
Последние годы ознаменовались бурным развитием больших языковых моделей (LLM). В январе мы уже рассказывали про большие языковые модели и лайфхаки при работе с ними. LLM демонстрируют впечатляющие возможности в решении широкого спектра задач - от ответов на вопросы до генерации кода, позволяя бизнесу тратить меньше сил на решение рутинных задач.
Такой бум в сфере генеративного искусственного интеллекта связан со следующими причинами:
1. Выход в публичный доступ GPT-3,5 и GPT-4 от OpenAI, что позволило обычным пользователям протестировать LLM в самых разных задачах.
2. Появление огромного количества LLM с открытым исходным кодом, что открыло широкие возможности для настройки таких моделей.
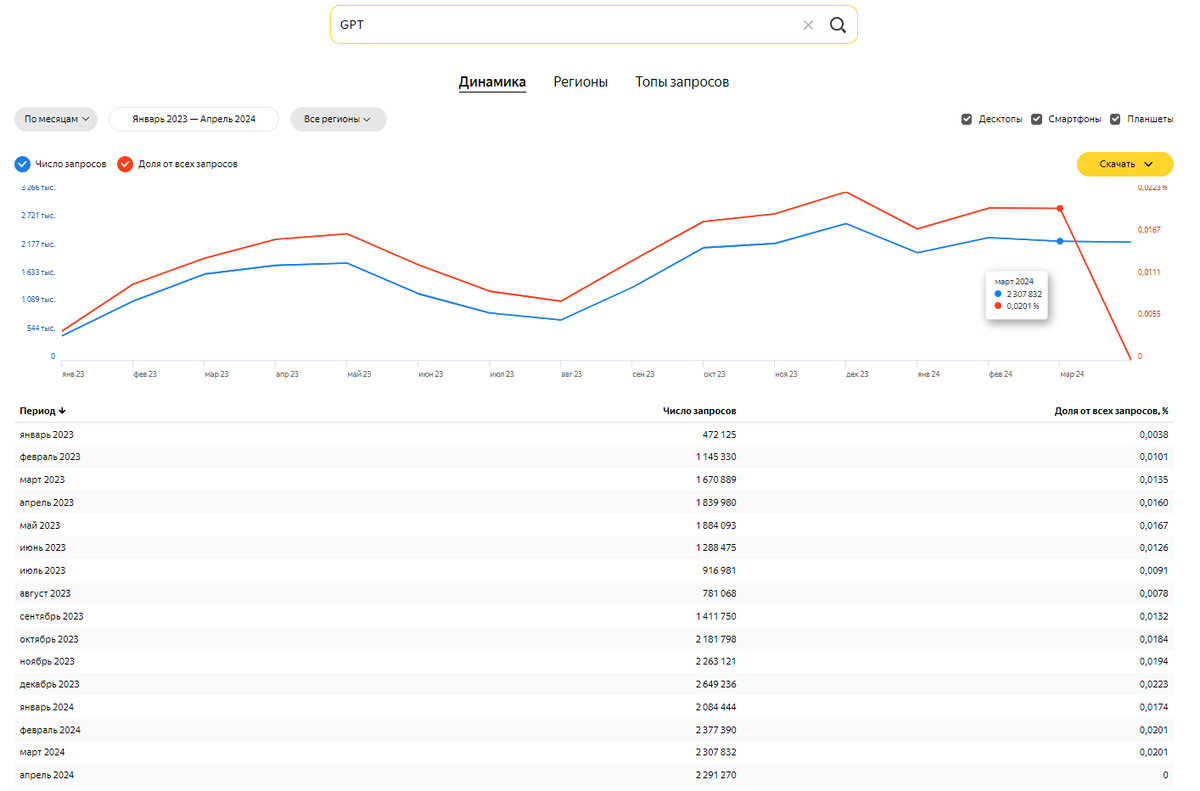
В среднем в 2024 году каждый месяц GPT-подобные модели в Яндексе ищут от 2 миллионов раз, что составляет 0,02% от всех запросов в поисковике Яндекса.
Это первая статья из цикла материалов про генеративные нейросети, посвященная базовой информации по большим языковым моделям. В дальнейшем выйдет статья с бо́льшим погружением в LLM.
Что же такое LLM?
LLM (Large Language Models) – это модели искусственного интеллекта, которые обучены на огромных объемах текстовых данных и могут генерировать человекоподобный текст. LLM очень похожи на модель трансформера, но в больших масштабах. Она обладает замечательными свойствами, предназначенными для понимания контекста и смысла с помощью анализа отношений внутри данных.
Эти модели представляют собой революционный прорыв в области обработки естественного языка. Они используют передовые алгоритмы машинного обучения, чтобы анализировать и понимать огромные массивы текстовых данных, выявляя скрытые закономерности и связи. Это позволяет им не просто воспроизводить текст, но и генерировать новый, осмысленный и связный контент.
