Прошлая часть: Виды тестирования ПО
Всем привет. Давненько я не добавлял новых статей конечно, но и читают статьи не сказал бы что часто... Ладно, отставить уныние - к теме.
Обсудим тему клиент-серверной архитектуры. В данной теме необходимо разбираться, чтобы верхнеуровнево понимать само устройство программ и их частей, а также способы взаимодействия этих частей между собой. С практической точки зрения это позволит нам лучше изобретать тест-кейсы и локализовывать баги.
Клиент-серверную архитектуру традиционно представляют из трёх основных частей:
- Клиент
- Сервер
- База данных
Самое главное в объяснении этой темы, с чего мы и начнем – перестаньте ассоциировать слово «клиент» с человеком, который пользуется программным обеспечением. В контексте данной темы слово «клиент» означает совершенно другое.
А для того, чтобы у вас сложилась правильная картина про архитектуру в целом – следует разобрать каждый элемент в отдельности.
База данных.
Начнем с базы данных или сокращенно БД. В этих наших «интернетах» определение базы данных звучит как «совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных». Как будто специально составляют определения таким образом, чтобы сложнее было его осознать.
Простым языком база данных – это хранилище данных, которое устроено определенным образом, и сами данные, работа с которыми выполняется по определенным правилам.
Для того, чтобы у вас появилась ассоциация с чем-то знакомым – представьте себе excel документ, в котором мы будем вести простенькую «базу данных» своих друзей. В документе будет 3 листа:
- Фамилия, имя и отчество друзей на первом листе, с названием «ФИО»;
- Фамилия и точный адрес места жительства и дата, с которой место жительства актуально, ваших друзей на втором листе, с названием «Адреса»;
- Фамилия, телефон и e-mail и дата, с которой контакты актуальны, на третьем листе, с названием «Контакты»
Таким нехитрым образом мы создали аналог реляционной базы данных. В качестве базы данных у нас выступает excel документ в целом. В качестве «таблиц» базы данных у нас выступают листы: «ФИО», «Адреса» и «Контакты». А слово «реляционная» (от англ. relation - связь) означает, что между «таблицами» у нас есть отношения или зависимости, как в данном примере на всех листах есть «Фамилия», которая в теории может помочь объединить данные из одного листа с данными другого.
Для понимания дальнейшего объяснения клиент-серверного взаимодействия необходимо усвоить еще немного знаний про БД. На примере с excel документом мы рассмотрели наш «аналог» реляционной БД. Предлагаю убрать из этого примера excel – что у нас останется? У нас останутся данные, и они все еще будут структурированные и вы составляете их по определенным правилам. Т.е. технически наша «база данных» никуда не делась. В роли чего тогда у нас выступал excel? Excel в нашем примере выступал в роли системы управления базами данных.
Система управления базами данных– это набор инструментов (программное обеспечение), которые позволяют создавать базы данных и удобно манипулировать данными (хранить, добавлять, изменять, удалять по определенным правилам).
Разбираемся дальше. Предположим, что у вас возникла потребность хранить не только данные о своих друзьях, но и данные о калорийности вашего лично питания. Как бы вы поступили? Хранили бы вы эти данные в том же excel документе, сваливая всё в одну кучу, или же создали бы новый документ? Я лично создал бы новый документ, т.к. данные логически никак не связаны. Т.е. в результате у меня появился бы новый excel документ структурированный исключительно под расчет калорий. В разрезе баз данных подход с таким разделением данных называется «Схема базы данных».
Схема базы данных – это один из основных объектов базы данных, который агрегирует под собой таблицы, которые сгруппированы на основании какого-либо признака.
Сервер.
Также смотрим определение сервера в интернете и получаем следующее. Сервер (англ. server, от лат. serve — служить, обслуживать) - выделенный или специализированный компьютер для выполнения сервисного программного обеспечения.
Попытаемся и это определение упростить, не вдаваясь в подробности облачных технологий и контейнеризации. Сервер – это «железка» с определенными характеристиками (считайте, что это «отдельный компьютер»), на который устанавливается определенное ПО, которое выполняет конкретные функции.
Самый важный момент в упрощенном определении — это часть «…на который устанавливается определенное ПО, которое выполняет конкретные функции». Из него мы понимаем, что:
- Наши приложения скорее всего будет устанавливаться на какие-то сервера.
- Наибольшая часть полезных действий конкретного ПО будет выполняться именно на сервере, т.е. именно на нем скорее всего будет исполняться основная бизнес-логика нашего приложения.
Клиент.
