
“Быстро поднятый сервис не считается упавшим!” гласит народная админская мудрость. Но чтобы быстро поднять, надо не менее быстро осознать, что именно упало.
В период моего руководства коллективом админов существовало вполне себе гласное правило: если о падении сервиса я узнаю от инженера раньше, чем от пользователей, вместо кнута достается пряник. Стоит ли говорить, что тут же появляется стремление развернуть покрывающую все подряд (включая наличие зерен в кофемашине) систему мониторинга. Совместный мозговой штурм в составе админов, при поддержке Google и Yandex традиционно приводит к Zabbix (реже Nagios).
Развернули. Лампочки замигали, пакеты забегали. Чуть позже бас пересадили напротив альта, приму против вторы… Потом, предсказуемо, попробовали посадить рядом… Сыр все не падал.
Поскольку подавляющее большинство корпоративных сервисов представлено web, на их примере и будем рассматривать. Хотя, с некоторыми незначительными изменениями, вполне реально таким образом контролировать и экзотику. Если детально посмотреть на задачу, она сводится к следующему:
• нам надо «потрогать» сервис снаружи (причем, желательно, чтобы эта «наружа» была как можно ближе к конечному пользователю);
• нам надо заглянуть на хост, на котором сервис работает, и попробовать дотянуться с него до backend и прочих database зависимостей;
• попутно, желательно собрать параметры состояний хостов – свободное место, свободная память, загрузка процессора.
И, если с последним Zabbix-агент справляется «на ура», то с первыми есть некоторые сложности. Действительно, что толку знать, что Nginx на хосте работает, если он надежно закрыт местным firewall от всех попыток подключения извне? Или, просто, некорректно настроен DNAT на edge?
Но мы же разворачивали сервисы с помощью Ansbile. Зачем менять коня на переправе?
• Доступность сервиса он будет проверять с контрольной машины. Для пущей уверенности подключим в качестве сенсоров парочку VDS, расположенных в «диких Интернетах» и максимально мимикрирующих под конечных пользователей.
• На хост он спокойно забегает, и аналогичным образом с него проверяет доступность backend.
• Раз уж он попал на хост, попутно, почти «из коробки», собирает необходимые параметры состояния хоста. В качестве бонуса может даже попытаться этот самый сервис починить.
• Запускать можем по расписанию, а в случае аномалий постучаться в почту.
Сценарии проверки
В качественно регламентированной среде (в естественной природе практически не встречается) мы изначально знаем, какие именно сервисы должны проверяться. Поэтому смело экспортируем список в какой-нибудь host_vars и пользуемся. Особо продвинутые могут «на лету» добыть его из IPAM или иных учетных систем.
В более реальной ситуации мы можем составить себе список проверок прямо из конфигурации Nginx. Логика здесь предельно простая – раз настроено – должно работать.
Конечно, при практическом применении желательно использовать комбинацию из этих вариантов. Оставляю это на ваше усмотрение.
Начнем с конца
Первый play обходит “reverse_proxy”. На каждом из них считываем полный конфиг с помощью "nginx -T". Выделяем из него все “server_name” для проверки доступности извне. Также выделяем proxy_pass для проверки доступности сервисов от “reverse_proxy”. Заодно собираем факты о состоянии хоста. Получаемые списки могут содержать дублирующиеся записи (например, когда в разных секциях настроены 80 и 443 порты) – избавляемся от них. Еще в "server_names" любит попадать дефолтное название “_”, его тоже пропускаем.
Регулярные выражения, как следует из их названия, регулярно преподносят разного рода сюрпризы. В данном случае, поскольку они находятся в конструкции из двойных, а затем и одинарных кавычек, обратные слеши требуют собственного экранирования. Ну, и, если они по нелепой случайности ничего не найдут, лучше подстраховаться и сделать “list”, чтобы “unique” не вздумал упасть.
