Disclaimer: статья предназначена для тех, кто имеет представление о том, что такое CUDA, но путается при работе с сеткой.
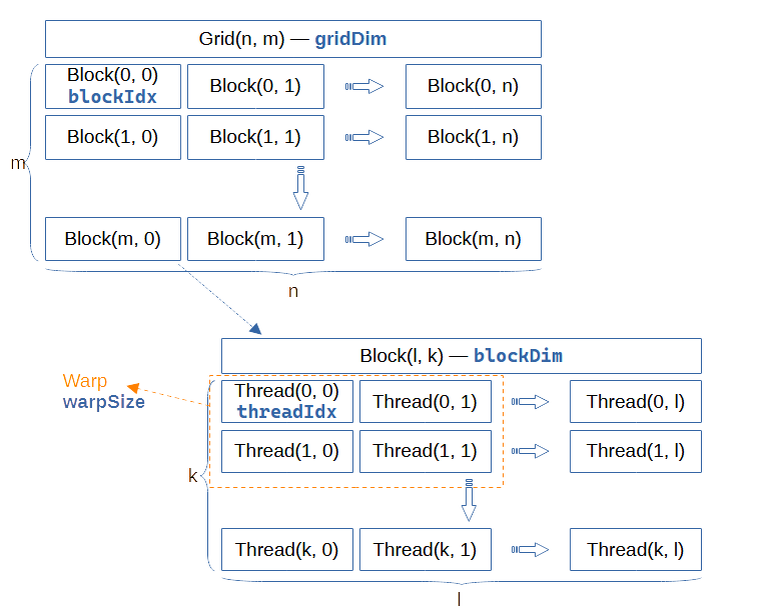
Перед тем, как начать писать особо полезные программы на CUDA, нужно разобраться с иерархией нитей, то есть понять, как нити организованы.
Нить (thread) в CUDA – это последовательная программа, ответственная за решение части какой-то большой задачи. Нитей запускают всегда очень много и первая сложность, с которой сталкиваются программисты, это то, что нити организованы не линейно, а иерархично.
Верхним уровнем иерархии нитей в CUDA является сетка (grid). Сетка может быть одномерной, двумерной или трёхмерной.
Сетка состоит из блоков (block), которые тоже могут быть максимум трёхмерные.
Конфигурацию сетки и блоков мы задаём при вызове вычислительного ядра (kernel), например:
sum<<<1, 32>>(a) # да, Дзен до сих пор не умеет оформлять код
запустит 32 потока в 1 (одном) блоке, то есть
- будет создана сетка из одного блока
- в каждом блоке (а у нас он один) будет за запущено 32 нити
Чтобы убедиться, что это так, я написал маленькую программку (where.cu, запускать через nvcc where.cu && ./a.out), которая просто выводит на экран координаты каждого запущенного потока. И для конфигурации сетки выше она вывела (ожидаемо):
block(0, 0, 0) -> thread(0, 0, 0)
block(0, 0, 0) -> thread(1, 0, 0)
...
block(0, 0, 0) -> thread(31, 0, 0)
Чтобы лучше понять иерархию нитей, можно позапускать where.cu с разными настройками сетки:
- where<<<dim3(2, 2, 2), 32>>>();
- where<<<dim3(2, 2, 2), dim3(2, 2, 2)>>>();
Разобравшись с иерархией потоков в CUDA можно начинать думать о том, как отображаются данные, используемые в задаче на потоки. Но это уже другая история =)