Глубокое обучение (англ. deep learning) – это область машинного обучения, которая использует многослойные искусственные нейронные сети для решения сложных задач в таких областях, как обработка изображений, распознавание речи, игра в шахматы и го, а также диагностика заболеваний. Архитектуры нейронных сетей играют ключевую роль в успехе глубокого обучения, так как они определяют, как данные обрабатываются и как обучается модель.
Основные типы архитектур нейронных сетей
Полносвязные нейронные сети (Fully Connected Networks, FCN)
Полносвязные нейронные сети, также известные как многослойные перцептроны (MLP), являются одной из самых фундаментальных и широко используемых архитектур в глубокого обучения. Эти сети состоят из нескольких слоев нейронов, где каждый нейрон одного слоя соединен с каждым нейроном следующего слоя, отсюда и название "полносвязные".
Основные компоненты
Полносвязные нейронные сети состоят из трех основных типов слоев:
- Входной слой:
- Принимает входные данные.
- Количество нейронов во входном слое соответствует размеру входного вектора данных.
- Например, если у нас есть изображение 28x28 пикселей (784 пикселя), входной слой будет иметь 784 нейрона.
- Скрытые слои:
- Один или несколько слоев между входным и выходным слоями.
- Количество нейронов в каждом скрытом слое и количество самих слоев могут варьироваться.
- Нейроны в скрытых слоях используют активационные функции для обработки данных.
- Популярные активационные функции: ReLU (Rectified Linear Unit), сигмоидная функция, гиперболический тангенс (tanh).
- Выходной слой:
- Выдает конечный результат модели.
- Количество нейронов в выходном слое зависит от задачи.
- Для задачи классификации на N классов в выходном слое будет N нейронов.
- Для задачи регрессии может быть один нейрон, представляющий предсказанное значение.
Процесс работы полносвязных сетей
- Прямое распространение (Forward Propagation):
- Входные данные проходят через каждый слой сети.
- На каждом этапе выполняются линейные преобразования, за которыми следуют нелинейные активационные функции.
- Например, для одного нейрона:
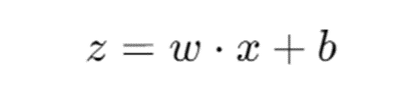
где z - взвешенная сумма входов, w - веса, x - входы, b - смещение.
- Результат z затем проходит через активационную функцию a=ϕ(z).
- Функция потерь (Loss Function):
- После получения предсказанного значения сетью, вычисляется ошибка (потеря) по сравнению с реальным значением.
- Для задач классификации часто используется кросс-энтропийная функция потерь.
- Для задач регрессии - среднеквадратическая ошибка (MSE).
- Обратное распространение (Backpropagation):
- Используется для обновления весов сети на основе градиента функции потерь.
- Градиенты вычисляются с использованием цепного правила, начиная с выхода сети и продвигаясь к входу.
- Веса обновляются с помощью алгоритма градиентного спуска или его вариантов, таких как стохастический градиентный спуск (SGD), Adam и другие.
Пример полносвязной сети
Рассмотрим пример полносвязной нейронной сети с одним скрытым слоем для задачи бинарной классификации:
- Входной слой: 3 нейрона (например, три входных признака).
- Скрытый слой: 4 нейрона с активационной функцией ReLU.
- Выходной слой: 1 нейрон с сигмоидной активационной функцией для предсказания вероятности.

Преимущества и недостатки полносвязных сетей
Преимущества:
- Простота реализации и понимания.
- Универсальность: могут использоваться для различных типов задач (классификация, регрессия и т.д.).
- Хорошо работают с данными, которые можно представить в виде вектора фиксированной длины.
Недостатки:
- Плохо масштабируются с увеличением числа признаков или размерности данных.
- Не учитывают пространственные или временные зависимости в данных (например, в изображениях или временных рядах).
- Могут переобучаться на небольших наборах данных, требуя регуляризации или использования дополнительных техник (например, дропаут).
Полносвязные нейронные сети являются важным строительным блоком глубокого обучения и часто служат отправной точкой для более сложных архитектур. Несмотря на свои ограничения, они остаются мощным инструментом для многих задач и продолжают играть важную роль в развитии искусственного интеллекта и машинного обучения.
Свёрточные нейронные сети (Convolutional Neural Networks, CNN)
Свёрточные нейронные сети (CNN) – это класс глубоких нейронных сетей, специально разработанный для обработки данных с сеточной топологией, таких как изображения. CNN широко используются в задачах компьютерного зрения, таких как распознавание объектов, классификация изображений и сегментация.
