Если попросить любую нейросеть нарисовать человека, результат будет впечатляющим: реалистичная кожа, выражение лица, текстура волос — будто фотография. А потом взгляд цепляется за руку. Шесть пальцев. Иногда семь. Иногда два больших пальца на одной ладони.
И всё, магия исчезла. Почему так происходит в 2025 году, когда нейросети умеют дописывать музыку, монтировать видео и решать сложнейшие задачи на уровне профессионалов? Давайте разберемся без клише и на пяти пальцах.

Нейросети не «видят», как люди
Когда мы говорим о нейросетях, создающих картинки, важно понимать: они не рисуют, как человек с карандашом в руке. У них нет представления о мире, объектах, руках, лицах или деревьях. У них даже нет зрительного восприятия в нашем понимании. Как работает на самом деле?
1. Всё начинается с случайного шума. Генерация изображения обычно стартует с чистого случайного поля — буквально из хаотичного шума. Этот подход называется диффузионной моделью. Например, Stable Diffusion, Midjourney и DALL-E работают именно так.
2. Пошаговая «очистка» изображения. Алгоритм итеративно «очищает» этот шум, добавляя на картинку элементы, которые статистически соответствуют запросу («женщина с чашкой кофе», «кошка на скейте», «собака в очках»). На каждом шаге он чуть-чуть корректирует изображение, отталкиваясь от заложенных «ощущений» правильности.
3. Статистика вместо понимания. Нейросеть не знает, что такое чашка кофе или кошка. Она знает только, что в миллионах картинок, которые она видела, определённые формы, цвета и текстуры часто встречаются вместе. Она сопоставляет вероятности: здесь обычно тёмное пятно (значит тень), здесь изгиб (значит, возможно, рука).
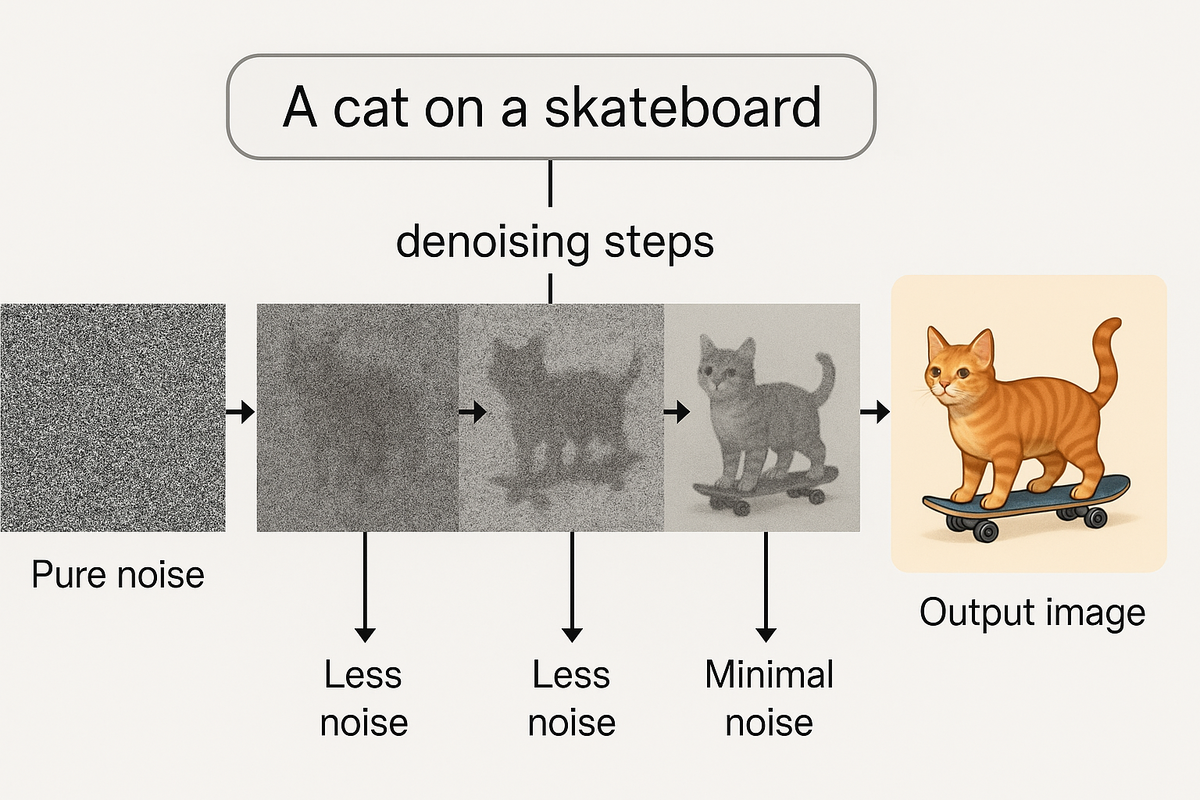
4. Влияние текстового запроса. При генерации текста используют текстовые эмбеддинги — особые числовые представления фраз. Они направляют, в каком стиле и на какую тему вести процесс «очистки» шума. То есть, если попросить «реалистичное лицо», нейросеть будет подтягивать именно те паттерны, которые часто встречались на фотографиях людей.
