Введение.
В этой статье давайте рассмотрим три ключевых типа физических соединений, которые PostgreSQL использует при выполнении логических внешних и внутренних соединений, использующих оператор JOIN:
- merge join,
- hash join,
- и nested loop.
Почему я начал с упоминания про деление на физические и логические соединения? Это разные уровни. Когда вы пишите SQL-запросы с применением LEFT OUTER JOIN или RIGHT JOIN, это логический уровень соединений. Как правило, использующийся для декартовых произведений, в которых остаются строки, удовлетворяющие условию самого соединения. То, как исполняются “под капотом” подобные запросы в РСУБД - это уже физический уровень, который зависит от ряда факторов, как:
- размеры таблиц, участвующих при операции соединения.
- размер памяти, выделенный в “work_mem” под операции сортировок и в “hash_mem_multiplier” под операций с хешированием.
- наличие индексов.
- применяемые операции сравнения или равенства при соединении.
В зависимости от данных условий, планировщик PostgreSQL может выбрать тот или иной метод (алгоритм), который реализует обработку логических соединений.
Описание каждого типа соединения.
Merge join - это метод соединения слиянием, используемый когда обе таблицы достаточно большие и уже есть отсортированные данные по полям (JOIN-ключам участвующим в соединении), например при помощи индексов. Если таблицы не отсортированы заранее, то PostgreSQL выполнит сортировку перед выполнением соединения, что может увеличить затраты. Ключевое отличие от hash join в том, что merge join требует обязательной сортировки данных по JOIN-ключам, когда hash join не требует сортировки вообще. Он просто построит хеш-таблицу и будет использовать ее для поиска совпадений. Так же, про merge join стоит добавить, что он особенно полезен для диапазонных соединений (например, >=, <=), поскольку после сортировки он может эффективно обрабатывать такие условия.
Hash join - это метод соединения при помощи хэширования, который используется в тех случаях, когда данные, по которым требуется выполнить соединение, не отсортированы. Алгоритм работает так, что сначала выбирается одна из таблиц, обычно меньшая по памяти, и для каждой ее строки создается запись в хеш-таблице. Затем, другая таблица (большая) сканируется, и каждая строка проверяется на сравнение с хеш-таблицей. Если найдено совпадение по нужным значениям, то строки объединяются. Так же, более явно подчеркну деталь, что PostgreSQL выбирает меньшую таблицу для создания хеш-таблицы, чтобы минимизировать использование памяти. Данная хеш-таблица затем используется для быстрого поиска соответствий во второй, более крупной таблицей. Финализируя можно сказать, что hash join чаще всего используется для больших таблиц, когда отсутствуют индексы или когда данные не отсортированы, а условие соединения предполагает точное совпадение (=). Диапазонные соединения, как правило, менее эффективны с hash join.
Nested Loop - это метод соединения, использующий вложенные циклы, который для каждого значения одной таблицы, ищет соответствующее значение из другой таблицы. Если детальнее, то берется первое значение из первой таблицы и сравнивается последовательно со всеми значениями из второй таблицы, если находится соответствие, то запись включается в финальный набор данных. Когда значение из первой таблицы сравнилось со всеми значениями из второй таблицы, далее берется второе значение из первой маленькой таблицы и снова происходит сравнение со всеми значениями из второй таблицы. Собственно почему и используется название “nested loop” (вложеннеого цикла), т.к. весь процесс происходит до тех пор, пока каждое значение из первой таблицы не будет сравнено с каждым значением из второй таблицы.
