При проектировании схем данных с учётом производительности и масштабируемости используются различные паттерны и подходы, которые помогают эффективно работать с большими объёмами данных и повышать скорость выполнения запросов. Рассмотрим основные паттерны и принципы.
Шардирование (Sharding)
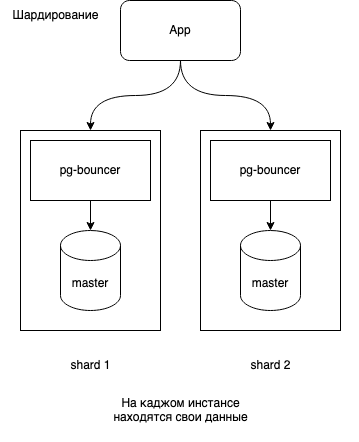
Шардирование — это разбиение данных на несколько частей, каждая из которых хранится на отдельном сервере или узле. Этот подход помогает распределить нагрузку на несколько баз данных и улучшить масштабируемость системы.
Горизонтальное шардирование:
Таблица разбивается по строкам, например, на основе ключа пользователя (user_id), каждая часть хранится на отдельном сервере.
Пример:
Если у нас есть пользователи с ID от 1 до 10 000, можно разделить данные на 4 шардов:
- Шард 1: данные пользователей с ID 1–2500.
- Шард 2: данные пользователей с ID 2501–5000.
- Шард 3: данные пользователей с ID 5001–7500.
- Шард 4: данные пользователей с ID 7501–10 000.
Плюсы:
- Масштабируемость — легко добавлять новые узлы в систему.
- Разгрузка системы, уменьшение задержек при больших нагрузках.
Минусы:
- Более сложное управление и реализация (нужно решать проблемы с синхронизацией, распределением данных).
Вертикальное шардирование:
Тип шардирования, при котором данные разделяются не по строкам, а по столбцам таблицы. В отличие от горизонтального шардирования, где вся таблица делится на части по строкам, вертикальное шардирование разбивает таблицу по логически связанным группам столбцов, которые могут храниться на разных серверах.
Пример:
Допустим, у нас есть таблица users, содержащая такие поля, как user_id, name, email, address, phone, profile_picture. Мы можем разделить таблицу на две части:
- Шард 1: хранит поля user_id, name, email, phone — это чаще используемые данные.
- Шард 2: хранит поля user_id, address, profile_picture — менее часто используемые данные.
Это позволяет уменьшить количество данных, которые нужно загружать при выполнении запросов, если, например, часто нужны только базовые данные о пользователе без его профиля или адреса.
Плюсы:
- Оптимизация запросов: позволяет загружать только необходимые данные, что может уменьшить время выполнения запросов.
- Разделение нагрузки: разные столбцы могут использоваться для различных типов операций (например, одни данные часто читаются, другие редко изменяются).
- Лучшее управление данными: можно распределить ресурсоёмкие поля (например, большие поля с изображениями) на отдельные узлы.
Вертикальное шардирование чаще используется, когда нужно оптимизировать запросы и эффективно распределить нагрузку по частям данных, которые могут по-разному использоваться в системе.
Репликация данных
Репликация — это процесс копирования данных с одного узла базы данных на другие. Это позволяет повысить доступность данных и улучшить производительность за счёт разделения нагрузки на чтение.
Индексы
Индексы используются для ускорения поиска данных в таблицах. Они позволяют базе данных быстро находить строки на основе значений в одном или нескольких столбцах, снижая количество сканирований таблицы.
Денормализация данных
Денормализация — это процесс дублирования данных для уменьшения количества JOIN-ов и ускорения чтения данных. Применяется, когда скорость чтения важнее сохранения чистой нормализованной структуры данных.
Пример: Вместо выполнения сложных JOIN-ов для получения информации о заказах и клиентах можно хранить все данные в одной таблице. Это ускоряет запросы на чтение, особенно в системах с высокой нагрузкой.
Более подробно можно ознакомится на моей статье: https://dzen.ru/a/ZxteKqpE8wFsKcsv
Схемы на основе событий (Event Sourcing)
Event Sourcing — это подход, при котором состояние системы не хранится напрямую, а создаётся на основе последовательности событий. Это позволяет отслеживать все изменения системы во времени и легко масштабировать такие системы.
Плюсы:
- Легче масштабировать, так как события можно хранить в распределённых системах.
- Возможность отслеживать и восстанавливать состояние системы на любой момент времени.
Минусы:
- Усложнение архитектуры.
- Потребность в дополнительных системах для обработки и хранения событий.
Паттерн CQRS (Command Query Responsibility Segregation)
CQRS разделяет модель данных на две части:
- Команды (Commands): отвечают за запись данных.
- Запросы (Queries): отвечают за чтение данных.
Таким образом, архитектура чтения и записи данных может быть оптимизирована отдельно для каждой задачи.
Плюсы:
- Ускорение операций чтения и записи, так как они оптимизированы под разные задачи.
- Масштабируемость, особенно в системах с высокой нагрузкой.
Минусы:
- Усложнение системы из-за разделения на два потока работы с данными.
Партиционирование данных
Партиционирование — это разделение данных на более мелкие логические части (партиции) на уровне одной таблицы. Это улучшает производительность, так как запросы могут выполняться на меньших подмножествах данных.
Типы партиционирования:
- Диапазонное партиционирование: данные разделяются на основе диапазонов значений (например, даты).
- Хэш-партиционирование: данные распределяются на основе хэш-функции от значения ключа.
Пример:
Партиционирование таблицы заказов по году:
- Партиция 1: заказы за 2023 год.
- Партиция 2: заказы за 2024 год.
Плюсы:
- Ускорение запросов при работе с большими объёмами данных.
- Облегчение управления архивными данными.
Минусы:
- Более сложная реализация и поддержка.
Кэширование
Кэширование — это использование промежуточного слоя для хранения результатов часто выполняемых запросов. Это особенно полезно для снижения нагрузки на базу данных и ускорения ответов на запросы.
Инструменты для кэширования:
- Redis: in-memory хранилище, которое часто используется для кэширования.
- Memcached: ещё одно популярное решение для кэширования.
Плюсы:
Существенное ускорение работы с часто запрашиваемыми данными.
Минусы:
- Потребность в дополнительной памяти.
- Необходимость управления консистентностью данных между кэшем и основной базой данных.
Заключение
Следуя этим паттернам и подходам вам удастся проектировать масштабируемые, производительные и надёжные системы, которые могут обрабатывать большие объёмы данных и выдерживать высокую нагрузку.