На всякий случай я еще раз уточню то, что упомянул в начале статьи. Перестаньте ассоциировать слово «клиент» с человеком, который пользуется программным обеспечением. «Клиент» это не вы и не ваш коллега. «Клиент» - это не Иван Петрович, который будет являться вашим начальником.
Клиент, по определению из интернета – это аппаратный или программный компонент вычислительной системы, посылающий запросы серверу.
Определение «клиента» упрощенным языком – это ПО, которое обращается к серверу, чтобы заставить сервер выполнить какую-либо работу.
Из этого определения нам важно понять следующее:
- В качестве клиента в клиент-серверной архитектуре выступает какое-то ПО.
- Вероятнее всего какое-то ПО, которое обращается к вашему серверу, знает «правила», по которым необходимо взаимодействовать с ПО на вашем сервере.
- Вероятнее всего, если какое-то ПО «клиент» обращается к вашему серверу, то оно хочет, чтобы ваш сервер выполнил какую-то полезную работу, т.е. бизнес-логику.
- Так как в качестве «клиента» выступает программное обеспечение, то не исключено, что в качестве «клиента» может выступать и сервер, с установленным на ним программным обеспечением, которое знает правила взаимодействия с вашим ПО.
В web-приложениях самым популярным примером клиента будет браузер (Google Chrome, Yandex browser и т.д.). Именно через браузер вы инициируете отправку данных на сервер или получение данных с сервера. Но для новичков в этой теме из-за такого примера останется непонятным 4 пункт выводов, где «в качестве клиента может выступать и другой сервер», поэтому предлагаю вам провести следующий мысленный эксперимент.
Сервер является «железкой», но и ваш компьютер является «железкой». На сервер, выступающий в роли клиента будет установлено какое-то ПО, но и на ваш компьютер установлено какое-то ПО (браузер). Это программное обеспечение, выступающее в роли «клиента», знает правила взаимодействия с целевым сервером, но и ваш браузер знает правила взаимодействия с целевым сервером. Получается, что теоретически ваш компьютер выступает в роли сервера (железки), на который установлено ПО (браузер), которое знает правила взаимодействия с целевым сервером, который должен выполнить какую-то полезную работу.
Если данный эксперимент вам не помог в понимании – далее в главе будет визуализация, которая я надеюсь сможет пролить свет на ситуацию, когда сервер выступает в качестве клиента.
Клиент-серверное взаимодействие.
Составим теперь общую картину взаимодействия. Для начала посмотрим на картинку этого взаимодействия для простоты понимания:

В самой простой ситуации взаимодействие будет выглядеть следующим образом:
- Клиент отправляет запрос на сервер.
- Сервер получает запрос.
- Сервер обрабатывает запрос в соответствии с бизнес-логикой.
- В процессе обработки запроса сервер запрашивает необходимые для исполнения бизнес-логики данные в БД.
В результате своей работы сервер, скорее всего, выполнит какие-то из следующих действий:
- Вернет на сторону клиента ответ с результатом своей работы.
- Обновит необходимые данные в БД.
А клиент в свою очередь преобразует ответ сервера в приемлемый для пользователя вид.
Какие из действий будут выполнены сервером определяется по большей части типом взаимодействия клиента и сервера (синхронным или асинхронным) и бизнес-логикой, которая будет выполнена при работе сервера (быть может вы, как пользователь, ничего не хотите обновлять в БД, а хотите просто получить какую-то информацию).
Теперь давайте немного усложним схему, приведя ее к чуть более реальной:
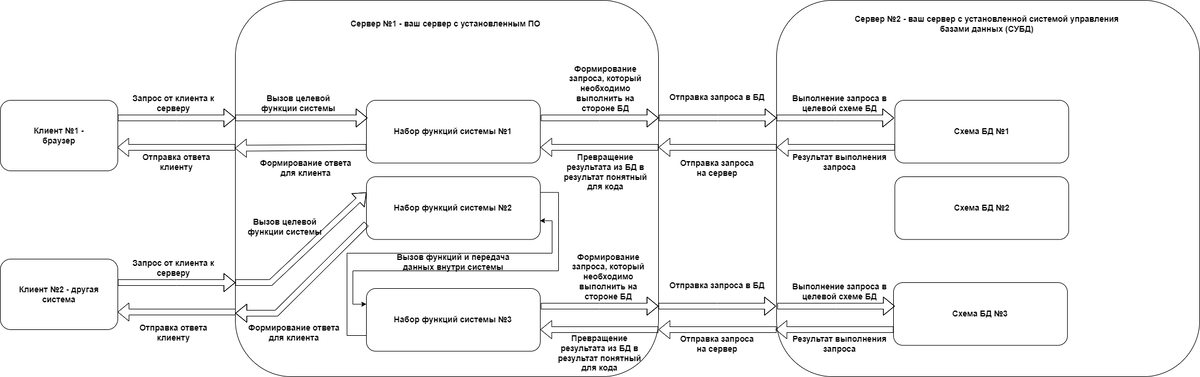
Что мы из нее видим:
- В качестве клиента может выступать не только лишь браузер.
