Алгоритмы поиска подстрок представляют собой важный инструмент в арсенале любого программиста, работающего с обработкой текстов. Один из них, алгоритм Кнута-Морриса-Пратта (КМП), заслуженно считается одним из самых эффективных. В этой статье мы погрузимся в суть этого алгоритма, разберем его по шагам и рассмотрим, как он может быть реализован на Python. Также предложим пути улучшения базовой реализации.

Что такое алгоритм Кнута-Морриса-Пратта?
Алгоритм Кнута-Морриса-Пратта решает проблему поиска подстроки ("образца") в строке ("тексте") за линейное время. Основная идея состоит в том, чтобы использовать информацию, собранную во время неудачных попыток подстрок, для уменьшения количества проверок.
Алгоритм поиска подстроки Кнута-Морриса-Пратта (КМП) является эффективным методом для поиска подстроки в строке. Он основан на сравнении символов строки и подстроки, используя предварительно вычисленный массив "префиксов", что позволяет избежать повторных сравнений.
Описание алгоритма:
- Подготовка массива префиксов:
Этот массив (или таблица) хранит длину самой длинной подошедшей подстроки в строке, начиная с первого символа и заканчивая каждым символом. Он позволяет узнать, на сколько можно сместить подстроку, если произошел сбой в сравнении. - Поиск:
Используя массив префиксов, основной алгоритм сравнивает символы строки и подстроки. При возникновении несовпадения, вместо того чтобы начинать поиск с первого символа подстроки, он использует информацию из массива префиксов, чтобы продолжить с уже известными совпадениями.
Теоретические основы
Алгоритм КМП использует предобработку образца, которая формирует массив "π" (π-функция), называемую префиксной функцией. Этот массив помогает пропускать ненужные сравнения в процессе поиска.
Давайте рассмотрим простой пример:
- Текст: "ababcabcabababd"
- Образец: "ababd"
Алгоритм создает массив, который показывает, какую длину предыдущей наибольшей частичной строки надо «сбросить», если произойдет несовпадение.
Время выполнения:
Алгоритм Кнута-Морриса-Пратта (KMP) имеет линейное время выполнения — O(n + m), где n — длина текста, а m — длина шаблона (паттерна).
Реализация на Python
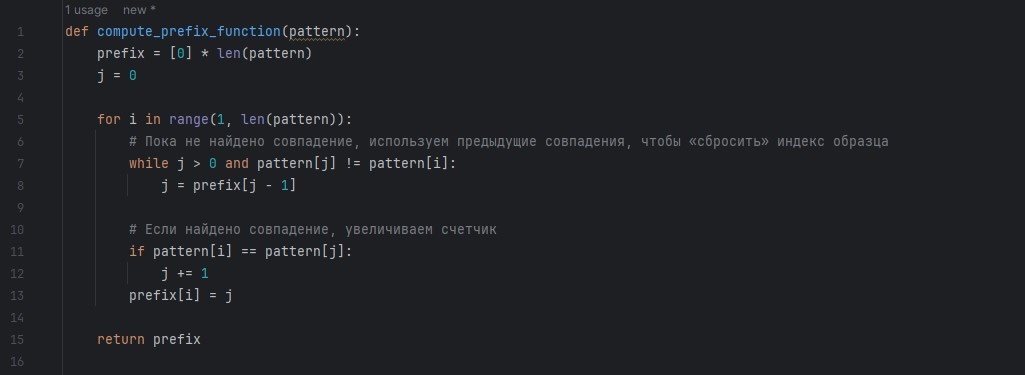
Тот же код ниже для копирования и вставки в программу. Не забывайте про необходимый отступ пробелами в определённых местах в начале строки, так как код на сервере блога может отображаться некорректно.
def compute_prefix_function(pattern):
prefix = [0] * len(pattern)
j = 0
for i in range(1, len(pattern)):
# Пока не найдено совпадение, используем предыдущие совпадения, чтобы «сбросить» индекс образца
while j > 0 and pattern[j] != pattern[i]:
j = prefix[j - 1]
# Если найдено совпадение, увеличиваем счетчик
if pattern[i] == pattern[j]:
j += 1
prefix[i] = j
return prefix
def kmp_search(text, pattern):
if not pattern:
return [] # Возвращаем пустой список, если образец пустой
prefix = compute_prefix_function(pattern)
j = 0 # Индекс в образце
indices = [] # Список индексов для всех найденных совпадений
for i in range(len(text)):
# Пока накопленный индекс не совпадает, сбрасываем используя массив префикс-функции
while j > 0 and text[i] != pattern[j]:
j = prefix[j - 1]
# Если символы совпадают, увеличиваем индекс и в образце
if text[i] == pattern[j]:
j += 1
# Если весь образец совпал, фиксируем совпадение
if j == len(pattern):
indices.append(i - j + 1)
j = prefix[j - 1] # Для поиска следующего потенциального совпадения
return indices
# Пример использования:
text = "abc abcdefabcd"
pattern = "abcd"
print(kmp_search(text, pattern))
Результат работы кода:
Расшифровка строчек кода
- Создаем префиксную функцию: prefix = [0] * len(pattern) — инициализируем массив нулями, размер которого равен длине образца.
- Инициализация: j = 0 — индекс текущей позиции в образце.
- Префиксная функция: основной цикл for проходит по всем символам образца. Если присутствует несовпадение, используется информация из prefix для смещения в пределах образца, избегая повторных проверок ранее проверенных символов.
- Поиск с использованием КМП: во втором методе kmp_search мы используем информацию из функции префиксов для поиска образца в тексте, проверяя и обновляя индекс позиции в образце j.
- Обнаружение совпадения: если j достигает длины образца, это означает, что образец найден, и мы можем вывести индекс начала совпадения.
Примеры задач
- Задача 1: Найдите индекс первого вхождения подстроки "abcd" в строке "abc abcdefabcd".
- Задача 2: Определите, сколько раз подстрока "aaa" встречается в строке "aaaaaa".
Рекомендации по усовершенствованию
- Улучшенная обработка выводов: Вместо немедленного печатания результата, функция может возвращать список индексов всех вхождений, что позволяет более гибко обрабатывать результаты.
- Обработка отмененных выполнений: Добавьте проверку пустых строк и обработку случаев, когда образец длиннее текста, чтобы избежать излишних вычислений.
Заключение
Алгоритм Кнута-Морриса-Пратта является мощным инструментом для поиска подстрок в строках текстов. Его основное преимущество — линейная сложность времени выполнения, что делает его очень эффективным для больших объемов данных. Правильное понимание и применение этого алгоритма может значительно оптимизировать задачи, связанные с текстовой обработкой. Усовершенствования базовой реализации позволяют еще больше повысить производительность и универсальность. Надеюсь, эта статья помогла вам лучше понять алгоритм КМП и вдохновила на его использование в ваших проектах!
Полезные ресурсы:
Сообщество дизайнеров в VK
https://vk.com/grafantonkozlov
Телеграмм канал сообщества
https://t.me/grafantonkozlov
Архив эксклюзивного контента
https://boosty.to/antonkzv
Канал на Дзен
https://dzen.ru/grafantonkozlov
---------------------------------------
Бесплатный Хостинг и доменное имя
https://tilda.cc/?r=4159746
Мощная и надежная нейронная сеть Gerwin AI
https://t.me/GerwinPromoBot?start=referrer_3CKSERJX
GPTs — плагины и ассистенты для ChatGPT на русском языке
https://gptunnel.ru/?ref=Anton
---------------------------------------
Донат для автора блога