5. Никакого «рисования частей». Нейросеть не делает сначала глаза, потом нос, потом уши. Она работает глобально: распределяет вероятность того, что в этом пикселе должен быть глаз, а в этом — фон. Из-за этого иногда появляются лишние части тела: например, ещё один палец или третья нога — просто потому, что в процессе уточнения формы статистика "решила", что там логично добавить ещё один элемент.
В итоге генератор изображений — это очень сложная машинерия вероятностей, а не «художник в компьютере».
Свежие новости, гаджеты, промпты и статьи у нас в тг:
Данные для обучения были… несовершенными
Всё начинается с того, на чём сеть училась. На миллионах изображений из интернета. Но интернет полон странных фото:
- художники любят рисовать монстров с лишними пальцами;
- фотографии могут быть смазанными;
- пальцы могут перекрываться и сливаться друг с другом;
- иногда руки вообще частично закрыты предметами.
И нейросеть «увидела», что пальцев бывает разное количество. Иногда четыре. Иногда шесть. А значит, подумала она, шесть пальцев — это вполне себе вариант нормы.
Более того, в датасетах часто не было пояснений типа «вот здесь у персонажа мутация». Сеть просто запомнила «всё подряд» без фильтрации.
Руки — это вообще сложная штука
Даже для людей рисовать руки трудно. Мало кто из начинающих художников скажет иначе. А теперь представьте, каково это нейросети, у которой нет ни мышечной памяти, ни понимания пропорций.
Рука — это комбинация множества маленьких элементов (пальцев), сложной анатомии (суставы, изгибы) и динамики (разные ракурсы, движения). Ошибись на миллиметр — палец появится там, где его быть не должно.
При этом нейросети стали лучше: если в 2022 году шестипалые руки были в каждой второй генерации, то в 2025-м — лишь иногда, особенно в сложных сценах. Но пока что до стопроцентной безошибочности далеко.
Почему до сих пор не «починили»?
Потому что исправлять такие ошибки — отдельная, очень сложная задача.
Нужно встроить в модель понимание анатомии, а не просто статистику пикселей. То есть не только запоминать, как выглядит рука, но и знать: пять пальцев, три фаланги на каждом, большой палец противопоставлен остальным.
И часть разработчиков уже пробует это сделать через так называемые control models — вспомогательные сети, которые проверяют, правильно ли сгенерирована поза, пропорции и количество частей тела.
Другие команды учат нейросети на специальных «чистых» датасетах, где каждый палец размечен вручную. Это медленно, дорого и не даёт мгновенного результата.
Когда нейросети перестанут косячить с руками?
Рано или поздно, конечно, научатся. Уже сейчас многие сервисы автоматически «доправляют» руки после генерации, но полного понимания образов — того самого, как у человека, — у нейросети пока нет.
Так что пока можно считать шестипалые руки милым реликтом ранней эпохи ИИ. И, кто знает, может быть через сто лет художники будут специально добавлять лишние пальцы в свои картины — в знак уважения к тем временам, когда нейросети только учились видеть мир.
Какие еще странные «элементы» вы замечаете в сгенерированных картинках людей?
Подписывайся на наш Telegram-канал — там всё самое интересное! Если статья зашла, угости автора кофе 💵.
Читайте также: