В мире огромных массивов данных поиск нужного элемента может оказаться сложной задачей. К счастью, мы имеем в арсенале инструмент, который позволяет выполнять эту задачу быстро и элегантно — алгоритм бинарного поиска. Этот алгоритм значительно ускоряет процесс поиска по сравнению с линейным перебором, особенно в случае больших объемов отсортированных данных.

Основы алгоритма бинарного поиска
Что такое бинарный поиск?
Алгоритм бинарного поиска — это техника поиска, которая позволяет быстро находить нужный элемент в отсортированном массиве данных. Особенностью бинарного поиска является его способность каждый раз делить объем данных на две равные части, что значительно сокращает количество операций.
Как это работает?
- Отсортированные данные: Прежде чем применять бинарный поиск, данные должны быть отсортированы. Это может быть массив чисел (упорядоченных по возрастанию или убыванию) или строки (отсортированные по алфавиту). Если элементами являются объекты, то они должны быть отсортированы по тому свойству, по которому производится поиск.
- Деление пополам: Начинаем с разделения массива пополам и сравниваем искомый элемент с центральным элементом.
- Сужение интервала поиска: Если искомый элемент меньше центрального, повторяем процесс для левой половины массива. Если больше — для правой. В результате у нас, каждый раз, сокращается список поиска в два раза. И каждый раз оставшуюся половину списка мы делим пополам и сравниваем искомый элемент со строкой.
- Повторение: Процесс продолжается до тех пор, пока элемент не будет найден или не будет доказано, что его в массиве нет.
Алгоритм заканчивается, когда или ищется элемент, или остаётся пустой массив для поиска.
В результате у нас количество произведённых операций равно логарифму списка по основанию два.
Временная сложность
Благодаря делению массива на части при каждом шаге, количество операций в худшем случае равно O(log n), где n — количество элементов в массиве. Это означает, что алгоритм бинарного поиска существенно быстрее, чем линейный перебор (O(n)), особенно на больших объемах данных.
Логарифм числа по любому основанию равен отношению натурального логарифма этого числа к натуральному логарифму основания.
Натуральный логарифм числа два это константа, которая не зависит от количества элементов в списке. Константу при оценке временной сложности логарифма мы убираем.
Поэтому временную сложность алгоритма бинарного поиска можно оценить, как логарифм n. Просто логарифм без основания. Не десятичные числа, не натуральные, а просто логарифм n — O(log n).
И логарифма основания нас здесь не интересует, поскольку его всегда можно вывести в константу, а константы мы опускаем, поскольку они не имеют смысла при оценке временной сложности.
Алгоритм бинарного поиска позволяет искать гораздо быстрее, чем поиск линейным перебором, на больших и быстрорастущих объёмах данных.
То есть здесь применяется уже знакомая нам классическая рекурсия, где метод вызывает сам себя и каждый раз всё на меньшем в два раза объёме данных.
