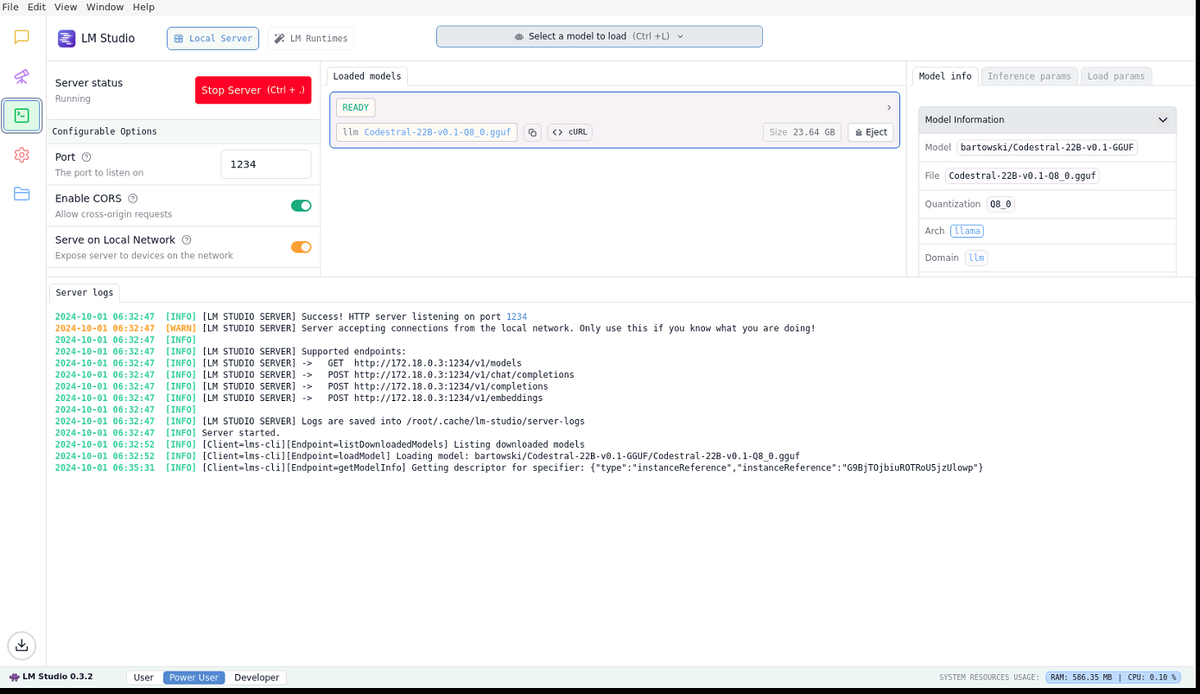
LM Studio — это десктопное приложение для разработки и экспериментирования с моделями больших языковых моделей (LLM) на вашем компьютере. LM Studio использует llama.cpp backend, позволяет запускать gguf-модели на различном железе. Есть исполняемые файлы для различных ОС (windows, mac, linux). В приложении есть OpenAI-API сервер для доступа по локальной сети, поэтому LM Studio позволяет не только проверить возможности различных llm моделей, но так же подходит для разработки ПО.
Ключевым недостатком этого ПО является отсутствие возможности за пуска в headless режиме (старт OpenAI-API сервера без визуального интерфейса), это усложняет использование студии на арендованных облачных серверах, по сути ограничивает сценарии использования только локальным запуской.
Для решения этой проблемы я собрал скрипты для развертывания LM Studio в docker-контейнере в headless-режиме с использованием ОС Ububnu-linux.
Для развертывания будет нужна подготовленная ОС Ubuntu (использовал версию 22.04 и облако с видеокартами NVIDIA):
1. Установлены последние версии драйвера видеокарты
2. Установлен container-toolkit
3. Установлен docker
4. Установлен docker-compose
Набор файлов, необходимый для автоматического развертывания выложил в гит: https://gitlab.com/logliwo/lm-studio-docker-compose
Дополнительно необходимо скачать LM Studio AppImage (использовал версию 0.3.2 для linux) и расположить ее в директории с этими файлами.
