Microsoft только что представили инструмент You Only Cache Once: Decoder-Decoder : архитектура Decoder-Decoder для больших языковых моделей
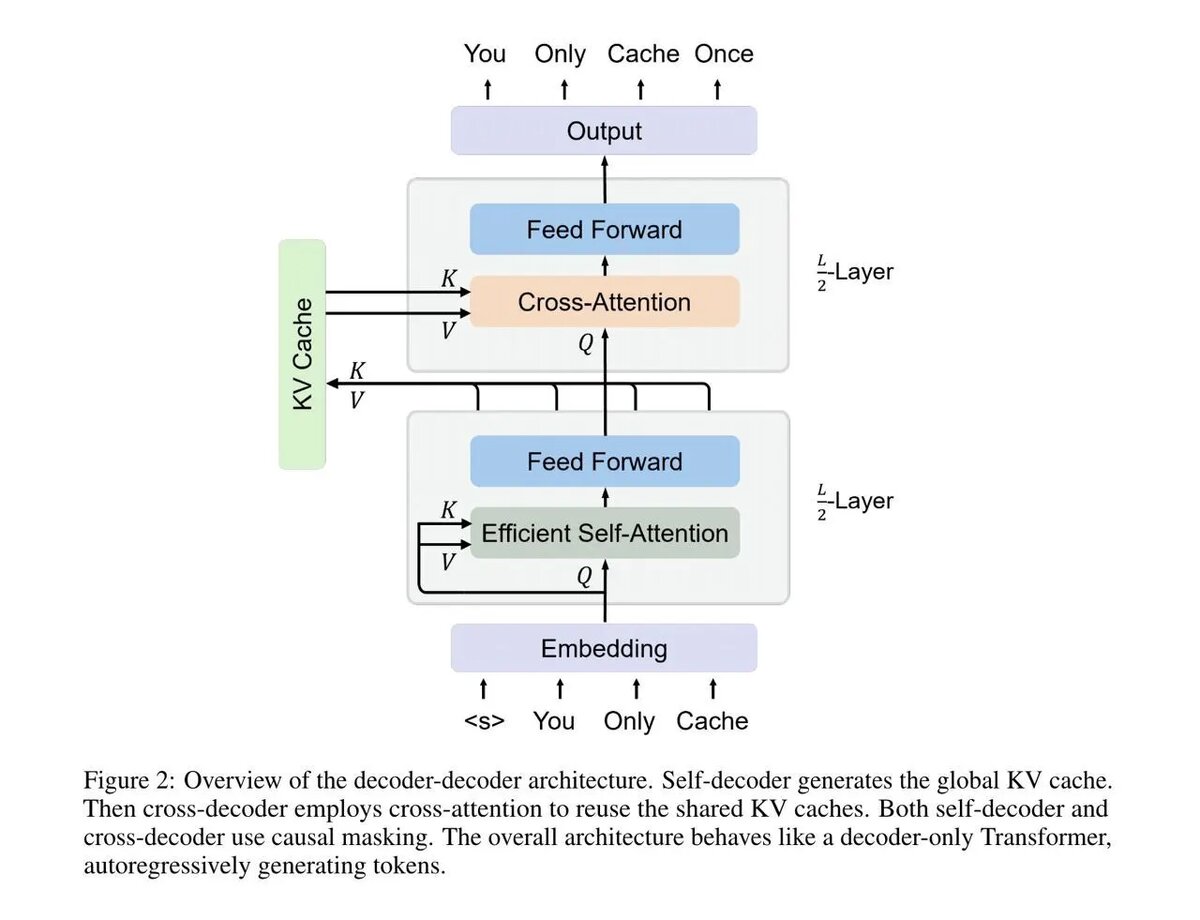
YOCO существенно снижает потребление памяти GPU и состоит из двух компонентов - cross decoder'а, объединенного с self-decoder'ом.

Self-decoder кодирует глобальные кэши
значений ключей (KV), которые повторно используются cross decoder'ом с механизмом cross-attention.
Результаты экспериментов показывают, что YOCO достигает более высокой производительности по сравнению с архитектурой Трансформеров при различных настройках масштабирования размера модели и количества обучающих токенов, подробнее тут.
▪Github: https://github.com/microsoft/unilm/tree/master/YOCO
▪ABS: https://arxiv.org/abs/2405.05254
Если интересуетесь машинным обучением и ИИ, здесь я публикую разбор свежих LLM и их разбор, статьи и гайды, кладезь полезной информации.