Читая иные статьи в интернете, я видел информацию, что “якобы” nested loop всегда строго используется при таблицах, когда одна - маленькая, а другая - большая. Это совсем необязательно, и я сейчас приведу SQL-код для примера с выводом плана запроса через “EXPLAIN ANALYZE”:
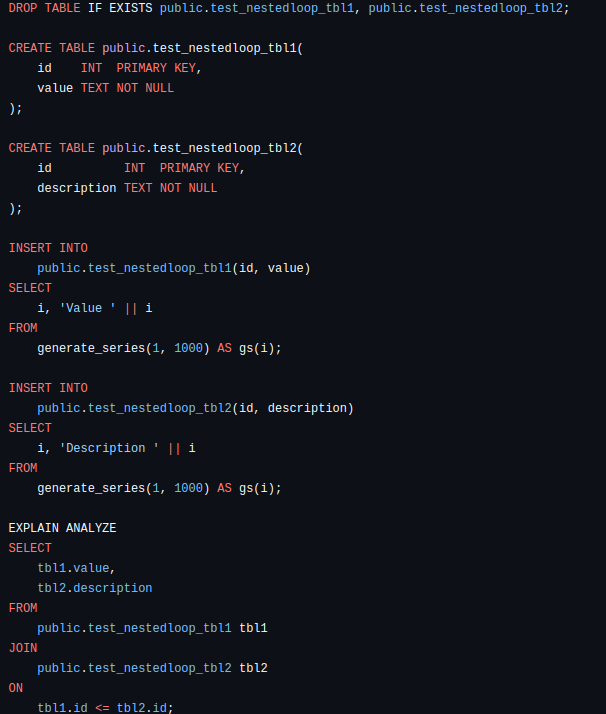
Если выполнить данный запрос, то при выводе плана вы увидите именно nested loop, хотя размер у 2-ух таблиц - одинаковый:
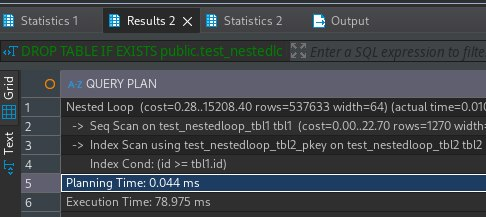
Скорее стоит отметить иную деталь, что nested loop обычно более эффективен, когда одна таблица меньше другой. Скорее такая формулировка более корректна. Это связано с тем, что внешний цикл проходит по меньшей таблице, а внутренний - по большей, что делает его менее ресурсоемким.
Остальные SQL-примеры под merge & hash joins
Для демонстрации merge/hash joins, нам с вами потребуется подготовить пару таблиц со вставкой данных по случайным значениям. Выполните следующий SQL-код:
После создания таблиц и вставки данных в них, проверьте что данные появились:
SELECT * FROM public.test_join_tbl1 LIMIT 10 OFFSET 0;
SELECT * FROM public.test_join_tbl2 LIMIT 10 OFFSET 0;
Проверьте вывод:
Теперь давайте исполним запрос, который выведет нам hash join:
Важное! Стоит упомянуть, что если вы тестируете этот SQL-код на PostgreSQL с достаточно увеличенным значением work_mem (к примеру 128-256 Мб), или если сервис РСУБД "простаивает", т.е. его никто активно не использует в данный момент, то планировщик может выбрать и merge join, потому что ему хватит свободной памяти для того, чтобы предварительно отсортировать данные для merge join операции. В таком случае, понизьте значение work_mem до минимального:
SET work_mem = '64kB';
и можете увеличить кол-во генерируемых данных через generates_series(). Потом повторите SQL-запрос с JOIN. Почему так? Здесь нельзя однозначно дать точный ответ, т.к. это зависит от вычислительных харакетристик вашей среды, где будет проходить тестирование, так и от настроек самого PostgreSQL сервиса (тот же упомянутый work_mem), т.к. планировщик будет определить наилучший алгоритм для исполнения запроса - в текущий момент времени, учитывая количество свободных ресурсов и количество данных используемых в запросе. Если же все ресурсы - свободны и нет параллельной нагрузки, то может выбраться merge join алгоритм. При реальном "боевом" использовании, РСУБД сервис нагружается параллельными запросами из-за чего становится более явным преимущество использования индексов для примера с merge/hash join.
Вернемся к выводу плана:
Даже если мы добавим сортировку в SQL-код:
ORDER BY tbl1.id, tbl2.id;
То hash join останется в выводе:
Что нужно для того, чтобы получился merge join?
