Всем привет! Решил оформить эту небольшую заметку для всех тех, кто хочет перенести свою установку ollama в Docker-контейнер, ничего при этом не потеряв (включая веса загруженных моделей, настройки и ключи шифрования).

Идея данной заметки возникла после очередного обновления ollama которое сбросило мои настройки включающие поддержку flash attention и открывающие порт 11434 на всех интерфейсах, чтобы можно было с внешних машин подключаться.
Указанные настройки выполняются через конфигурационный файл сервиса ollama расположенный по адресу /etc/systemd/system/ollama.service, ну и так вот, при установке обновления указанный файл бы заменён на дефолтный, баг это или фича разбираться лень, проще перенести всё в докер и забыть об этом.
Деинсталяция ollama
Для начала выполним остановку сервиса ollama и удалим конфирацию:
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service
Теперь удаляем пользователя ollama и группу ollama:
sudo userdel ollama
sudo groupdel ollama
Все модели, которые были скачали из библиотеки или созданы врунчю хранятся в /usr/share/ollama, запомним эту директорию, вернёмся к ней чуть позже.
Подготовка docker-compose.yml с сервисом ollama
Создадим пустую директорию, скажем docker-ollama, и в ней файл docker-compose.yml, вот так:
mkdir docker-ollama
cd docker-ollama
touch docker-compose.yml
Заполним его следующим содержимым:
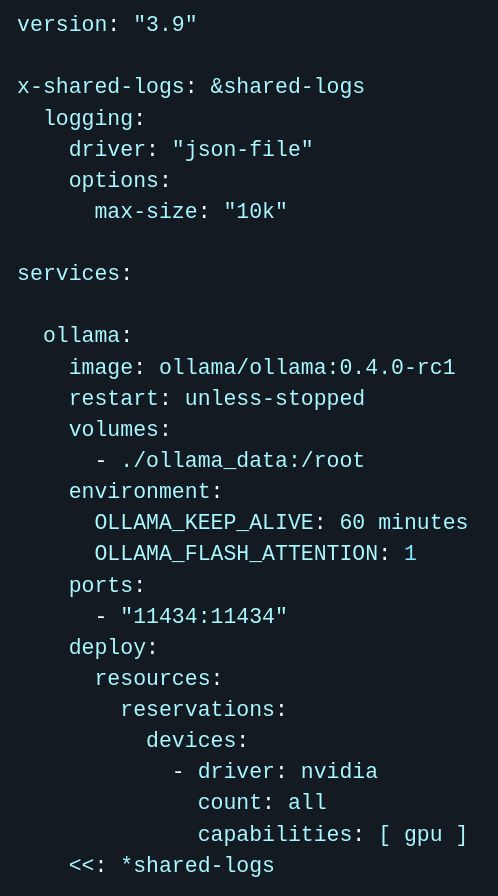
Код тут.
Можно явно указать версии через image директиву, например ollama/ollama:0.4.0-rc1 говорит нам о том, что необходимо взять контейнер с тегом 0.4.0-rc1 и юзать его в дальнейшем.
Все доступные теги у образа ollama/ollama можно посмотреть тут.
В примере конфигурации видно, что в блоке environment активируется поддержка flash attention (которая по умолчанию отключена), а в время жизни модели в памяти меняется с 5 минут по умолчанию на 60 минут.
Далее перенесём папку /usr/share/ollama (о которой было упомянуто ранее) в текущую директорию и поменяем имя на ollama_data:
mv /usr/share/ollama ./ollama_data
На этом подготовка завершена, пробуем запустить.
Запуск композиции
Скачаем образ и запустим композицию:
docker-compose pull
docker-compose up -d
Для обновления `ollama` нужно будет зайти через редактор и подправить тег у image, далее выполнить pull, up -d и вот вы уже на новой версии.
Проверим работоспособность
Предположим, что ollama мы запустили на некоем удалённом сервере с IP-адресом 192.168.1.10, на него и будем делать запросы через curl.
Получим список доступных моделей:
curl http://192.168.1.10:11434/api/tags
В ответе будет список всех моделей которые мы ранее скачали или создали, допустим у нас есть среди прочих модель llama3.2:8b, попробуем выполнить простую генерацию через неё.
curl http://192.168.1.10:11434/api/generate -d '{"model":"llama3.1:8b","stream": false,"prompt":"Почему трава зелёная?"}'
В ответе будет текст сгенерированный моделью, отвечающий на заданный вопрос.
Установка новых и удаление старых моделей
После переезда на Docker-контейнер у нас пропадёт возможность простой и быстрой установки моделей через ollama pull, эту проблему можно решить несколькии способами
Переменная OLLAMA_HOST
Перед вызовом бинарника ollama мы можем передавать переменную окружения, в которой будет указан удалённый хост и порт на котором запущена ollama в Docker-контейнере:
OLLAMA_HOST=192.168.1.6:11434 ollama list
Переменную OLLAMA_HOST можно прописать на постоянной основе:
echo 'export OLLAMA_HOST=192.168.1.6:11434' >> ~/.bashrc
После выполнения указанной комманды наш локальный бинарник ollama будет обращаться в API на удалённом (или локальном) сервере.
[pasha-lt] ~ $ ollama -v
ollama version is 0.4.0-rc1
Warning: client version is 0.3.13
Обновлять консольный клиент отдельно от сервера можно так:
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
В отличии от скрипта install.sh этот метод не устанавливает ollama сервер.
Подключаясь в контейнер
Второй вариант это способ через docker-compose exec, полезен в ситуациях когда нет желания ставить в систему лишние бинарники.
И так, заходим в папку с docker-compose.yml и подключаемся к контейнеру ollama:
cd docker-ollama
docker-compose exec ollama bash
Теперь мы можем использовать консольную утилиту ollama и скажем получить список моделей или запустить нужную модель.
ollama -v
ollama list
ollama run llama3.1:8b
Вот пример:
Через API
Пожалуй самый хитрый способ, я сам им пользуюсь только через Open WebUI, так как лень каждый раз формировать curl запросы, но тем не менее можно с грацией мангуста управлять моделями на удалённом (или локальном) API сервере.
Какие модели есть:
curl http://192.168.1.6:11434/api/tags
Установим модель gemma:2b
curl http://localhost:11434/api/pull -d '{"name": "gemma:2b"}'
Удалим модель gemma:2b
curl -X DELETE http://192.168.1.6:11434/api/delete -d '{"name": "gemma:2b"}'
Вот в принципе и всё что может потребоваться для управлениями моделями на удалённом ollama сервере.
Больше подробностей о работе с ollama API в официальной документации.
Завершение
Ну чтож, надеюсь моя небольшая заметка поможет вам перенести вашу ollama в Docker-контейнер и получить больше гибкости и удобства.
Если у вас остались вопросы или вы хотите узнать больше о нейросетях и машинном обучении, подписывайтесь на мой Телеграм-канал и блог, а также не забудьте поставить лайк этой публикации. Ваши отзывы и поддержка мотивируют меня на создание новых полезных материалов.
Спасибо за внимание и удачи в ваших проектах!