За последние несколько лет OpenAI внесла большой вклад в генеративный ИИ своими моделями и исследованиями. Однако на рынке есть и другие игроки, например, Google со своими FLAN-T5 и BERT, StableLM от Stability AI, также есть много других моделей с открытым исходным кодом.
По данным LLM Explorer – компании, которая занимается тестами и аналитикой LLM, всего существует 39 тысяч больших языковых моделей.
Благодаря своим уникальным возможностям, LLM модели находят все более широкое применение в различных сферах, от маркетинга и продаж до медицины и образования. Они могут автоматизировать рутинные задачи, повышать эффективность бизнес-процессов, а также помогать людям в их повседневной жизни. Это делает их одним из наиболее перспективных направлений развития искусственного интеллекта на сегодняшний день.
Как LLM понимают смысл текста?
Одним из ключевых аспектов, который отличает LLM модели от более простых систем обработки естественного языка, является их способность улавливать нюансы и подтексты. Они могут распознавать иронию, метафоры, идиомы и другие лингвистические конструкции, которые требуют понимания контекста и смысла.
Это достигается благодаря тому, что LLM модели не просто сопоставляют слова с их определениями, а анализируют их взаимосвязи и роль в предложении. Они учитывают грамматические структуры, синтаксис, семантические поля и другие аспекты языка, чтобы глубже понять, что именно хотел сказать автор текста. Например, если написать запрос "cat sat on a", LLM предскажет слово “mat” с вероятностью 97%.
Такое глубокое понимание смысла и контекста позволяет LLM моделям генерировать текст, который не только грамматически и стилистически корректен, но и отражает истинный замысел и эмоциональную окраску сообщения. Это делает их незаменимыми помощниками в задачах, требующих тонкого анализа и интерпретации текстовой информации.
Как обучают большие языковые модели?
На высоком уровне обучение LLM включает в себя три этапа: сбор данных, обучение и оценку.
- Сбор данных (Data Collection): Первым шагом является сбор огромных объемов текстовых данных из различных источников, таких как Википедия, новостные статьи, книги, веб-сайты и другие. Эти данные служат "сырьем" для обучения модели, позволяя ей изучать закономерности и особенности естественного языка.
- Обучение (Training): На этом этапе данные проходят предварительную обработку и очистку, чтобы подготовить их для подачи в модель. Затем начинается сам процесс обучения, который может занимать недели или даже месяцы в зависимости от размера модели и объема данных.
- Оценка (Evaluation): После обучения модель проходит тестирование и оценку, чтобы определить, насколько хорошо она справляется с различными задачами. Это может включать в себя проверку способности модели отвечать на вопросы, обобщать информацию, переводить текст и выполнять другие языковые операции. Результаты оценки помогают понять сильные и слабые стороны модели, а также определить, нужна ли дополнительная настройка или обучение.
Итогом процесса обучения большой языковой модели является набор параметров или весов, которые представляют собой "знания", полученные моделью в ходе обучения на огромных объемах текстовых данных. Эти параметры, отражающие закономерности и особенности естественного языка, сохраняются в виде файла, который можно загрузить и использовать в различных приложениях, требующих возможностей обработки и генерации текста.
Типы LLM
В нашем Telegram-канале мы недавно рассказали о самых популярных решениях на рынке LLM.
LLM можно разделить на два основных типа: базовые LLM и, настроенные по инструкциям (Instruction Tuned LLM).
Базовые LLM — это LLM, предназначенные для предсказания следующего слова на основе обучающих данных. Они не предназначены для ответов на вопросы, проведения бесед или помощи в решении проблем. Если вы дадите базовому LLM предложение «Зачем нужен маркетинг?», оно может перефразировать и дать вам «Зачем нужен маркетинг? Действительно, зачем нужен маркетинг?». Как видите, он дает нам соответствующий текст, но не отвечает на вопрос. Именно здесь в игру вступают LLM, настроенные по инструкциям.
LLM, настроенные по инструкциям – это LLM, обученные поверх базовых LLM, который дополнительно обучается с использованием большого набора данных, охватывающего пример «Инструкций» и того, как модель должна работать в результате этих инструкций. Затем модель настраивается с помощью метода под названием «обучение с подкреплением с обратной связью человека» (RLHF), который позволяет модели учиться на обратной связи человека и со временем улучшать свою производительность.
Выводы
Большие языковые модели произвели прорыв в области обработки естественного языка (NLP), позволив машинам достигать беспрецедентного понимания и генерации человекоподобного текста. Эти мощные инструменты открывают широкие возможности для решения разнообразных языковых задач. LLM находят применение в множестве отраслей, таких как здравоохранение, финансы, образование и другие, автоматизируя процессы и повышая эффективность. Потенциал этих моделей заключается в их способности радикально преобразовать наше взаимодействие с компьютерами, сделав его более естественным и упрощающим нашу повседневную жизнь.