Для этого нужно добавить индексы:
CREATE INDEX idx_t1_id ON test_join_tbl1(id);
CREATE INDEX idx_t2_id ON test_join_tbl2(id);
И повторить запрос с ORDER BY частью:
В итоге получится merge join при выводе:
Вот, мы с вами и добились вывода всех 3-ех типов физических соединений: merge join, hash join и nested loop. Стоит упомнить еще, что вы можете отключить типы соединений используя следующие команды:
SET enable_hashjoin = off;
SET enable_mergejoin = off;
SET enable_nestloop = off;
Но на самом деле, вы не сможете полностью отключить использование, к примеру, nested loop для соединений :) В некоторых случаях, nested loop может быть единственным доступным методом соединения, особенно когда условие соединения не предполагает точное совпадение. Например использование операторов сравнения <, <=, >, >=
Некоторые детали про hash join
Сначала про сам алгоритм...
Стоит упомянуть, что hash join, который реализован в PostgreSQL является не совсем классическим, когда используются build & probe фазы (компановка и проба). PostgreSQL использует гибридный hash join, о чем пишут сами разработчики PostgreSQL: https://github.com/postgres/postgres/blob/master/src/backend/executor/nodeHashjoin.c
This is based on the "hybrid hash join" algorithm described shortly in the https://en.wikipedia.org/wiki/Hash_join#Hybrid_hash_join and in detail in the referenced paper: "An Adaptive Hash Join Algorithm for Multiuser Environments" Hansjörg Zeller; Jim Gray (1990). Proceedings of the 16th VLDB conference. Brisbane: 186–197.
Если вкратце, то это комбинация классического алгоритма hash join и grace hash join.
Влияние work_mem
При выводе плана с hash join можно увидеть такую строчку в планировщике:
“Buckets: 1048576 Batches: 1 Memory Usage: 58583kB”
Buckets - это количество ячеек в хеш-таблице, которые PostgreSQL использует для распределения данных из одной из таблиц.
Batches - это количество партий в которых PostgreSQL разделяет данные, если хеш-таблица слишком велика для размещения в памяти.
Часть из вывода планировщика указывает на то, что все данные хеш-таблицы поместились в ОЗУ целиком и не было необходимости разбивать данные на несколько партий. Так же напомню, что хэш-таблица строится на базе одной таблицы при операции соединения, которая более меньшая по объемам памяти. Поэтому данный вывод показывает статистику именно относительно меньшей таблицы.
Но что будет, если мы установим более меньшее значение work_mem?
SET work_mem = '64kB';
SHOW work_mem;
И повторим запрос без ORDER BY части, чтобы увидеть вывод hash join:
Вывод будет следующим:
Сразу видно, что количество buckets и batches стали иным. Так что, видно линейное влияние work_mem параметра. Здесь, так же, стоит упомянуть и про другой параметр, hash_mem_multiplier. Этот параметр служит для определения максимального объема памяти, который может быть выделен для операций хэширования.
Итоговый объем определяется как произведение значения work_mem и коэффициента hash_mem_multiplier. По умолчанию hash_mem_multiplier равен 2.0, что означает, что для операций хэширования доступно в два раза больше памяти, чем базовое значение work_mem.
Лучше увеличить значение hash_mem_multiplier, если при выполнении запросов часто наблюдается сбрасывание данных на диск, а простое увеличение work_mem приводит к ошибкам нехватки памяти.
Постскриптум:
- при написании статьи использовалась следующая версия PostgreSQL v16.3
- к сожалению, Дзен перестал поддерживать функционал вставки исходного программного кода с syntax highlighting, на момент написания данной статьи. Про схожие проблемы рассказывают и другие Дзен-авторы: https://dzen.ru/a/XtUGaNtXXh9qY-gb поэтому вместо исходного кода, Вы видите комбинацию из картинки и ссылки на SQL-код в GitHub Gist. Прошу прощения за неудобства!