В этой статье я подробно разберу, как установить текстовую нейросеть "llama3.1" (3.2) на локальный компьютер, и начать пользоваться ей без использования интернета.
Требуемый софт
Нам потребуется два дистрибутива:
- Llama: https://ollama.com
- Docker Desktop: https://www.docker.com
Их надо предварительно скачать.
Скачивание и установка "llama3.1"
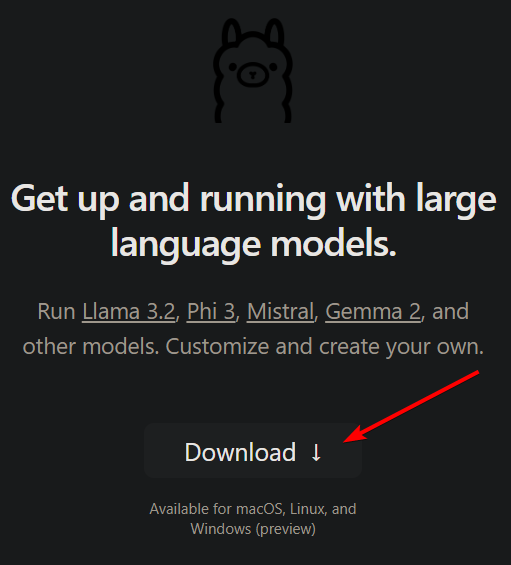
Открываем сайт: https://ollama.com
Жмем "Download":
Вводим свою почту и выбираем систему (я ставлю на Windows 10):
После скачивания запускаем "OllamaSetup.exe".
Он ничего не спрашивает, просто устанавливается сам!
После установки откройте окно терминала и введите ключевую команду
- ollama
Оllama должна ответить вам окном справки.
Идем на сайте по адресу: https://ollama.com/library и выбираем вот эту модель:
В открывшемся окне нам требуется строка установки модели (обведена зеленым) и кнопка копирования команды (зеленая стрелка).
Красными стрелками показаны ссылки на модели, которые имеются в наличии, но они все с другими параметрами, и выбираются в зависимости от мощности вашей компьютерной системы, где "8B" - модель на 4.7 гигабайта.
Есть модели на 40 гигабайт и на 229 гигабайт, вы можете себе поставить и их, лишь бы машина потянула (я же не знаю, вдруг у вас на кухне под столом стоит сервер на 245 процессоров с ядрами cuda и памяти "как у дурака махорки").
Копируем команду ("ollama run llama3.1:8b") и вставляем ее в окно терминала:
Начнется скачивание выбранной модели и будет отображаться состояние ее скачивания:
Поскольку я включил в строку команды команду "run", то сразу по скачиванию и установки модели, "llama" запустится.
Пока скачивается модель, установим "Docker Desktop"
Запустим "Docker Desktop Installer.exe"
Оставим все "по умолчанию", он сам с собой разберется.:
После установки запускам его, подтверждаем условия:
Регистрируемся (я рекомендую через гугл-аккаунт, вопросов меньше):
На вопрос "Хто ты, челядь?" отвечаю всегда "Студент!" по причине того, что многие компании смотрят на эту категорию как на "Давайте ему еще на хлебушек пожертвуем?", и снимают все вопросы, касающиеся денег, поскольку "по умолчанию" считают, что "Студент — он бедный, и его, кроме как денег с него не брать, еще и покормить надо!".
Откроется окно Докера, и мы оставим его в покое, ибо у нас там ничего пока нет.
Собственно Доке нам нужен только для того, чтобы поставить "OpenWebUI", дабы не сидеть все время в командной строке терминала.
Но, оставим пока Докера в покое, ибо у нас скоро закачается модель (связь медленная сегодня, я далеко от города сейчас):
Вот теперь все закачалось, поскольку у нас была команда "run" включена, сервис сразу запустился и ждет ввода команды:
Ну вот, собственно говоря — все работает.
Если больше ничего не надо, общайтесь прямо так.
Другие способы установки мы рассмотрим позже, пока минимум — режим терминала.
Вот так мы из него "выходим" (красным), а вот так заново входим (зеленым):
- ollama run llama3.1
- /bye
Установка OpenWebUI
Собственно, если вы будете работать в режиме командной строки, то вам не нужны ни "Docker", ни "OpenWebUI", продолжайте работать просто в терминале. Но работать в окне OpenWebUI намного проще и комфортнее, поэтому продолжим.
Открываем адрес: https://docs.openwebui.com , листаем экран до места описания команд конфигурации:
- я буду запускать "локально"
- хочу NVIDIA GPU конфигурацию, чтобы система работала на видеопамяти и на cuda-ядрах видео-процессора.
Копируем соответствующею команду.
Теперь запустим "Docker" и откроем в нем терминал:
Я "скормил" ему вот эту (nvidia gpu cuda):
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
Ссылка на команду (
)
Ждем пока он качает и устанавливает:
После того как установка закончится, у вас в "Docker"появится строка с установленным приложением. Запуск интерфейса проводится щелчком по ссылке, куда указывает красная стрелочка:
Если локальный интерфейс запускается первый раз, то прежде, чем войти в него, надо в нем зарегистрироваться:
Заполните поля формы, после чего войдите через окно входа в систему.
Эта регистрация является ЛОКАЛЬНОЙ и хранится в локальном репозитории OpenWebUI.
После входы выберите модель (она уже будет в списке моделей), и можете теперь общаться с моделью через свой, ЛОКАЛЬНЫЙ интерфейс. Теперь можно не заботиться об отключении интернета, об оплате за доступ к удаленному сервису, и т.п.
И получаем ответ уже в WEB-интерфейсе, а не в режиме терминала.
Кроме того, через WEB-интеряейс удобнее переключаться между моделями (если их несколько), и настраивать систему через встроенное меню:
Кстати, если вы помните, то в "Olamma" можно устанавливать любую модель из списка, приведенного в разделе "Models", а не только нашу "llama3.1"
Там есть уже и "llama3.2" но пока только малые модели:
Какую модель вы дополнительно установите — ваше личное, американское дело.
График нагрузки при работе "llama1.3"
Цифры на графике:
1. момент выполнения текстовых запросов
2. запуск процесса через "Docker"
3. закрытие "Docker" и "ollama"
Как видно из графика, процесс работает именно в видеопамяти (!), а не в оперативной.
Таким образом можно организовать сервер в локальной сети, подобрав подходящую по конфигурации "железяку", к которому остальные пользователи локальной сети смогут обращаться по его адресу, если "пробросить порты" на сетевую карту, смотрящую в сеть и открыть там нужный порт для всех.
Далее "Установка того же самого через LM Studio" (
)
На главную:
Удачи!
NStor
https://t.me/stable_cascade_rus
https://t.me/srigert