Более подробно разберу содержимое файлов:
Dockerfile:
FROM nvidia/cuda:12.6.1-cudnn-devel-ubuntu22.04
COPY ./LM_Studio* /data/lms/
Исходный образ обязательно должен иметь совместимую версию CUDA. Использую образ от NVIDIA, который уже настроен на использование CUDA приложений внутри
COPY ./LM_Studio* /data/lms/
COPY ./keyboard /etc/default/keyboard
COPY ./http-server-config.json /http-server-config.json
COPY ./start_services.sh /start_services.sh
Копирование необходимых для сборки файлов
RUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y keyboard-configuration console-setup tzdata dbus x11-utils x11-xserver-utils libgl1-mesa-glx
Запуск установки предварительных зависимостей
RUN dpkg-reconfigure -f noninteractive keyboard-configuration
Настройка клавиатуры для автоматизации дальнейшей установки
RUN apt-get update && apt-get install -y libfuse2 kmod fuse libglib2.0-0 libnss3 libatk1.0-0 libatk-bridge2.0-0 libcups2 libdrm2 libgtk-3-0 libgbm1 libasound2 xserver-xorg xvfb x11vnc
Установка оставшихся зависимостей
RUN mkdir -p /root/.vnc && x11vnc -storepasswd <password> /root/.vnc/passwd,
Для управления LM Studio используется VNC, пароль для доступа необходимо подставить за место <password>
ENV DISPLAY=:99
Установка переменной окружения для определения виртуального дисплея
RUN chmod ugo+x /data/lms/*.AppImage
RUN /data/lms/*.AppImage --appimage-extract
Распаковка AppImage файла LM Studio
RUN cd /squashfs-root/
RUN chown root:root /squashfs-root/chrome-sandbox
RUN chmod 4755 /squashfs-root/chrome-sandbox
RUN chmod +x /start_services.sh
Выдача необходимых прав доступа к файлам
CMD ["/start_services.sh"]
Команда для старта студии.
keyboard: настройки для виртуальной клавиатуры
http-server-config.json: файл конфигурации локального сервера OpenAI-API
start_services.sh:
rm /tmp/.X99-lock
Снимаем блокировку виртуального монитора (если заблокирован)
Xvfb :99 -screen 0 1920x1080x16 &
Запуск виртуального монитора
/squashfs-root/lm-studio --no-sandbox &
Запуск lm-studio в отдельном процессе
~/.cache/lm-studio/bin/lms server start --cors &
Старт OpenAI-API с включенными CORS заголовками ответов
~/.cache/lm-studio/bin/lms load --gpu max --context-length ${CONTEXT_LENGTH:-4096} ${MODEL_PATH} &
Загрузка llm модели, путь к фалу модели должен быть передан в переменной окружения MODEL_PATH, длина контекста в CONTEXT_LENGTH
cp -f /http-server-config.json /root/.cache/lm-studio/.internal/http-server-config.json
Копирование конфигурации OpenAI-API сервера делается с целью автоматического включения серва по локальной сети (по умолчанию отключен, управление через lms для текущей версии не доступно)
x11vnc -display :99 -forever -rfbauth /root/.vnc/passwd -quiet -listen 0.0.0.0 -xkb
Запуск VNC серера на виртуальном дисплее
docker-compose.yml:
build: .
Образ для запуска контейнера будет собран из Dockerfile
ports:
- "1234:1234"
- "5900:5900"
Порт 1234 прокинут для доступа к OpenAI-API серверу. Порт 5900 для доступа по VNC к интерфейсу управления LM Studio.
volumes:
- /root/.cache/lm-studio/models:/root/.cache/lm-studio/models
Подключение локального хранилища для моделей (что бы модели не удалялись при удалении контейнера)
environment:
- CONTEXT_LENGTH=32768
- MODEL_PATH=bartowski/Codestral-22B-v0.1-GGUF/Codestral-22B-v0.1-Q8_0.gguf
Установка переменных окружения для работы моделей
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
Прокидывает ВСЕ GPU адаптеры внутрь контейнера
command: ["/start_services.sh"]
Каждый раз при старте контейнера будет сполняться эта команда
restart: always
Автоматический перезапуск при ошибках
Запуск контейнера:
docker-compose up --build -d
--build пересоберет контейнер заново, для перезапсука данную опцию использовать не нужо
-d запустит контейнер в отдельном процессе
Итог:
LM Studio запущена в отдельном контейнере (например на удаленном сервере с GPU) без необходимости держать интерфейсное окно активным, но с возможностью доступа к интерфейсу через любой VNC клиент.
Для доступа по сети доступен OpenAI-API сервер, модель автоматически загружена при старте.