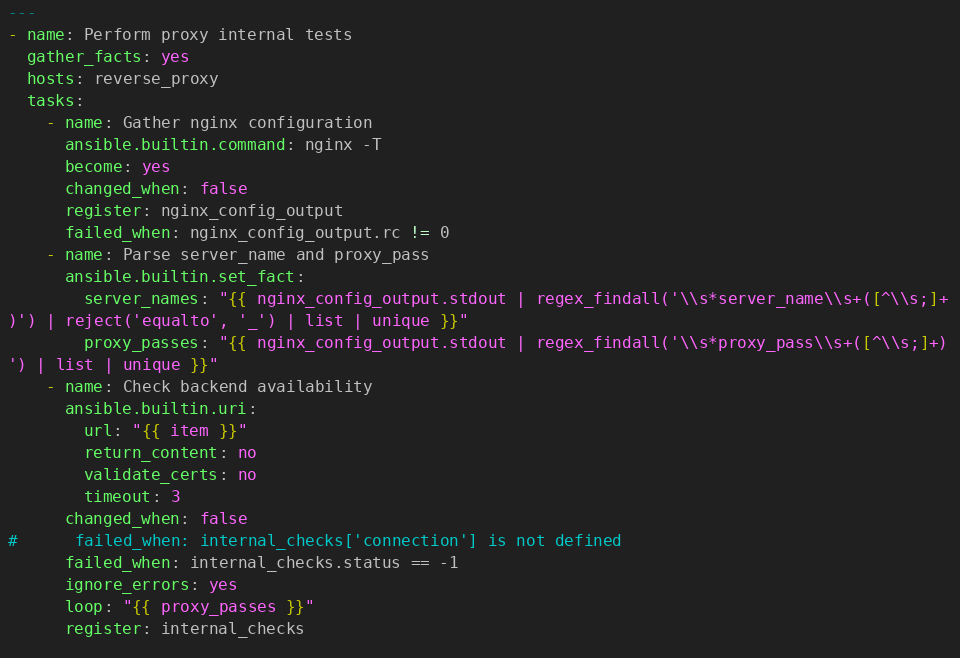
При проходе по списку "proxy_passes" нужно учитывать, что точно не во всех случаях мы получим код 200, которого по-умолчанию ждет ansible.builtin.uri. Но это вовсе не означает ошибку. Сервису может требоваться авторизация, сертификат, мы можем не знать конкретный URI и много других подобных ситуаций. Поэтому нужен другой критерий. Мне достаточно того, что backend установил соединение. Убедиться, что это именно HTTP можно тем, что в фактах появляется свойство “connection”. В более общем случае – при проблемах “status” будет “-1”.
После сбора фактов в переменной "ansible_facts" можно почерпнуть много интересного. А если добавить немного магии, то оказывается, что это вполне себе законченный JSON и в воздухе появляется едва уловимый флер ELK.
Для удобства ручного применения имеет смысл сразу вывести перечень недоступных backend.
“Пациент скорее жив, чем мертв”
Доступность сервиса конечным пользователям проверяем с наших сенсоров (и, как договаривались, с localhost тоже). Для этого опять придется прибегнуть к магическому жезлу. Перечень наших “server_names” находится в фактах каждого из "reverse_proxy".
Из "hostvars" (любезно превращенного “dict2items” в список) выбираем хосты, входящие в нужную группу. А из них только тех, у кого зафиксирован факт “server_names”. Поскольку ничего кроме него не нужно, просим “map” избавить нас от мусора. Сплющиваем полученные списки и выбираем только уникальные значения.
Результаты проверок естественным путем скапливаются в "external_checks".
“Нужно больше золота”
И все же код 200 (ну, или, хотя бы любой другой) гарантирует, что мы смогли установить адекватное HTTP соединение. А иногда и HTTPS. И, в особо оговоренных случаях, предъявили логин, пароль, клиентский сертификат и прочие капчи (“да человек, я, Ч-Е-Л-О-В-Е-К”).
Да и за человеческим фактором надо присматривать. “Так они не ходят! - Странно, только что ходили…” Поэтому составляем регламентированный список сервисов, которые точно BCA. И терпеливо приписываем им все хотелки.
“Программист ставит на ночь стакан с водой, если захочет пить. И пустой стакан, если не захочет”. И снова немного магии нас выручает. Если соответствующий параметр сервису не нужен и в декларации не объявлен – то и предъявлять мы его не будем, потому как “default” у нас пустой.
Вместо заключения
В тексте я уже дал несколько подсказок, как именно можно накапливать полученную информацию. Что касается автоматического периодического запуска playbook, здесь как нельзя кстати может пригодиться Semaphore.
Тем, кто дочитал до этого места желаю четырех девяток доступности.
Код этого playbook для изучения вы можете скачать по ссылке https://gitflic.ru/project/wingedfox/dzen-ansible/file/?file=monitoring&branch=master из моего репозитория.