Пример реализации бинарного поиска на Python
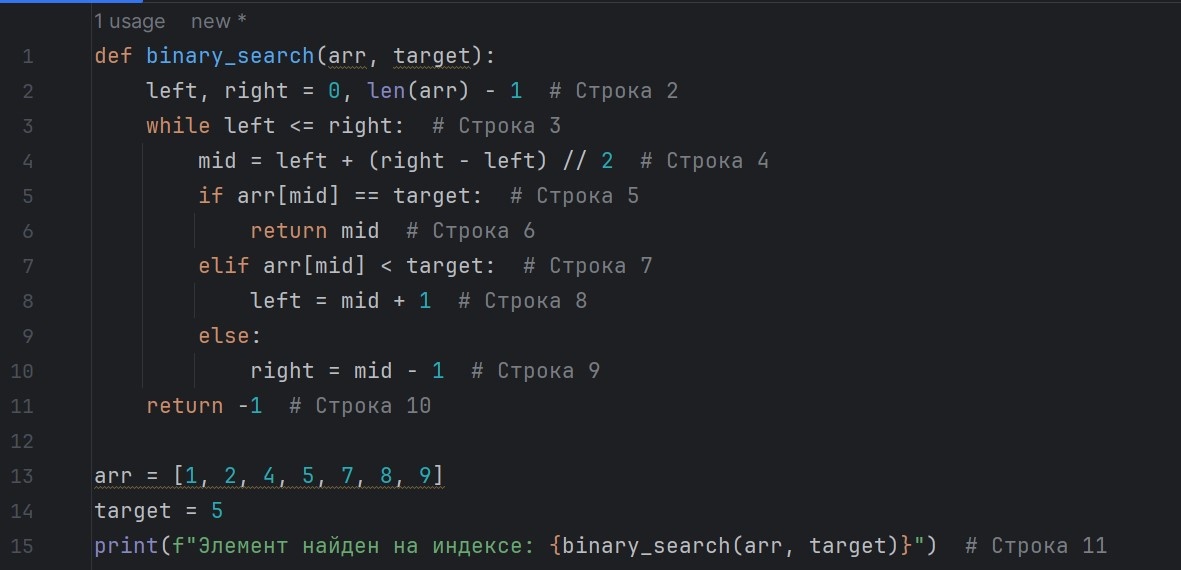
Тот же код ниже для копирования и вставки в программу. Не забывайте про необходимый отступ пробелами в определённых местах в начале строки, так как код на сервере блога может отображаться некорректно.
def binary_search(arr, target):
left, right = 0, len(arr) - 1 # Строка 2
while left <= right: # Строка 3
mid = left + (right - left) // 2 # Строка 4
if arr[mid] == target: # Строка 5
return mid # Строка 6
elif arr[mid] < target: # Строка 7
left = mid + 1 # Строка 8
else:
right = mid - 1 # Строка 9
return -1 # Строка 10
arr = [1, 2, 4, 5, 7, 8, 9]
target = 5
print(f"Элемент найден на индексе: {binary_search(arr, target)}") # Строка 11
Пояснения к коду
- Строка 2: Инициализируем границы поиска: left (начало массива) и right (конец массива).
- Строка 3: Начинаем цикл, который работает до тех пор, пока left не превысит right.
- Строка 4: Вычисляем индекс среднего элемента как mid. Используем left + (right - left) // 2 для избежания переполнения.
- Строка 5: Проверяем, соответствует ли средний элемент искомому значению.
- Строка 7-9: Если средний элемент меньше целевого, обновляем left, сдвигая его вправо. Если больше — обновляем right, сдвигая его влево.
- Строка 10: Если элемент не найден, возвращаем -1.
- Строка 11: Выводим результат поиска.
Результат работы кода:
Рекомендации по улучшению кода
- Проверка данных: Перед выполнением бинарного поиска данные должны быть отсортированными. Это можно сделать через функцию сортировки до основного поиска.
- Обработка исключений: Убедитесь, что программу можно корректно запустить даже с пустыми или некорректными данными.
Заключение
Алгоритм бинарного поиска — это мощный инструмент для быстрого и эффективного решения задачи поиска в больших объемах данных. Его применение существенно сокращает количество операций, что делает его предпочтительным выбором в высоконагруженных системах и приложениях. Понимание и правильное использование этого алгоритма позволят программистам оптимизировать свои программы, добиваясь большей производительности и эффективности. Не забывайте: бинарный поиск — это быстрый и надежный способ найти иголку в стоге отсортированного сена.
Полезные ресурсы:
Сообщество дизайнеров в VK
https://vk.com/grafantonkozlov
Телеграмм канал сообщества
https://t.me/grafantonkozlov
Архив эксклюзивного контента
https://boosty.to/antonkzv
Канал на Дзен
https://dzen.ru/grafantonkozlov
---------------------------------------
Бесплатный Хостинг и доменное имя
https://tilda.cc/?r=4159746
Мощная и надежная нейронная сеть Gerwin AI
https://t.me/GerwinPromoBot?start=referrer_3CKSERJX
GPTs — плагины и ассистенты для ChatGPT на русском языке
https://gptunnel.ru/?ref=Anton
---------------------------------------
Донат для автора блога