Основные компоненты свёрточных нейронных сетей
CNN состоят из нескольких типов слоев, каждый из которых выполняет специфические функции:
- Свёрточные слои (Convolutional Layers)
- Подвыборочные (Pooling) слои
- Слои нормализации
- Полносвязные слои (Fully Connected Layers)
- Активационные функции
Свёрточные слои
Свёрточные слои являются основой CNN. Они применяют фильтры (ядра свёртки) к входным данным для выделения признаков.
Основные понятия:
- Фильтр (ядро): Набор весов, которые используются для выполнения свёртки. Обычно фильтр имеет размерность k×k (например, 33×3 или 55×5).
- Свертка (Convolution): Операция, при которой фильтр скользит по входным данным, производя скалярное произведение между фильтром и подматрицей входных данных.
- Stride: Шаг, с которым фильтр перемещается по входным данным. Увеличение stride уменьшает размер выходной карты признаков.
- Padding: Добавление нулей по краям входных данных для сохранения размерности выходных данных после свёртки.
Пример:
Допустим, у нас есть входное изображение размером 32×32×3 (ширина, высота, количество каналов). Применяя фильтр размером 3×3×3 stride 1 и padding 1, мы получим выходное изображение того же размера 32×32×1.
Подвыборочные (Pooling) слои
Pooling слои используются для уменьшения размерности данных, что позволяет уменьшить количество параметров и вычислительные затраты.
Основные типы:
- Макспулинг (Max Pooling): Выбирает максимальное значение из подматрицы.
- Среднее пуллинг (Average Pooling): Вычисляет среднее значение подматрицы.
Пример:
Если применить max pooling с размером окна 2×2 и stride 2 к изображению размером 32×32×1, выход будет иметь размер 16×16×1.
Слои нормализации
Нормализация помогает ускорить обучение и улучшить производительность сети.
Основные типы:
- Batch Normalization: Нормализует входы каждого слоя, используя среднее и стандартное отклонение мини-батча данных.
Полносвязные слои
В конце сети используются полносвязные слои для объединения выделенных признаков и классификации данных.
Активационные функции
Активационные функции добавляют нелинейность в модель, позволяя сети учить сложные зависимости.
Основные активационные функции:
Пример архитектуры CNN
Рассмотрим пример простой CNN для задачи классификации изображений (например, CIFAR-10):
Преимущества и недостатки свёрточных сетей
Преимущества:
- Автоматическое выделение признаков: фильтры обучаются автоматически, что устраняет необходимость ручной инженерии признаков.
- Меньше параметров: по сравнению с полносвязными сетями, CNN имеют меньше параметров благодаря локальным связям и пуллингу.
- Пространственные зависимости: учитывают пространственные структуры в данных, такие как соседние пиксели в изображении.
Недостатки:
- Требуют больших данных: для обучения требуют больших объемов данных.
- Выжны вычислительные ресурсы: требуют значительных вычислительных ресурсов для тренировки и инференса.
- Сложность настройки: множество гиперпараметров, таких как размер фильтра, шаг и padding, требуют настройки.
Свёрточные нейронные сети являются мощным инструментом для обработки изображений и других данных с сеточной топологией. Их способность автоматически выделять важные признаки и учитывать пространственные зависимости делает их незаменимыми в современных задачах компьютерного зрения. Несмотря на сложности настройки и высокие требования к данным и вычислительным ресурсам, CNN продолжают оставаться основным выбором для множества приложений в области глубокого обучения.
Рекуррентные нейронные сети (Recurrent Neural Networks, RNN)
Рекуррентные нейронные сети (RNN) – это класс нейронных сетей, которые особенно эффективны для обработки последовательных данных, таких как временные ряды, тексты, аудио и видео. В отличие от традиционных нейронных сетей, RNN имеют связи между нейронами, направленные как вперед, так и назад, что позволяет им учитывать предыдущие состояния при обработке текущего ввода.
Основные компоненты рекуррентных нейронных сетей
- Входной слой
- Рекуррентные слои
- Выходной слой
Входной слой
Входной слой принимает данные на каждом шаге последовательности. Например, если сеть обрабатывает текст, на вход подается один символ или одно слово за один шаг.
Рекуррентные слои
Рекуррентные слои являются сердцем RNN. В этих слоях нейроны имеют связи с самим собой, что позволяет сохранять информацию о предыдущих шагах последовательности.
Основные компоненты:
- Скрытое состояние (Hidden State): Вектор, который хранит информацию о предыдущих шагах.
