
Инженеры из Disney и ETH Zurich разработали метод обучения нейросетевого алгоритма для управления движениями трехмерных персонажей и роботов, который позволяет точно воспроизводить заданные движения на основе кинематических данных с учетом физики. Метод использует двухэтапный процесс обучения: сначала с помощью вариационного автоэнкодера создается внутреннее представление о базовых движениях, а затем обучается политика управления, которая использует это представление для генерации команд управления движениями. Такой подход обеспечивает реалистичное и плавное выполнение движений, адаптируясь к физическим ограничениям и используя движения, которых не было в обучающей выборке. Алгоритм успешно протестировали на виртуальном персонаже в симуляции, а также на человекоподобном роботе с 20 степенями свободы. Подробное описание метода опубликовано на сайте Disney Research.
Один из наиболее очевидных способов анимировать трехмерного виртуального персонажа или обучить реального робота сложному движению — запрограммировать их вручную, описав нужные последовательности действий. Однако на это уходит много времени и усилий, а результат решает только одну конкретную задачу. В последнее время на смену этому традиционному методу пришло машинное обучение, с помощью которого можно автоматизировать процесс создания анимации. К примеру, в 2018 году был представлен нейросетевой алгоритм, позволяющий обучать виртуальных персонажей сложным реалистичным движениям, используя в качестве исходных данных видеоролики, где эти движения выполняют реальные люди.
Однако, несмотря на достигнутый прогресс, эти методы несовершенны и сталкиваются со множеством проблем. Они не способны, например, к обобщению движений, не умеют использовать движения, с которыми не сталкивались во время обучения, требуют дополнительных механизмов для переключения между разными навыками и не учитывают физические ограничения, накладываемые реальным миром. Последнее приводит к неестественным и неустойчивым движениям, которые невозможно перенести из симуляции на реального робота.
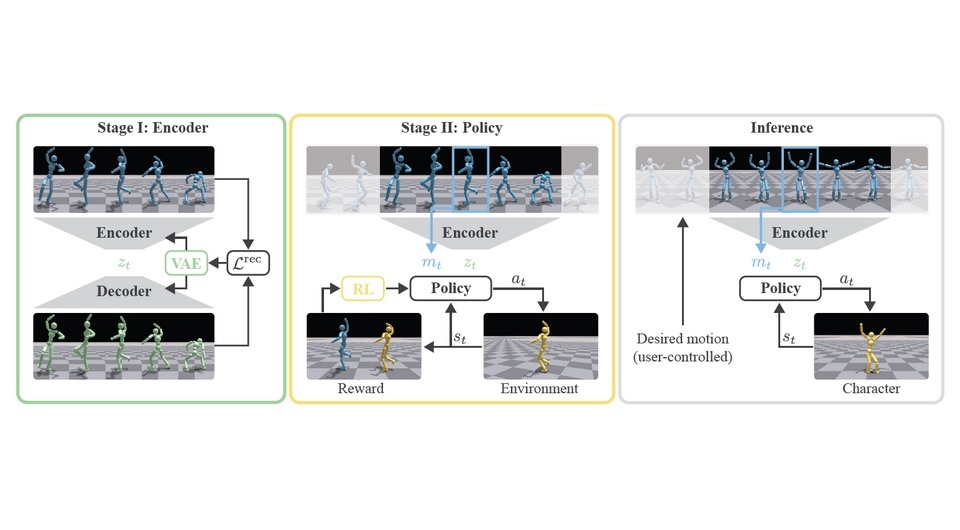

Эти проблемы попыталась решить инженеры из Швейцарской высшей технической школы Цюриха и исследовательского подразделения компании Disney. Разработанный ими метод состоит из двух этапов. На первом происходит обучение вариационного автоэнкодера — нейросетевого алгоритма, который учится представлять сложные данные в более компактной форме, называемой латентным пространством. Для обучения использовались трехмерные данные о кинематике различных движений, таких как ходьба, прыжки, и так далее, то есть информация о положении суставов и конечностей персонажей, полученная, например, с помощью системы захвата движений. Общая продолжительность всех использованных анимационных клипов составляет 11 часов. Эти данные сперва разбили на небольшие последовательности кадров, а затем переводили с помощью автоэнкодера в кодированное представление.
На втором этапе, используя это сжатое представление, содержащее обобщенную информацию о различных типах движения, инженеры натренировали с помощью метода обучения с подкреплением нейросетевую политику, которая может управлять движениями виртуального гуманоидного персонажа или робота. В процессе обучения модель получала вознаграждения за точное воспроизведение заданных движений и сохранение устойчивости. Обучение нейросети политики, состоящей из трех скрытых слоев по 512 нейронов, выполнялось с помощью алгоритма проксимальной оптимизации политики (Proximal Policy Optimization) в симуляторе Isaac Gym, предназначенном для тренировки роботов, на видеокарте RTX 4090 в течение 48 часов.
Полученная таким образом политика управления принимает на вход данные о движении (например, куда персонаж или робот должен шагнуть в следующую секунду) и превращает их в команды управления суставами реального робота или персонажа в симуляции с учетом физики и возможных ограничений движения персонажа. При этом она способна корректно воспроизводить даже незнакомые последовательности движений, которые не встречались в процессе обучения. Кроме этого модель оказалась не подвержена так называемому коллапсу моды — ситуации, когда модель склоняется только к одному типу поведения или ограниченному числу примеров из всех возможных, игнорируя другие, что снижает способность адаптироваться к новым ситуациям.
Политика управления, обученная этим методом, была успешно протестирована в симуляции на виртуальном персонаже с 36 степенями свободы. Который повторял заданный разработчиками набор разнообразных движений. А также на реальном человекоподобном роботе LIME с 20 степенями свободы и массой около 16 килограмм. Робот под управлением политики, натренированной с учетом характеристик его приводов, а также с применением метода доменной рандомизации, которая позволяет сократить разрыв между симуляцией и реальным миром, оказался способен точно выполнять заданные танцевальные движения, удерживая при этом баланс.
Если робот сталкивался с небольшими отклонениями в движении, например, со скольжением или случайным изменением угла наклона, модель быстро корректировала команды, чтобы предотвратить падение. Кроме этого, модель научилась учитывать физические ограничения конструкции робота. Например, поскольку у робота отсутствуют приводы наклона голеностопного сустава, он не может удерживать равновесие, стоя на одной ноге. Однако модель нашла выход из этой ситуации и вместо отрыва ноги от пола ставит соответствующую ногу на носок, чтобы приближенно воспроизводить заданную позу без опасности потерять равновесие.
Этот пример показывает, как при переносе готовых систем управления на реальных роботов инженеры могут столкнуться с тем, что те не обладают достаточным набором степеней свободы. Чтобы решить эту проблему, ранее разработчики из Disney Research представили алгоритм, позволяющий создавать проволочные каркасы реалистично двигающихся роботов, повторяющих заданные движения виртуальных персонажей.