
Big Data – этобольшие массивы структурированной или неструктурированной информации. Их обработка позволяет быстро находить связи между данными и точно их интерпретировать, пока они еще актуальны. Большие данные используются в бизнесе, госуправлении, медицине и других сферах. Но вместе с возможностями приходят и риски: от неверных выводов до кибератак.
Определение и история возникновения
Происхождение термина и первые упоминания
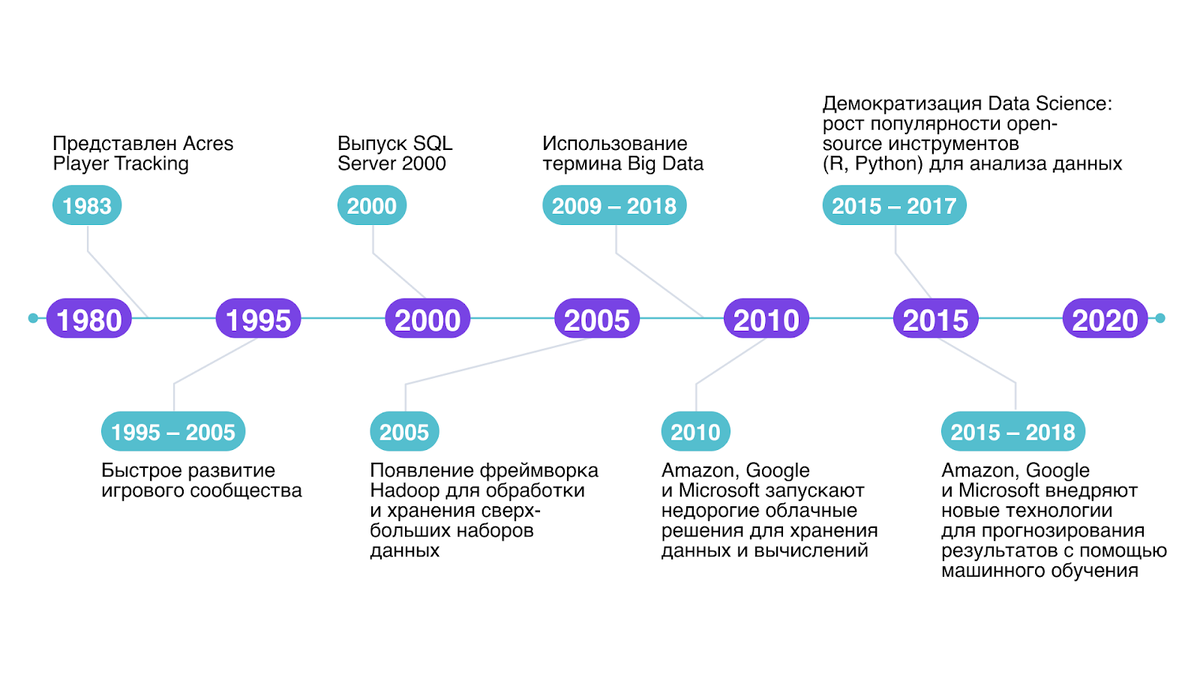
Считается, что термин Big Data как обозначение массивов данных впервые появился в 2008 году в спецвыпуске Nature, где его использовал редактор журнала Клиффорд Линч. По другим данным, термин встречался и раньше: о больших данных в 1990-х годах говорил информатик Джон Машей.
В 2011 году McKinsey Global Institute опубликовал отчёт о потенциале больших данных, после чего тема стала заметной в бизнес-среде. Через год IDC в отчёте Digital Universe спрогнозировал рост объёмов данных с 0,13 зеттабайта в 2005 до 40 зеттабайт в 2020 год.
Уже в 2013 году термин Big Data появился в Оксфордском английском словаре, с указанием на сложность обработки таких объёмов информации.
По данным Statista, в 2020 году глобальный объём созданных, скопированных и потреблённых данных достиг 59 зеттабайт, а к 2024 году превысил 149 зеттабайт.
Эволюция технологий обработки данных
Первые базы данных появились в 1960-х годах, вместе с развитием систем обработки и хранения информации на магнитных носителях. В начале 1970-х годов были созданы первые реляционные БД, в которых данные хранились в виде связанных через общие поля таблиц.
Ключевым шагом к Big Data стал 2004 год, когда Google представил алгоритм MapReduce. Этот подход позволил обрабатывать большие объёмы данных с помощью масштабируемых кластеров.
На базе MapReduce Дуг Каттинг и Майк Кафарелла разработали фреймворк Hadoop, который в 2008 году Hadoop стал частью Apache Software Foundation. Его стали использовать крупные компании, включая Amazon, The New York Times, eBay.