- Рекуррентное обновление: На каждом шаге последовательности скрытое состояние обновляется на основе текущего входа и предыдущего скрытого состояния.
Формально:
Выходной слой
Выходной слой производит предсказание на каждом шаге последовательности или одно общее предсказание после обработки всей последовательности.
Формально:
Типы RNN
- Базовые RNN: Самый простой тип RNN, который страдает от проблемы затухающих и взрывающих градиентов.
- LSTM (Long Short-Term Memory): Улучшенная версия RNN, способная запоминать информацию на длительные периоды времени.
- GRU (Gated Recurrent Unit): Упрощенная версия LSTM, которая также решает проблему затухающих градиентов.
LSTM (Long Short-Term Memory)
LSTM имеют сложную архитектуру, включающую ячейки памяти и управляющие гейты для контроля потока информации.
Основные компоненты:
- Ячейка памяти (Cell State): Хранит долгосрочную информацию.
- Забывающий гейт (Forget Gate): Решает, какую информацию удалить из ячейки памяти.
- Входной гейт (Input Gate): Решает, какую новую информацию добавить в ячейку памяти.
- Выходной гейт (Output Gate): Решает, какую информацию передать на следующий шаг.
GRU (Gated Recurrent Unit)
GRU объединяет забывающий и входной гейты в один единый гейт, что упрощает архитектуру по сравнению с LSTM.
Основные компоненты:
- Обновляющий гейт (Update Gate): Контролирует, какую информацию сохранить и какую удалить.
- Сбросной гейт (Reset Gate): Контролирует, какую информацию использовать для обновления состояния.
Пример архитектуры RNN
Рассмотрим пример простой RNN для задачи предсказания следующего символа в тексте:
- Входной слой: Символ на каждом шаге последовательности.
- Рекуррентный слой: Скрытое состояние обновляется на каждом шаге.
- Выходной слой: Вероятность следующего символа.
Преимущества и недостатки рекуррентных нейронных сетей
Преимущества:
- Обработка последовательных данных: Идеально подходят для временных рядов, текста, аудио и видео.
- Сохранение информации о предыдущих шагах: Учитывают контекст при обработке текущего ввода.
- Улучшенные версии (LSTM и GRU): Решают проблемы затухающих и взрывающих градиентов, что позволяет обрабатывать длинные последовательности.
Недостатки:
- Проблемы с обучением: Базовые RNN страдают от затухающих и взрывающих градиентов, что затрудняет обучение.
- Требовательность к ресурсам: LSTM и GRU имеют более сложные архитектуры, требующие больше вычислительных ресурсов.
- Последовательная обработка: Обработка данных происходит шаг за шагом, что может быть медленнее по сравнению с параллельными архитектурами.
Рекуррентные нейронные сети и их усовершенствованные версии, такие как LSTM и GRU, являются мощным инструментом для обработки последовательных данных. Их способность сохранять информацию о предыдущих шагах и учитывать контекст делает их незаменимыми в задачах, связанных с временными рядами, текстом и другими последовательностями. Несмотря на сложности обучения и высокие требования к вычислительным ресурсам, RNN продолжают играть ключевую роль в современных приложениях машинного обучения.
Долгая краткосрочная память (Long Short-Term Memory, LSTM) и Гейтид рекуррентные блоки (Gated Recurrent Unit, GRU)
LSTM и GRU – это усовершенствованные версии рекуррентных нейронных сетей (RNN), разработанные для решения проблем затухающих и взрывающих градиентов, которые часто встречаются в базовых RNN. Эти архитектуры позволяют более эффективно обрабатывать длинные последовательности данных, сохраняя долгосрочную зависимость.
Долгая краткосрочная память (Long Short-Term Memory, LSTM)
LSTM сети были предложены Шмидхубером и Хохрайтером в 1997 году. Основная идея LSTM заключается в использовании специальных структур, называемых ячейками памяти, которые могут сохранять информацию на длительные периоды времени. Эти ячейки управляются тремя типами гейтов: забывающим, входным и выходным, которые регулируют поток информации через ячейку.
Основные компоненты:
1. Ячейка памяти (Cell State):
- Хранит долгосрочную информацию.
- Информация может быть сохранена, удалена или прочитана через гейты.
2. Забывающий гейт (Forget Gate):
- Решает, какую часть информации из ячейки памяти удалить.
3. Входной гейт (Input Gate):
- Решает, какую новую информацию добавить в ячейку памяти.
