
Если вы запускали даже один единственный playbook в своей жизни, то знаете, что ansible очень трепетно относится к находящимся рядом директориям. И норовит самостоятельно, совершенно без вашего ведома схватить и использовать по своему усмотрению положенные туда файлы. Эти грабли старательно разложены разработчиками ansible по всем окрестным кустам и тропинкам в виде hardcoded имен. Чего только стоит простенький файл “nginx.pkg.yml”, случайно положенный в “group_vars/datacenter/”, вместо “group_vars/webserver/” (и commit его, и master merge пока code review в отпуске). Еще веселее дела обстоят с ролями – не вздумайте ни при каких обстоятельствах называть группу или хост main (а также пламенный привет сычам, явистам и прочим сапам).
На самом деле, это поведение достаточно подробно описано в документации. Но – в самых неожиданных ее местах. Поэтому вооружаемся терпением, и читаем, учим наизусть, тренируемся на кошках (нет-нет, не надо на маршрутизаторах cisco пытаться что-то возводить с помощью ansible, максимум – собрать backup конфигурации).
Утерев очередные кровавые слезы, было принято решение разработать такую структуру директорий, которая была бы удобна в командной работе (“Ты зачем в ansible.cfg поставил StrictHostKeyCheck=yes?! У меня мониторинг production упал!”), и в значительной мере минимизировала вероятность ошибок человеческого фактора.
Сформулируем требования
1. Структура должна соответствовать более ли менее устоявшемуся “стандарту” (религии разработчиков ansible), чтобы любой вновь туда попавший не смотрел на это как баран на новые ворота.
2. Структура должна быть командно-устойчивой, чтобы намеренный или случайный commit не приводил к неработоспособности соседних сущностей (playbook, roles, tasks и т.п.).
3. Структура должна быть хорошо масштабируемой для беспрепятственного добавления новых сущностей.
4. Структура должна соответствовать концепции DRY и предусматривать повторное использование кода.
(В этом месте апологеты ansible начинают кричать, что роль — это не процедура. И процедура, и утверждение, и условное ветвление, и объект, и замыкание и еще черт-знает-что, которое встречается в Pascal, LISP, Prolog, dBase и всех современных языках программирования. Поскольку другой конструкции нам не дали. И, по мере появления статей, я буду вам эти факты последовательно доказывать. Надеюсь, хотя бы с Тьюринг-полнотой спорить никто не станет.)
5. Структура должна поддерживать возможность регрессионного тестирования.
6. Структура должна удобно размещаться в репозитории.
Директории и соглашения
В корне ansible у нас по традиции будут находиться:
- inventory
- playbooks
- roles
- cmdb
Сразу вводим соглашения по размещению файлов и директорий:
1. Используемая сущность должна иметь расширение и необязательные суффиксы через точку.
То есть, выполнимый playbook должен иметь расширение “apt-upgrade.yml”. И, в случае наличия ограничений “apt-upgrade.debian.yml” или расширения возможностей “lxc_pg.distributed.yml” - суффиксы (это пример из моей статьи про отладочный полигон).
2. Если сущность состоит из более чем одного файла, она помещается в одноименную директорию на уровень ниже.
Проще говоря: если playbook состоит из одного файла “apt-upgrade.yml”, то он так и будет лежать в “playbooks/”. Но если ему для работы нужно несколько файлов, например, еще и специфические публичные ключи, то мы кладем его в “ansinit/ansinit.yml”, а рядом с ним лежат “ansinit/my_key.pub” и другие.
Следствие из 2: Если сущность пользуется несколькими группами файлов (много ключей “*.pub”), то они могут складываться еще на уровень ниже – “ansinit/pub_keys/*.pub”.
Оба эти соглашения применимы ко всем директориям. Основное удобство заключается в том, что человек видит директорию, и одноименный (но с расширением “.yml”) файл в ней – ему не надо задумываться, что здесь запускать (playbook) или что брать (inventory). Несколько лежащих рядом файлов “*.yml” не вынуждают последовательно открывать каждый и смотреть – это playbook, play (а как вы его от первого отличите, если внутри комментария нет?) или просто набор task.
Для “playbooks” все очевидно. Для “inventory” – возможность делать составные и вкладываемые списки. А вот роли это спасает от непреднамеренного запуска в неопределенное окружение – файл main.yml никто запускать не будет (мы же договорились выше, никогда не именовать сущности “main”?).
