используется как проверяемый артефакт в обоих пайплайнах.
Архитектурный сценарий взаимодействия выглядит следующим образом:
- Команда провайдера фиксирует спецификацию API, которая становится основой для проектирования и разработки (например, OpenAPI-описание или контракт в формате Pact).
- Команда потребителя подписывается на эту спецификацию, начиная реализацию своей части функциональности с опорой на ожидаемое поведение сервиса-провайдера.
- При сборке сервиса-провайдера в CI происходит автоматическая проверка соответствия фактической реализации заявленной спецификации. Если реализация не соответствует — сборка не проходит, и выпуск останавливается до устранения расхождений.
Этот подход позволяет создать архитектурную гарантию того, что потребитель не «сломается» при следующем изменении в API. Он позволяет развивать сервисы параллельно, без ожидания, пока все стороны «договорятся» вживую — вся договорённость зафиксирована в контракте и проверяется средствами автоматизации.
Архитектурные и организационные предпосылки:
Несмотря на привлекательность идеи, взаимное контрактное тестирование требует высокой зрелости технической и организационной среды:
- Наличие культуры API-first и versioned contracts — контракты должны быть первоклассными артефактами, хранимыми в системе контроля версий и участвующими в CI/CD.
- Автоматизация CI/CD и разделение окружений — каждое изменение API должно проверяться на совместимость в автоматическом режиме.
- Инфраструктура хранения и публикации контрактов — такие как Pact Broker, позволяющая потребителям регистрировать свои ожидания, а провайдерам валидировать их.
- Дисциплина и зрелость команд — команды должны чётко понимать свои зоны ответственности и не модифицировать API без учёта интересов потребителей.
Практические ограничения
На практике внедрение этого подхода нередко сопровождается коллизиями и сложностями, особенно в начальной фазе:
- Изменение интерфейса в одной команде может блокировать релиз другой;
- Требуется постоянная синхронизация версий контрактов;
- Необходимо разруливать ситуации несовместимости, даже если на практике функциональность потребителя пока не используется;
- Возрастает объём артефактов и связанной с ними инфраструктуры.
Кроме того, без развитых DevOps-практик и надёжной автоматизации внедрение взаимного контрактного тестирования может привести к увеличению времени на согласование изменений и росту технического долга.
Тем не менее, при зрелом подходе и качественной архитектуре, взаимное контрактное тестирование позволяет отказаться от интеграционных релизов, добиться реальной независимости команд и снизить вероятность скрытых ошибок на стыках микросервисов — именно там, где традиционные интеграционные тесты наиболее уязвимы.
Проблема данных в тестировании микросервисов: антипаттерн интеграционных релизов
В условиях микросервисной архитектуры, где разработка ведётся параллельно несколькими командами, неизбежно возникает проблема неодновременной готовности компонентов. Некоторые микросервисы развиваются быстрее, другие — медленнее. Дополнительно усложняет ситуацию то, что внешние провайдеры данных — будь то партнёрские API, государственные сервисы или внутренние платформенные модули — могут быть временно недоступны или технически не готовы.
Когда команды начинают выстраивать процесс тестирования и подготовки релиза только после полной готовности всего ландшафта, возникает ситуация, известная как интеграционный релиз. Это означает, что:
- отдельные инкременты «висят в ожидании» готовности других;
- невозможно изолированно протестировать функциональность одного сервиса;
- вся система начинает развиваться по самому медленному компоненту.
Такой подход — серьёзный антипаттерн масштабной разработки, приводящий к резкому падению скорости вывода релизов, накоплению технического долга и отказу от принципов микросервисной независимости. В больших корпоративных системах это может означать задержки в неделями или даже месяцами, и сводит на нет преимущества декомпозиции архитектуры.
Как архитектура может устранить этот антипаттерн?
Существуют два ключевых подхода, архитектурно устраняющих зависимость от полной готовности среды:
1. Эмуляция провайдеров (mock-сервисы)
В этом сценарии внешние или ещё неготовые сервисы заменяются заглушками (mock), которые имитируют ожидаемое поведение API или событий. Архитектура должна позволять подключать такие заглушки без модификации логики сервиса и без изменения среды.
Ключевые требования:
- Стандартизированные интерфейсы: поведение моков определяется по спецификациям (например, OpenAPI/AsyncAPI), что требует API-first подхода.
- Механизм переключения зависимости — сервис должен «не замечать», используется ли настоящий провайдер или mock.
- Хранилище контрактов и поведения: примеры — Pact Broker (использует pact-файлы, сгенерированные на основе тестов потребителей), WireMock, MockServer, Postman Mock Server.
- Инфраструктурная изоляция: возможность запускать окружение с моками, не затрагивая продуктивные или нестабильные внешние сервисы.