- Между самим запросом к серверу и вызовом целевой функции системы есть какая-то «прослойка», которая определяет какую именно функцию системы необходимо вызвать.
- Функции системы могут вызывать другие функции внутри системы.
- Перед отправкой запроса в БД на стороне сервера происходит формирование этого запроса.
- После получения запроса от сервера на стороне БД он может выполняться в разных схемах.
Теперь перейдем к основной сути этой главы и ответим на вопрос «Зачем это нам знать, как тестировщикам?».
Это дает нам знание о проблемных местах системы. Вам следует понимать, что каждое место, где с запросом происходят какие-либо преобразования – это потенциально проблемное место. На усложненной схеме потенциально проблемными местами являются те места, где начинается или оканчивается стрелка. Рассмотрим, что теоретически может пойти не так:
- Клиент может отправить запрос, который уйдет по некорректному адресу (например, ошибка в URL или IP адресе сервера).
- Клиент может отправить запрос, который будет отправлен по нужному адресу, но сервер будет недоступен по какой-либо причине (например, установка обновления).
- Клиент может отправить запрос, который будет отправлен по нужному адресу, но сервер запрос не поймет (например, данные отправлены в некорректном формате).
- При получении запроса от клиента сервер может вызвать неправильную функцию системы (например, разработчик ошибся с маппингом обработки запроса в зависимости от версии API).
- При получении запроса от клиента сервер может понять полученный запрос, но «отбраковать» его как не валидный на основании каких-то параметров запроса и прекратить обработку бизнес-логики (например, сервер ждет в теле запроса обязательный параметр X, но клиент отправил запрос без этого параметра).
- При обработке запроса одной функцией системы может быть вызвана другая функция системы, которая сочтет полученные от предыдущей функции данные не валидными (например, для функции системы №2 параметр Х не является обязательным, а для вызываемой при обработке функции №3 параметр Х обязателен).
- При формировании запроса к БД сервер может не понять куда запрос отправлять или отправит запрос в неправильную БД (например, не заданы конфигурационные настройки или в конфигурационных настройках содержится ошибка).
- При отправке запроса к БД запрос может не дойти до БД (например, недоступность сервера БД или устаревшие данные учетной записи, под которой производится работа с БД).
- При выполнении запроса на стороне БД он может не исполниться / исполниться некорректно (например, ошибка в самом запросе или запрос не был актуализирован под новую структуру таблицы после ее изменения).
- В результате исполнения запроса на стороне БД может быть сформирован ответ, который может некорректно обработан со стороны сервера (например, сервер может ожидать что запрос вернет только одну запись, а запрос возвращает список записей).
- В результате обработки результатов запроса на стороне сервера может произойти ошибка, которая прервет дальнейшее исполнение бизнес-логики (например, функция системы ожидала что параметр X в ответе от БД никогда не будет равен Z, а он оказался равен этому Z)
- В результате исполнения бизнес-логики на основании ответа от БД одна функция системы может обратиться к другой функции системы, которая ожидает какой-то обязательный параметр, который не был передан (аналог п.6, только в обратном порядке)
- Процесс формирования ответа клиенту может быть прерван, несмотря на исполнение бизнес-логики (например, нехватка оперативной памяти для формирования очень большого ответа).
- При получении ответа от сервера клиент может не справиться с обработкой этого ответа и соответственно не отобразить данные / отобразить некорректные данные (аналог п.3, только в обратном порядке).
- Ну и вишенка на торте – вся цепочка взаимодействия может отработать без ошибок, но ошибка будет в самой бизнес-логике (например, ваше приложение калькулятора на сервере успешно складывает 2+2, но в результате сложения возвращает ответ 5).
Важно отметить, что это не «реальная» схема, а «концептуальная» схема клиент-серверной архитектуры, просто немного усложненная. В реальности она будет масштабирована – множество клиентов, множество серверов, которые имеют множество функций взаимосвязанных друг с другом, а также много серверов баз данных. Теперь умножаем это на количество тестовых стендов… Хотя, о чем это я – хватит вас пугать.