- Формула:
4. Кандидат на обновление состояния ячейки (Cell State Update):
- Создает новый кандидат для обновления состояния ячейки.
- Формула:
5. Обновление состояния ячейки:
- Обновляет текущее состояние ячейки на основе забывающего и входного гейтов.
- Формула:
6. Выходной гейт (Output Gate):
- Решает, какую часть информации из ячейки памяти передать в следующее скрытое состояние.
7. Скрытое состояние (Hidden State):
- Обновляется на основе выходного гейта и текущего состояния ячейки.
- Формула:
Гейтид рекуррентные блоки (Gated Recurrent Unit, GRU)
GRU были предложены Чо и соавторами в 2014 году. GRU объединяют забывающий и входной гейты в один гейт, что упрощает архитектуру по сравнению с LSTM. GRU также имеют сбросной гейт, который контролирует, какую часть предыдущего состояния использовать для вычисления нового кандидата.
Основные компоненты:
Обновляющий гейт (Update Gate):
- Контролирует, какую информацию сохранить и какую удалить.
Сбросной гейт (Reset Gate):
- Контролирует, какую информацию использовать для обновления состояния.
- Формула:
Кандидат на обновление состояния (Candidate Update):
- Создает новый кандидат для состояния, учитывая сбросной гейт.
- Формула:
Скрытое состояние (Hidden State):
- Обновляется на основе обновляющего гейта и нового кандидата.
- Формула:
Преимущества и недостатки LSTM и GRU
Преимущества:
- Улучшенное запоминание долгосрочной информации: И LSTM, и GRU могут эффективно сохранять долгосрочную информацию.
- Гибкость в обработке последовательностей разной длины: Обе архитектуры могут работать с последовательностями разной длины, что делает их универсальными для многих задач.
- Решение проблемы затухающих градиентов: Гейты позволяют контролировать поток информации, что помогает решать проблемы затухающих градиентов.
Недостатки:
- Сложность и вычислительная нагрузка: LSTM более сложны и требуют больше вычислительных ресурсов по сравнению с базовыми RNN.
- GRU менее гибкие: Хотя GRU проще и менее вычислительно затратны, они могут быть менее гибкими в некоторых задачах по сравнению с LSTM.
Заключение
LSTM и GRU являются мощными инструментами для обработки последовательных данных, решая многие проблемы базовых RNN. Благодаря своим улучшенным архитектурам и способности сохранять долгосрочную информацию, они находят широкое применение в таких областях, как обработка естественного языка, временные ряды, предсказание и многое другое. Выбор между LSTM и GRU зависит от конкретной задачи, доступных вычислительных ресурсов и требований к модели.
Модель Трансформеры (Transformers)
Трансформеры (Transformers) – это архитектура нейронных сетей, предложенная в 2017 году Васвани и соавторами в статье "Attention is All You Need". Трансформеры были разработаны для обработки последовательных данных и заменили рекуррентные нейронные сети (RNN) и долгосрочные краткосрочные памяти (LSTM) в многих задачах обработки естественного языка (NLP).
Основные компоненты трансформеров
Трансформер состоит из двух основных частей: энкодера и декодера, каждая из которых состоит из нескольких одинаковых слоев. Ниже рассмотрены основные компоненты энкодера и декодера.
Энкодер
Энкодер принимает входную последовательность и преобразует ее в последовательность скрытых представлений.
Основные компоненты энкодера:
1. Входное представление (Input Embedding):
- Входные слова или токены преобразуются в эмбеддинги фиксированной размерности.
2. Позиционное кодирование (Positional Encoding):
- Поскольку трансформеры не используют рекуррентные или свёрточные слои, необходимо добавить информацию о позиции токенов в последовательности. Позиционное кодирование добавляется к эмбеддингам входных токенов.
- Формула для позиционного кодирования:
3. Мультиголовное внимание (Multi-Head Attention):
- Включает в себя несколько "голов" внимания, каждая из которых фокусируется на разных частях входной последовательности. Это позволяет модели захватывать разные аспекты информации.
- Формула для вычисления внимания (scaled dot-product attention):
4. Механизм нормализации (Layer Normalization):
- Применяется после каждой операции внимания и полносвязного слоя для стабилизации обучения.
- Полносвязный слой (Feed-Forward Network):
- Состоит из двух линейных преобразований с нелинейностью между ними.
- Формула:
Декодер
Декодер принимает последовательность скрытых представлений от энкодера и генерирует выходную последовательность.