Моки особенно эффективны, если команды используют contract-first подход, а архитектура позволяет валидировать поведение заглушек на соответствие спецификациям. Это снижает риски отклонений между тестовой средой и реальностью, и позволяет начинать разработку и тестирование без задержек, даже если сервис-провайдер ещё не готов.
2. Фича-флаги (feature toggles)
Ещё один способ сократить зависимость от внешней среды — фича-флаги. Это архитектурный приём, при котором новый функционал внедряется в код, но включается или выключается в рантайме в зависимости от конфигурации. Таким образом, разработка и поставка фич может быть завершена, даже если условия использования пока не готовы.
Архитектурные свойства фича-флагов:
- Изоляция функционала — архитектура должна обеспечивать возможность "отключить" код без риска для остальной системы;
- Гибкая конфигурация — управление через централизованные фича-серверы (например, LaunchDarkly, Unleash) или локальные переменные;
- Встроенные механизмы контроля состояния — логирование, метрики, аудит активации/деактивации фич.
Фича-флаги позволяют развивать и тестировать функциональность без зависимости от готовности внешних условий, что критично при частых релизах. Однако при этом важно не допустить архитектурной эрозии.
Архитектурные риски и злоупотребления
При неконтролируемом использовании оба механизма — и моки, и фича-флаги — могут быть использованы не по назначению. Особенно это касается фича-флагов, которые часто:
- превращаются в постоянные элементы логики;
- используются для реализации A/B-тестов, бизнес-ветвлений или конфигураций, не предназначенных для выката;
- приводят к запутанному, нечитаемому коду и усложняют отладку.
Чтобы избежать подобных проблем, необходимо:
- чётко разграничить архитектурные флаги (для управления выкладкой) и бизнес-логику;
- внедрить архитектурный надзор или автоматизированную валидацию на этапе CI, контролирующую количество активных флагов и длительность их жизни;
- использовать фича-менеджмент как инструмент управления поставкой, а не как универсальную технику «обхода» архитектурных ограничений.
Для того чтобы обеспечить независимость тестирования и поставки компонентов, архитектура должна позволять:
- изолировать разработку микросервисов друг от друга;
- эмулировать недостающие зависимости;
- управлять включением новых функций без их немедленного активационного воздействия на систему;
- проектировать компоненты так, чтобы они могли работать в «пустом» или частично интегрированном окружении.
Таким образом, устранение зависимости от интеграционных релизов — это не просто оптимизация процесса тестирования, а архитектурная зрелость, проявляющаяся в способности системы быть управляемо недосовершенной на любом этапе её развития.
Несколько слов о TDD: тест как форма проектирования
TDD (Test-Driven Development) — это инженерная методология, при которой разработка начинается не с кода, а с написания автоматических тестов, определяющих поведение системы. Сначала формулируется ожидаемый результат, затем пишется минимальный код, чтобы тест прошёл, и только потом следует рефакторинг. Такой цикл известен как "red–green–refactor" и служит не только инструментом контроля качества, но и механизмом проектирования поведения.
Методология была популяризирована Кентом Беком в книге "Test-Driven Development: By Example", где она представлена как дисциплинированный и повторяемый процесс разработки, направленный на формализацию требований через тесты и постепенное наращивание функциональности.
Однако важно понимать: TDD — не просто практика “сначала тесты, потом код”, а достаточно строгий подход к проектированию. Он требует зрелости мышления, высокой дисциплины и отказа от спонтанной разработки. Это делает внедрение TDD непростым, особенно в среде, где нет выстроенных инженерных практик и отсутствует автоматизация.
Почему мы говорим о TDD в контексте архитектуры тестирования?
Если взглянуть на TDD в архитектурном ключе, становится очевидно: это частный случай design-first подхода, только вместо спецификаций и контрактов используются тесты как форма описания поведения. Разработчик формулирует "контракт" на уровне теста — как должен вести себя компонент, сервис или система — и только после этого начинает реализацию. Таким образом, TDD — это не альтернатива контрактно-ориентированному проектированию, а его разновидность, в которой роль спецификации выполняют тестовые сценарии.
Эта связь подчёркивает общую идею всей современной архитектуры: сначала определить поведение, потом реализовать, независимо от того, делается это через OpenAPI, Pact, unit-тесты или сквозные сценарии. Именно в этом заключается архитектурная ценность TDD — оно формализует намерения до начала реализации, обеспечивая тем самым предсказуемость и управляемость кода.
