Учитывая скорость развития нейросетей и ежедневный запуск ИИ-стартапов, становится сложно отслеживать их развитие и обновления, для Вашего удобства мы нашли инструмент который всегда содержит самую актуальную информацию и регулярно обновляется
Представляем MMLU-Pro, усовершенствованный бенчмарк, предназначенный для оценки моделей понимания языка по более широким и сложным задачам. Основываясь на наборе данных Massive Multitask Language Understanding (MMLU), MMLU-Pro интегрирует более сложные, ориентированные на рассуждения вопросы и увеличивает количество вариантов ответов на вопрос от четырех до десяти, значительно повышая сложность и уменьшая шанс случайного успеха. MMLU-Pro включает более 12,000 тщательно отобранных вопросов из академических экзаменов и учебников, охватывая 14 различных областей, включая биологию, бизнес, химию, компьютерные науки, экономику, инженерное дело, здоровье, историю, право, математику, философию, физику, психологию и другие.
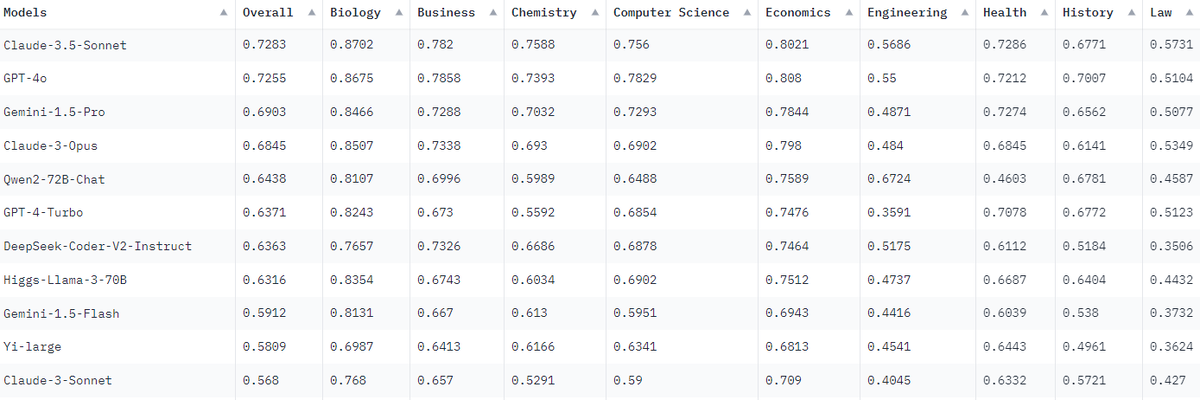
Новое в MMLU-Pro
По сравнению с оригинальным MMLU, есть три основных отличия:
Оригинальный набор данных MMLU содержит только 4 варианта ответов, а MMLU-Pro увеличивает это количество до 10. Увеличение количества вариантов ответов делает оценку более реалистичной и сложной. Случайное угадывание приведет к значительно более низкому результату.
Оригинальный набор данных MMLU содержит в основном вопросы, основанные на знаниях, не требующие значительного рассуждения. Поэтому результаты PPL обычно лучше, чем CoT. В нашем наборе данных мы увеличиваем сложность задач и интегрируем более сложные задачи, требующие рассуждения. В MMLU-Pro CoT может быть на 20% выше, чем PPL.
Увеличивая количество отвлекающих вариантов, мы значительно уменьшаем вероятность случайного угадывания, чтобы повысить надежность оценки. В частности, при тестировании 24 различных стилизованных запросов, чувствительность результатов моделей к изменениям запросов уменьшилась с 4-5% в MMLU до 2% в MMLU-Pro.
Для получения подробной информации о наборе данных посетите нашу страницу на Hugging Face: https://huggingface.co/datasets/TIGER-Lab/MMLU-Pro.
Если вы хотите повторить эти результаты или оценить свои модели с помощью нашего набора данных, доступны наши скрипты оценки на GitHub: https://github.com/TIGER-AI-Lab/MMLU-Pro.
Если вы хотите узнать больше о нашем наборе данных, пожалуйста, ознакомьтесь с нашей статьей: https://arxiv.org/abs/2406.01574.
Рейтинг регулярно обновляется, все сравнения и строчки списка смотрим тут.