В мире алгоритмов поиска, где эффективность имеет первостепенное значение, алгоритм Бойера-Мура занимает заслуженное место как один из самых быстрых и эффективных методов поиска подстроки в строке. Он особенно выделяется своей способностью ускорять процесс поиска за счет использования двух ключевых эвристик: "сдвиг плохого символа" и "сдвиг хорошего суффикса". В этой статье мы разберемся, как работает этот алгоритм, представим примеры на Python с рабочим кодом и дадим советы по его усовершенствованию.

Основы алгоритма
Алгоритм Бойера-Мура разработан для поиска подстроки (паттерна) в строке (тексте) с временной сложностью O(n + m), где n — длина текста, а m — длина паттерна. Эта эффективность достигается за счет анализа символов паттерна и текста в уникальной манере.
Два типа сдвигов:
- Сдвиг плохого символа: Когда мы находим несовпадение, мы анализируем символ текста, который вызвал несоответствие, и сдвигаем паттерн так, чтобы следующее возможное совпадение было максимально быстрым. Если этого символа нет в левой части паттерна, то паттерн сдвигается дальше на единицу за символ.
- Сдвиг хорошего суффикса: Если часть прочитанной подстроки совпала с концом паттерна (хороший суффикс), мы используем информацию об этом суффиксе, чтобы сдвинуть паттерн к его следующему потенциальному совпадению.
Пример задачи:
Представим себе ситуацию: Вам нужно найти специфическую последовательность символов (паттерн) в огромном геноме (тексте). Использование алгоритма Бойера-Мура поможет сделать это эффективно и быстро.
Префиксы и Суффиксы
- Префикс — это начальная часть строки. Например, для строки "abcdef", префиксы могут быть "a", "ab", "abc", "abcd", "abcde". Префикс не может быть равным или длиннее самой строки.
- Суффикс — это конечная часть строки. Для той же "abcdef", суффиксами будут "f", "ef", "def", "cdef", "bcdef". Суффикс также не может быть равным или длиннее самой строки.
Реализация на Python
Вот простая реализация алгоритма Бойера-Мура с пояснениями:
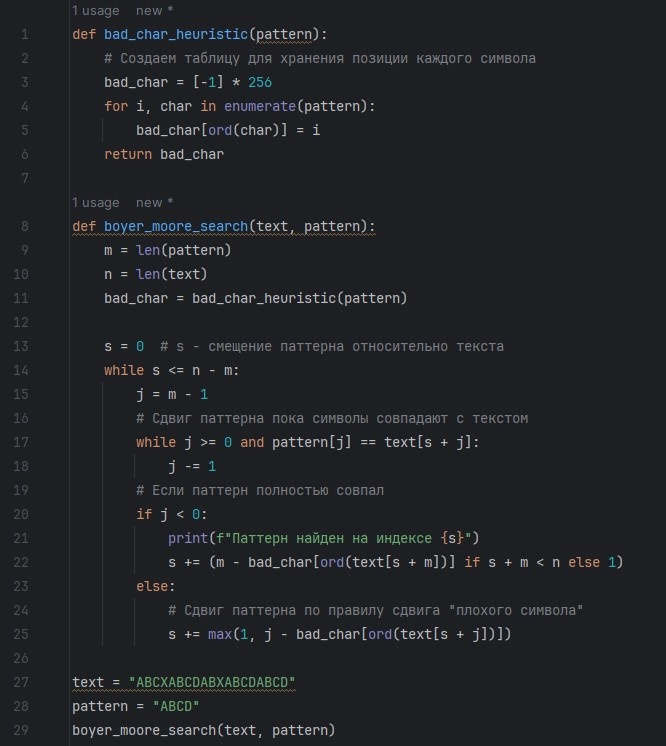
Тот же код ниже для копирования и вставки в программу. Не забывайте про необходимый отступ пробелами в определённых местах в начале строки, так как код на сервере блога может отображаться некорректно.
def bad_char_heuristic(pattern):
# Создаем таблицу для хранения позиции каждого символа
bad_char = [-1] * 256
for i, char in enumerate(pattern):
bad_char[ord(char)] = i
return bad_char
def boyer_moore_search(text, pattern):
m = len(pattern)
n = len(text)
bad_char = bad_char_heuristic(pattern)
s = 0 # s - смещение паттерна относительно текста
while s <= n - m:
j = m - 1
# Сдвиг паттерна пока символы совпадают с текстом
while j >= 0 and pattern[j] == text[s + j]:
j -= 1
# Если паттерн полностью совпал
if j < 0:
print(f"Паттерн найден на индексе {s}")
s += (m - bad_char[ord(text[s + m])] if s + m < n else 1)
else:
# Сдвиг паттерна по правилу сдвига "плохого символа"
s += max(1, j - bad_char[ord(text[s + j])])
text = "ABCXABCDABXABCDABCD"
pattern = "ABCD"
boyer_moore_search(text, pattern)
Пояснения к коду:
- bad_char_heuristic: Создаем массив bad_char, в котором хранится информация о последней позиции каждого символа в паттерне. Это позволит быстро находить, насколько сдвигать паттерн при несовпадении.
- boyer_moore_search: Основная функция алгоритма, которая использует bad_char_heuristic. Она постепенно сдвигает паттерн по тексту и ищет те участки, где происходит полное совпадение.
- s = 0: Начальная позиция смещения паттерна относительно текста.
- j = m - 1: Начинаем сравнение с последнего символа паттерна.
- j -= 1: Уменьшаем j, если символы совпали, и продолжаем сравнивать влево.
- s += max(1, j - bad_char[ord(text[s + j])]): Используем правило сдвига плохого символа для продолжения поиска.
Результат работы кода:
Рекомендации по усовершенствованию:
- Сдвиг хорошего суффикса: Существует возможность улучшить алгоритм, добавив обработку хорошего суффикса, что в некоторых случаях может привести к более значительным сдвигам и ускорению поиска.
- Производительность: Убедитесь, что используете оптимальные структуры данных (такие как bytearray или numpy для больших данных), чтобы хранение и доступ к данным был более быстрым.
Заключение
Алгоритм Бойера-Мура остается одним из самых быстрых методов поиска подстроки, благодаря своему детальному использованию эвристик "плохого символа" и "хорошего суффикса". Понимание этих концепций открывает двери для еще более оптимизированных и собственных решений на их основе. С помощью данного алгоритма поиск становится не только быстрым, но и математически эстетичным, подобно оркестру, исполняющему сложную симфонию.
Полезные ресурсы:
Сообщество дизайнеров в VK
https://vk.com/grafantonkozlov
Телеграмм канал сообщества
https://t.me/grafantonkozlov
Архив эксклюзивного контента
https://boosty.to/antonkzv
Канал на Дзен
https://dzen.ru/grafantonkozlov
---------------------------------------
Бесплатный Хостинг и доменное имя
https://tilda.cc/?r=4159746
Мощная и надежная нейронная сеть Gerwin AI
https://t.me/GerwinPromoBot?start=referrer_3CKSERJX
GPTs — плагины и ассистенты для ChatGPT на русском языке
https://gptunnel.ru/?ref=Anton
---------------------------------------
Донат для автора блога