Основные компоненты декодера:
- Входное представление (Input Embedding):
- Входные слова или токены преобразуются в эмбеддинги фиксированной размерности.
- Позиционное кодирование (Positional Encoding):
- Аналогично энкодеру, позиционное кодирование добавляется к эмбеддингам входных токенов.
- Мультиголовное внимание (Masked Multi-Head Attention):
- Подобно мультиголовному вниманию в энкодере, но с маскированием, чтобы предотвратить доступ к будущим токенам в последовательности.
- Мультиголовное внимание с кросс-энкодером (Encoder-Decoder Attention):
- Фокусируется на скрытых представлениях, полученных от энкодера, что позволяет декодеру учитывать информацию из входной последовательности.
- Механизм нормализации (Layer Normalization):
- Применяется после каждой операции внимания и полносвязного слоя для стабилизации обучения.
- Полносвязный слой (Feed-Forward Network):
- Аналогично энкодеру, состоит из двух линейных преобразований с нелинейностью между ними.
Пример работы трансформера
Рассмотрим пример, как трансформер обрабатывает последовательность текста:
- Энкодер:
- Входная последовательность: "The cat is on the mat".
- Каждый токен преобразуется в эмбеддинг и добавляется позиционное кодирование.
- Применяется мультиголовное внимание, нормализация и полносвязные слои.
- Результат: последовательность скрытых представлений.
- Декодер:
- Входная последовательность: "Le chat est sur".
- Каждый токен преобразуется в эмбеддинг и добавляется позиционное кодирование.
- Применяется мультиголовное внимание с маскированием, нормализация, мультиголовное внимание с кросс-энкодером и полносвязные слои.
- Результат: предсказание следующего токена в выходной последовательности.
Преимущества и недостатки трансформеров
Преимущества:
- Высокая параллелизация: В отличие от RNN, трансформеры обрабатывают весь вход параллельно, что ускоряет обучение и инференс.
- Эффективное захват контекста: Механизм внимания позволяет модели учитывать длинные зависимости в данных.
- Гибкость и универсальность: Трансформеры могут использоваться в различных задачах, таких как машинный перевод, обработка текста, генерация текста и др.
Недостатки:
- Высокие вычислительные затраты: Механизм внимания требует значительных вычислительных ресурсов, особенно для длинных последовательностей.
- Требовательность к данным: Для успешного обучения трансформеры требуют больших объемов данных.
Трансформеры представляют собой мощную и гибкую архитектуру для обработки последовательных данных. Благодаря механизму внимания они способны эффективно захватывать длинные зависимости в данных и обеспечивать высокую производительность в различных задачах. Несмотря на высокие вычислительные затраты, трансформеры стали основой современных моделей NLP и продолжают находить новые применения в различных областях машинного обучения.
Применение различных архитектур
Каждая архитектура нейронной сети имеет свои сильные и слабые стороны, и выбор архитектуры зависит от конкретной задачи:
- Полносвязные сети: подходят для задач классификации и регрессии, где данные можно представить в виде фиксированной длины векторов.
- Свёрточные сети: используются в компьютерном зрении для распознавания образов, классификации изображений и объектного детектирования.
- Рекуррентные сети, LSTM и GRU: применяются для анализа временных рядов, обработки текста, предсказания последовательностей и задач NLP.
- Трансформеры: становятся стандартом для задач NLP, включая машинный перевод, вопросно-ответные системы и генерацию текста.
Заключение
Глубокое обучение и его разнообразные архитектуры нейронных сетей предоставляют мощные инструменты для решения широкого спектра задач. Каждая архитектура имеет свои уникальные особенности, позволяющие ей эффективно справляться с различными типами данных и задач. С развитием технологий и появлением новых подходов, нейронные сети будут продолжать эволюционировать, открывая новые возможности в науке и индустрии.
Хотите создать уникальный и успешный продукт? Доверьтесь профессионалам! Компания СМС предлагает комплексные услуги по разработке, включая дизайн, программирование, тестирование и поддержку. Наши опытные специалисты помогут вам реализовать любые идеи и превратить их в высококачественный продукт, который привлечет и удержит пользователей.
Закажите разработку у СМС и получите:
· Индивидуальный подход к каждому проекту
· Высокое качество и надежность решений
· Современные технологии и инновации
· Полное сопровождение от идеи до запуска
Не упустите возможность создать платформу, которая изменит мир общения! Свяжитесь с нами сегодня и начните путь к успеху вместе с СМС.
С уважением,
Генеральный директор ООО «СМС»
Марина Сергеевна Строева
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru