Алгоритм поиска подстроки Рабина-Карпа – это метод, который разработан для нахождения всех вхождений подстроки в текст с использованием хэширования строк. Этот алгоритм особенно полезен, когда необходимо искать множество образцов в одном и том же тексте.

Принципы работы алгоритма Рабина-Карпа
Основной принцип Рабина-Карпа заключается в использовании хеш-функции для вычисления "отпечатка" подстроки и сравнения его с хеш-функцией различных частей текста. Если отпечаток подстроки и текущая часть текста совпадают, происходит дополнительная проверка совпадения символов на идентичность.
Алгоритм состоит из следующих этапов:
- Вычисление хеша подстроки.
- Обход текста с последовательным вычислением хешей всех подстрок того же размера.
- Сравнение хешей, и, в случае совпадения, дополнительное сравнение строк.
Пример реализации алгоритма Рабина-Карпа на Python
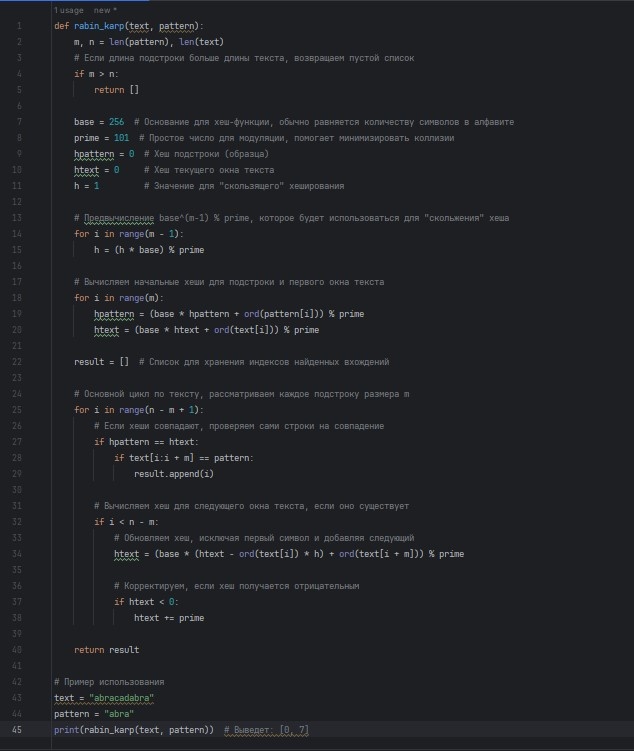
Тот же код ниже для копирования и вставки в программу. Не забывайте про необходимый отступ пробелами в определённых местах в начале строки, так как код на сервере блога может отображаться некорректно.
def rabin_karp(text, pattern):
m, n = len(pattern), len(text)
# Если длина подстроки больше длины текста, возвращаем пустой список
if m > n:
return []
base = 256 # Основание для хеш-функции, обычно равняется количеству символов в алфавите
prime = 101 # Простое число для модуляции, помогает минимизировать коллизии
hpattern = 0 # Хеш подстроки (образца)
htext = 0 # Хеш текущего окна текста
h = 1 # Значение для "скользящего" хеширования
# Предвычисление base^(m-1) % prime, которое будет использоваться для "скольжения" хеша
for i in range(m - 1):
h = (h * base) % prime
# Вычисляем начальные хеши для подстроки и первого окна текста
for i in range(m):
hpattern = (base * hpattern + ord(pattern[i])) % prime
htext = (base * htext + ord(text[i])) % prime
result = [] # Список для хранения индексов найденных вхождений
# Основной цикл по тексту, рассматриваем каждое подстроку размера m
for i in range(n - m + 1):
# Если хеши совпадают, проверяем сами строки на совпадение
if hpattern == htext:
if text[i:i + m] == pattern:
result.append(i)
# Вычисляем хеш для следующего окна текста, если оно существует
if i < n - m:
# Обновляем хеш, исключая первый символ и добавляя следующий
htext = (base * (htext - ord(text[i]) * h) + ord(text[i + m])) % prime
# Корректируем, если хеш получается отрицательным
if htext < 0:
htext += prime
return result
# Пример использования
text = "abracadabra"
pattern = "abra"
print(rabin_karp(text, pattern)) # Выведет: [0, 7]
Пояснение кода
- Инициализация: Определяем длины подстроки (m) и текста (n). Проверяем, если подстрока длиннее текста, сразу возвращаем пустой список.
- Параметры хеш-функции: Используем base для количества символов (например, 256 для ASCII) и prime для модуляции, что уменьшает вероятность коллизий.
- Предварительные вычисления: Вычисляем коэффициент h для последующего сдвига хеша.
- Хеширование: Определяем начальные хеши для подстроки и первого окна текста.
- Основная логика алгоритма: Проходим по тексту, при совпадении хешей сравниваем строки, чтобы исключить ложные совпадения. Обновляем хеш для следующего сегмента текста и корректируем его от отрицательных значений.
- Результат: Возвращаем список с индексами, где были найдены совпадения.
Результат работы кода:
Рекомендации по Улучшению Кода
- Обрабатывайте большие алфавиты: Если есть работа с международными символами, увеличьте base.
- Используйте другие хеш-функции или модули: Если наблюдаете много коллизий, попробуйте другие хеш-методы или модули.
- Параллельная обработка: Если текст очень большой, рассмотрите возможность параллельной обработки его сегментов.
Заключение
Алгоритм Рабина-Карпа - это мощный инструмент для поиска подстрок в строках, особенно полезный в задачах текстового поиска и обработки больших данных. Его эффективность сильно зависит от выбора хеш-функции и модуля, однако его простота и элегантность делают его классическим выбором для разработчиков. Надеюсь, эта статья поможет вам лучше понять и использовать алгоритм в ваших проектах.
Полезные ресурсы:
Сообщество дизайнеров в VK
https://vk.com/grafantonkozlov
Телеграмм канал сообщества
https://t.me/grafantonkozlov
Архив эксклюзивного контента
https://boosty.to/antonkzv
Канал на Дзен
https://dzen.ru/grafantonkozlov
---------------------------------------
Бесплатный Хостинг и доменное имя
https://tilda.cc/?r=4159746
Мощная и надежная нейронная сеть Gerwin AI
https://t.me/GerwinPromoBot?start=referrer_3CKSERJX
GPTs — плагины и ассистенты для ChatGPT на русском языке
https://gptunnel.ru/?ref=Anton
---------------------------------------
Донат для автора блога