Основную мысль, я думаю, вы уловили – «Что-то, где-то может пойти не так». Теперь давайте разберемся с тем, что именно нам эти знания дают, на простом примере. Предположим, что вы через браузер (клиент) отправляете запрос на сервер и получаете ошибку. Что будет делать начинающий инженер-тестировщик в такой ситуации? Правильно – он начнет носиться с этой ошибкой, как с писаной торбой и дергать всех окружающих.
Это поведение в корне неправильно. Хороший инженер должен в первую очередь подумать! Необходимо поразмыслить на тему «А что собственно произошло?» и задать себе ряд вопросов:
- Является ли полученная ошибка ошибкой-бизнес логики или ошибкой взаимодействия компонентов системы?
- Действительно ли проверяемая задача (новый функционал) присутствует в сборке, которая установлена на тестовый стенд?
- Действительно ли я отправил запрос на нужный сервер? (Аналог «Точно ли я работаю сейчас на нужном тестовом стенде?»)
- Действительно ли сервер сейчас находится в работоспособном состоянии?
- Действительно ли клиент должен уметь отправлять такие данные, в результате которых произошла ошибка?
- Действительно ли отправленные данные являются корректными?
- Действительно ли проблема повторяется при повторном выполнении аналогичных действий?
Сейчас была проведена попытка локализация проблемы с точки зрения потенциальной проблемы на стороне клиента. Если проблема на клиенте пока что отсутствует – это всё еще не повод паниковать, бить в колокола и отвлекать разработчиков от просмотров увлекательных тик-ток видео. Это повод вспомнить про слово «логи». Как говорится – «было бы что вспоминать» …
Лог – это текстовый файл, в который автоматически записывается информация о работе программы. Подчеркиваю – информация о работе программы, а не только лишь информация об ошибках. Детально тему логов мы разберем позднее.
Вернемся к попытке локализации проблемы. Вам необходимо узнать «где» и «как» просмотреть логи вашего ПО. После этого проанализировать логи на предмет наличия ошибки в период времени, когда вы не получали ожидаемого результата. Если хватит способностей – понять из лог файла в чем же была проблема.
Теперь, когда вы имеете на руках определенный перечень фактов вы можете себе точно сказать, что:
- Работали на правильном стенде и на правильном / не правильном сервере.
- Сервер был в работоспособном/ неработоспособном состоянии.
- Отправляли корректные/не корректные данные, которые клиент должен уметь/не уметь отправлять на сервер.
- Присутствуют/отсутствуют ошибки в логах.
На основании этих данных вы можете либо задать осмысленный вопрос разработчику, либо оформляете баг-репорт. Самое главное в этой ситуации, что вы сэкономили коллегам N часов времени работы, ведь вы разбирались проблеме самостоятельно и никого не привлекали к решению проблемы, а всё лишь только потому, что верхнеуровнево разобрались в концепции взаимодействия клиента, сервера и базы данных.
Какие еще плюсы вам может дать понимание клиент-серверного взаимодействия? Например, существенно сократить время проведения проверок. Предположим, что вам необходимо проверить функцию системы №2, которая модифицирует данные, которые порождает функция системы №1 в БД. При этом вы точно знаете (из архитектуры вашего приложения), что функции независимы между собой, но использование функции №1 требует слишком много времени для создания необходимых тестовых данных.
Что вы можете сделать в данной ситуации? Правильно, вы можете подготавливать тестовые данные изменяя данные напрямую в базе данных, минуя использование функции №1, тем самым ускоряя тестирование функции №2. Но это более прикладной пример к какой-то конкретной системе и её конкретной архитектуре, а автор категорически не рекомендует заниматься такими манипуляциями с данными на начальных этапах работы.
Ну и последним, но не по значению, плюсом понимания клиент-серверного взаимодействия я бы отметил следующее. По мере понимания клиент-серверного взаимодействия вы станете лучше понимать взаимодействие частей системы между собой, начнете чаще замечать аналогичные между собой задачи и проще подбирать необходимые инструменты и подходы для тестирования той или иной задачи. Даже если какое-то из взаимодействий будет для вас новым, вы будете понимать, что суть от этого все равно не меняется – какой-то клиент отправит вашему серверу данные, сервер должен будет их обработать, записать в БД и что-то ответить клиенту.
Следующая часть: Форматы сообщений часть 1. JSON и типы данных.
Поддержать или поблагодарить можете:
Лайком;
Комментарием;
Подпиской на канал;