С 2010 по 2020 год вычислительная мощность выросла примерно в 1000 раз, а стоимость хранения данных снизилась с 1000 долл./ГБ в 1990 году до 0,02 долл./ГБ в 2023 году.
Основные характеристики больших данных
Объём (Volume)
Объём — основная и самая очевидная характеристика Big Data. Его значение растёт с развитием вычислительной техники и хранилищ. В 2008 году Nature писал, что к большим данным можно отнести массивы свыше 150 ГБ. В 2020-х нижняя граница существенно выросла (и продолжает это делать) — чаще говорят о десятках ТБ.
По данным Statista, в 2025 году в мире ежедневно генерируется до 402,74 млн терабайт данных. Основные источники: IoT, социальные сети, научные исследования, стриминг, облачные сервисы, электронная коммерция, финансовые операции. В последние годы к ним добавился генеративный искусственный интеллект как крупный производитель данных.
Скорость (Velocity)
Данные поступают постоянно и требуют обработки в режиме реального времени, часто на уровне до миллиона событий в секунду. Это особенно критично для задач, где задержки недопустимы – например, при сейсмологическом мониторинге или в финансовых системах.
Такие скорости предъявляют высокие требования к инфраструктуре. Например, для потоковой обработки данных нужна пропускная способность от 10 Гбит/с, а время отклика при интерактивной работе – не более 5 мс.
Разнообразие (Variety)
Условно большие данные делят на три типа:
- Структурированные — строго организованные по каким-либо критериям, например, таблицы с данными о студентах.
- Полуструктурированные — с гибкой или непостоянной структурой, как профили в соцсетях или логи.
- Неструктурированные — аудио, видео, текстовые документы, электронные письма, показания датчиков.
Данные могут меняться в зависимости от сезона, поведения пользователей, времени суток и других факторов.
Чтобы было удобно работать с разными типами данных, их сначала объединяют в массив. Один из подходов — ETL. Он включает три этапа: извлечение данных из источника, преобразование в нужный формат и загрузку в целевое хранилище. Также важно управление метаданными — информацией о самих данных, которая помогает в их интерпретации и обработке.
Ценность (Value)
Ценность — это прикладная польза данных. Она помогает бизнесу рассчитать, стоит ли внедрять Big Data в конкретной задаче. Например, автопроизводители анализируют краш-тесты, отзывы клиентов и данные с датчиков, чтобы улучшать конструкции и повышать безопасность. Медиакомпании изучают поведение пользователей, чтобы точнее персонализировать контент.
Big Data позволяют потенциально увеличить прибыль на 8–10 % и сократить издержки на 10–15 %. С их помощью компании разрабатывают новые продукты, оптимизируют процессы, корректируют маркетинговые стратегии. Так, в 2018 году компания H&M убрала с полок 40 % ассортимента, не потеряв в продажах. Это помогло остановить падение прибыли и избежать банкротства.
Достоверность (Veracity)
Это точность, полнота и надёжность информации. Некорректные или неполные данные могут привести к неверным выводам и неэффективным решениям. Достоверность особенно важна в медицине или финансах, где ошибка может стоить слишком дорого.
Для повышения качества данных используют несколько подходов:
- Валидация — проверка согласованности, полноты, формата и логики.
- Очистка — удаление дублей, исправление ошибок, заполнение пропущенных значений.
- Верификация источников — оценка их надёжности и авторитетности.
Технологии и инструменты для работы с Big Data
Платформы и фреймворки
Фреймворк Apache Hadoop — одна из ключевых технологий в работе с большими данными. Он включает распределённую файловую систему HDFS и реализацию алгоритма MapReduce. Другой популярный инструмент — Apache Spark, обеспечивает более высокую скорость благодаря обработке данных в оперативной памяти. Также применяются Apache Tez, Druid, HP Vertica, Calpont и другие.
Для хранения данных в экосистеме Hadoop используются SQL-инструменты — Hive, Spark SQL, Impala, а также NoSQL-решения, например, HBase. Из облачных платформ наиболее распространены Google Cloud Storage, Amazon S3, Microsoft Azure, Yandex Cloud. Поисковая система Elasticsearch обеспечивает горизонтально масштабируемый поиск. Брокер сообщений Apache Kafka поддерживает потоковую обработку данных с высокой пропускной способностью.
Языки программирования и библиотеки
Для работы с большими данными используют разные языки программирования:
- Python популярен благодаря множеству библиотек для анализа данных и машинного обучения.
- R включает пакеты для статистического анализа и обработки данных.
- Scala обеспечивает высокую скорость благодаря поддержке параллельных вычислений; на нём основаны Spark и Kafka.
Также широко применяются библиотеки TensorFlow и PyTorch — для машинного обучения, построения нейросетей, распознавания образов и других задач, связанных с анализом больших данных.
Области применения больших данных
Бизнес и маркетинг
Одна из наиболее активно развивающихся сфер применения Big Data — бизнес и маркетинг. Компании используют большие данные для персонализации предложений, оптимизации процессов, разработки рекламных стратегий и повышения лояльности клиентов.
Например, Netflix анализирует поведение пользователей: время суток, выбранное для просмотра, продолжительность выбора, частоту и периодичность постановки видео на паузу. Это позволяет формировать персонализированные рекомендации, на которые, по оценкам агентства Orcan Intelligence, приходится до 80% всех просмотров контента на платформе.
Amazon применяет Big Data для анализа корзин покупателей, построения рекомендаций, динамического ценообразования, таргетированной рекламы и оптимизации логистики. Торговая сеть Walmart, внедрив текстовый анализ и алгоритмы машинного обучения в поисковую систему, повысила конверсию на 10–15 %.
Медицина и здравоохранение
В медицине технологии Big Data применяются для решения широкого круга задач:
- Оценка рисков развития заболеваний, подбор наиболее эффективных лекарств и прогнозирование исходов лечения.
- Мониторинг данных о заболеваемости, распространении вирусов и других эпидемиологических показателей.
- Сбор и анализ информации о пациентах для разработки новых лекарств и методов диагностики.
Компания Apple использовала технологии обработки больших данных при внедрении функции ЭКГ в смарт-часы Apple Watch. А в проекте по расшифровке генома человека Big Data применяются для анализа ДНК и выявления генетических причин заболеваний.
Наука и исследования
Big Data играет ключевую роль в современных научных исследованиях. Один из самых ярких примеров — работа Большого адронного коллайдера (LHC) ЦЕРН. Он генерирует около 30 петабайт данных в год, регистрируя сотни миллионов столкновений частицам. Датчики, установленные внутри коллайдера, фиксируют световую энергию, испускаемую во время столкновений, и преобразуют её в данные для анализа. В 2013 году, благодаря обработке этих массивов, ЦЕРН сообщил об обнаружении бозона Хиггса.
Другие области применения Big Data в науке включают:
- Астрономию, где большие данные помогают обнаруживать новые планеты и исследовать эволюцию Вселенной.
- Экологию, где анализ данных позволяет изучать взаимодействие экосистем и прогнозировать изменения климата.
Преимущества и вызовы использования Big Data
Возможности для оптимизации процессов
Внедрение Big Data в различные отрасли бизнеса позволяет достичь таких результатов:
- Сокращение затрат на инвентаризацию и логистику на 10–20%.
- Ускорение операций на 10%.
- Повышение производительности по сравнению с конкурентами на 5%.
- Увеличение прибыли на 6%.
Большие данные позволяют ускорить процесс принятия решений, автоматизировать рутинные операции, оптимизировать численность персонала. Технологии машинного обучения способствуют более точному профилированию клиентов и улучшению качества обслуживания. Анализ потребительского поведения помогает разрабатывать эффективные маркетинговые стратегии и оптимизировать продуктовые линейки.
Этические и правовые аспекты
Несмотря на множество возможностей, которые дают технологии Big Data, их внедрение связано с определёнными рисками. В первую очередь они касаются конфиденциальности и возможного злоупотребления персональными данными. По данным IBM, в 2024 году средняя стоимость утечки данных составила почти 5 млн долларов.
Для минимизации этих рисков государства разрабатывают механизмы регулирования. В 2016 году в ЕС был принят Общий регламент по защите данных (GDPR), регулирующий сбор, хранение и использование данных пользователей. Несоблюдение его норм привело к крупным штрафам для таких компаний, как British Airways (204 млн евро) и сеть отелей Marriott (110 млн евро). В 2018 аналогичный закон был принят году в Калифорнии, США.
Другая важная проблема Big Data – киберпреступность. Злоумышленники могут получить доступ к конфиденциальной информации и использовать её для фишинга, банковского мошенничества и страховых афер. Также большие данные используют для распространения дезинформации и фейковых новостей.
Заключение
Big Data — это не просто большой объём информации, а горизонтально масштабируемая система, использующая совокупность методик и технологий для обработки как структурированных, так и неструктурированных данных.
Развитие технологий больших данных уже изменило множество отраслей: от бизнеса и маркетинга до медицины и науки. Компании получают конкурентные преимущества, а учёные — новые инструменты для открытий.
Наравне с возможностями есть и вызовы: вопросы конфиденциальности и безопасности, этические риски и необходимость совершенствования законодательного регулирования. Баланс между использованием потенциала больших данных и защитой прав человека становится одной из ключевых задач современного цифрового общества.