3. Внутри сущности только относительные пути на контролирующей машине, не выше дерева репозитория или домашней директории пользователя.
Это соглашение в большей степени касается “playbooks”, но, на самом деле также применимо ко всем остальным сущностям. Кажущееся исключение: мы хотим положить свой ssh ключ на контролируемую машину – и здесь мы обязаны использовать неявный относительный путь “~/.ssh/*.pub”.
Опасность абсолютных путей в том, что вы не знаете, куда именно очередной тестировщик или админ выгрузят репозиторий.
4. Playbook может создавать другие сущности на контролирующей машине только уровнем ниже себя с обязательной защитой от commit в репозиторий или в системной временной директории. Role может создавать другие сущности на контролирующей машине только в системной временной директории.
В случае возникновения run condition или non thread-safe процессов, даже при случайном commit невозможно сломать репозиторий Ansible. Все создаваемые ниже артефакты прикрываются “.gitignore” (или аналогами).
Это соглашение на первых порах вызывает наибольшее количество споров со стороны разработчиков playbook, поэтому дальше разберем конкретные кейсы.
“Мне нужно настроить на localhost сервис и записать его конфиг в ‘/etc’, а сущность может писать только ниже”. Но в данном случае, localhost будет как контролирующей машиной, так и целевой. На целевой машине вам никто не запрещает выполнять требуемые действия.
“Мой playbook создает динамический inventory (список пакетов, перечень сервисов и т.п.), которым потом должны пользоваться другие playbook”. Тут сразу несколько вариантов действий.
- Созданная ниже сущность перекладывается ручками в нужное место. Так добавляется еще одна точка верификации. Если бы мы разрешили писать сразу выше (в тот же inventory), то, в junior-made сценарии playbook удалит старый список, попробует собрать новый, но не сможет подключиться к облаку. И хорошо, если не отправит после этого автоматический commit. Даже в middle-made сценарии, playbook сначала попробует создать временный файл, чтобы его потом переименовать в окончательный. И не сможет установить на него права на чтения для нужной группы. Поэтому действие по перекладыванию должно верифицироваться. Тем более, если от этого списка зависят сущности, которые разрабатывает другой участник команды.
- Сущность создается в директории ниже, в которую подключен и выгружен репозиторий. Потребители получают сущность в свое распоряжение из этого репозитория. Тут чуть больше возможностей. Верификация может производиться до commit. А даже если commit автоматический, у потребителя всегда есть возможность откатиться на предыдущую стабильную версию. В самом репозитории можно сделать несколько ветвей и использовать merge (release), для утвержденных сущностей.
- Потребитель запускается на той же контролирующей машине после создателя сущности и смотрит ниже него – берет свежесозданную сущность. Как частный случай, если сущность создавалась во временной директории, потребителю можно передать путь как параметр.
“Результат/отчет playbook нужно выложить на веб-сайт/хранилище”. Тот же “/var/www/html” следует трактовать: localhost как целевая машина – фактически, первый пример.
Предлагайте в комментариях свои кейсы – постараемся их разобрать.
В общем случае, когда мы говорим о выше-ниже, речь идет о директории, в которую выгружен репозиторий Ansible.
5. Если у сущности есть зависимые, их необходимо протестировать перед каждым слиянием изменений сущности в master.
В особенности, это касается ролей. Даже небольшое изменение может привести к краху production, если роль содержит очевидную ошибку. При этом, никто не мешает пользоваться (с осторожностью) обновленной сущностью, непосредственно из ее ветки. По крайней мере, те сущности, от которых зависит она – точно остались неизменными.
Следствие из 5: необходимо договариваться об учете зависимости. Хорошим тоном будет в директории сущности сделать файл “who_depends_on.md”, в который другие разработчики будут вносить пути к своим творениям.
Обратное следствие из 5: если ваша сущность жестко зависит от определенной версии другой сущности – скопируйте ее себе ниже. (Вы же помните про относительные пути – сущности должно быть все равно где жить). На первый взгляд это противоречит DRY, но такая ситуация является исключительной, на время разработки или устранения коллизии. Конечно, в production это надо избегать. Если бы мы жили в subversion, то можно было бы сделать линк на фиксированную версию в виде директории ниже (наверное, в git можно привязаться к конкретному commit – не пробовал).
6. Запуск playbook всегда осуществляется только в его директории.
Это гарантирует, что будут использованы корректный “ansible.cfg” (при необходимости, располагается рядом с ним) и автоматический поиск включаемых файлов.
7. Сущности, предназначенные для совместного использования, должны вначале сопровождаться комментариями, содержащими описание всех входящих параметров (переменных), и возвращаемых результатов.
Сущность обязана проводить проверку получаемых параметров на наличие и валидность. То есть, если сущность использует несколько переменных, которые связаны последовательной логикой, прежде чем использовать одну из них, следует убедиться, что переданы все остальные. А в случае их недостатка – отказаться от каких-либо действий.
Итого
Дерево для такой структуры будет выглядеть примерно так:
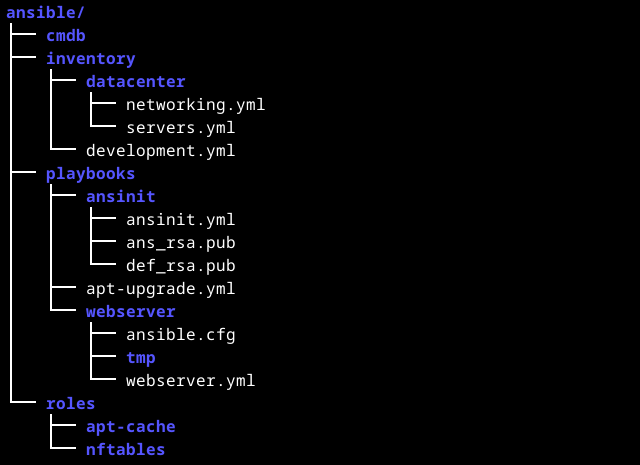
Всего
Чтобы применять DRY (don’t repeat yourself) и повторное использование кода, playbook может подключать общие роли из директории “roles” выше. Или собственные роли, лежащие в своей директории (“playbooks/myplaybook/roles”). Когда роль только разрабатывается, она должна находиться в своей директории (“playbooks/devrolebook/roles/newrole” даже в своей feature-ветке), и, только после отладки перемещаться выше в общие “roles”.
Если добавить немного магии, мы можем использовать непосредственно набор task из роли, без подтягивания всего ее окружения. Именно так реализуется простая процедура. При этом параметры вызова передаются как набор фактов соответствующего хоста. Также через факты можно возвращать результат (register или set_fact), и процедура становится функцией.
Регрессионное тестирование в минимальном объеме выполняется с применением полигона (например, Ansible полигон для отладки на LXC). Сценарий проверки будет следующий:
- раскатать инфраструктуру на полигон из ветки master (предыдущее устойчивое состояние);
- переключиться на feature-ветку с обновлениями и повторно раскатать структуру на полигон.
Условно-успешным будет состояние, при котором произойдут изменения (“changed”) только в части, касающейся обновленной сущности.
Более полноценное тестирование должно включать в себя специальные функциональные тесты, которые подтверждают работоспособность устанавливаемых сервисов или применение соответствующей системы мониторинга. Для автоматизации удобно применять скрипт, запускающий на полигоне сразу несколько playbook (да-да, “bashsible”). Или специальный playbook, который с помощью include включает в себя все инфраструктурные playbook и, в догонку, функционально-тестовые.
Получилось
Структура директорий со всеми сущностями размещается в репозитории. Следование соглашениям обеспечивает его целостность и консистентность, не ограничивая масштаб. Разные команды могут одновременно работать над своими сущностями, включая разделение ролей на разработчиков и потребителей. Для каждой новой сущности создается отдельная feature-ветка, и процессы разработки не влияют на процессы эксплуатации.
Возможна организация отдельного процесса «сушки» (DRY), при котором на регулярных review выделяются участки повторяющегося кода, назначается owner и обеспечивается переиспользование.
Процесс тестирования может автоматизироваться и итерационно увеличивать покрытие.
В каждый момент времени существует stable состояние, которое применяется на production.
Вместо заключения
Если в предыдущих заголовках вы узнали известный анекдот про официанта, и у вас ситуация “значит, не получилось” - не отчаивайтесь. Инфраструктура большая (а иначе зачем вам Ansible), рано или поздно вы найдете своего “клиента”.
Осталось понять, причем здесь CMDB (configuration management database)?