Еще немного несвязанной волосянки:
Роль тестирования в автономии команд
Тестирование играет ключевую роль в обеспечении автономии команд при переходе к микросервисной архитектуре. Каждая команда, отвечающая за свой сервис, должна иметь возможность самостоятельно проверять качество своего кода без зависимости от других команд. Это достигается через внедрение локальных наборов тестов — юнит-тестов, интеграционных тестов и контрактных тестов, которые гарантируют, что изменения внутри сервиса не нарушают его внутреннюю логику и взаимодействия с соседними сервисами. Автономные команды получают возможность быстро выявлять и исправлять ошибки, сокращая циклы обратной связи и повышая скорость разработки.
Кроме того, автономность невозможна без четко выстроенного процесса автоматического тестирования и непрерывной интеграции, который интегрируется в пайплайн каждой команды. Наличие стабильного тестового покрытия позволяет каждой команде самостоятельно выпускать релизы без ожидания согласования или исправлений от других групп. Это снижает риски регрессий и конфликтов при интеграции, формируя доверие к качеству поставляемого продукта. В результате автономные команды становятся более эффективными, гибкими и ответственными за конечный результат — что является важнейшим преимуществом микросервисного подхода.
Типовые антипаттерны при тестировании микросервисов
Одним из распространённых антипаттернов при тестировании микросервисов является чрезмерная зависимость от интеграционных тестов с реальными внешними сервисами и базами данных. Такой подход приводит к тому, что тесты становятся медленными, нестабильными и трудно воспроизводимыми, что снижает скорость обратной связи и замедляет процесс разработки. Вместо этого рекомендуется активно использовать мокирование и стабы для изоляции тестируемого микросервиса, сохраняя при этом баланс между покрытием и эффективностью тестирования.
Другой антипаттерн — это недостаточное покрытие контрактных тестов между микросервисами, что ведёт к частым нарушениям взаимодействий на этапе интеграции и на продакшене. Без автоматической проверки контрактов командное взаимодействие становится уязвимым к ошибкам из-за несогласованности API, форматов сообщений или бизнес-логики. Также часто встречается ситуация, когда команды забывают или откладывают написание юнит-тестов, полагаясь исключительно на энд-ту-энд тесты, что делает локальную отладку сложной и приводит к накоплению технического долга. Эти антипаттерны серьёзно подрывают надёжность микросервисной системы и усложняют её поддержку.
Варианты организации тестов при работе с общей БД
При работе с микросервисами, использующими общую базу данных, тестирование сталкивается с рядом специфических вызовов, связанных с поддержанием целостности данных и изоляцией тестов. Один из вариантов организации тестов — использование схем или пространств имён (namespaces) для каждого сервиса в общей базе. Такой подход позволяет изолировать данные разных сервисов на уровне базы, уменьшить риск конфликтов и упростить очистку данных после тестов. При этом важно продумать стратегии миграций схем, чтобы изменения, вносимые одним сервисом, не ломали логику других.
Другой подход — использование контейнеров баз данных с копиями актуального состояния или специализированных тестовых баз, которые разворачиваются для каждого тестового прогона. Это позволяет проводить интеграционные тесты с реалистичными данными и сценариями, сохраняя при этом независимость тестов друг от друга. Однако этот метод требует ресурсов и времени на развёртывание, поэтому часто комбинируется с мокированием и контрактным тестированием, чтобы обеспечить баланс между скоростью тестов и достоверностью проверки взаимодействия сервисов через общую БД.
Заключение: архитектура как основа тестируемости
Тестирование в современных распределённых системах — это не просто технический этап, а отражение архитектурных решений. Качество и структура архитектуры напрямую определяют тестируемость компонентов, скорость обнаружения дефектов, возможность автоматизации и надежность релизного процесса.
В микросервисной архитектуре особенно критично:
- Однозначность контрактов и спецификаций — как основа для unit-, контрактных и интеграционных тестов;
- Изоляция и слабая связанность компонентов — как условие масштабируемости тестирования;
- Наблюдаемость, трассировка, метрики — как архитектурный инструмент диагностики;
- Контроль поведения в условиях отказа — через Chaos Engineering и устойчивые паттерны;
- Отказ от интеграционных релизов — с помощью моков, фича-флагов и независимых пайплайнов;
- Наличие зрелой стратегии тестирования — как организационно-технического инструмента согласования усилий команд.
Архитектор не обязан писать тесты, но он обязан создавать условия, в которых тестирование возможно, эффективно и воспроизводимо. Это означает, что архитектура должна быть не только корректной, но и проверяемой — не только «работать», но и допускать верификацию своего поведения в автоматическом и контролируемом виде.
Использование API-first и design-first подходов, грамотная декомпозиция, фиксация контрактов, проектирование отказоустойчивости и автоматизация тестовых сценариев — всё это части единого инженерного подхода, в котором архитектура и тестирование работают не параллельно, а совместно.
Именно поэтому зрелость архитектуры и зрелость тестирования — неразрывно связаны. И именно в этой точке — на стыке — формируется основа для надёжных, масштабируемых и живучих систем.