Возможности по модификации ЯПФ информационного графа алгоритма
На рис. 22 показана ЯПФ того алгоритма решения полного квадратного уравнения в вещественных числах SQUA_EQU_2.GV, однако красным пунктиром для трёх операторов (100, 102 и 103) показаны диапазоны возможного (не нарушающего информационные связи в алгоритме) перемещения между ярусами ЯПФ (этот диапазон несложно вычисляется по информационному графу алгоритма - ИГА).
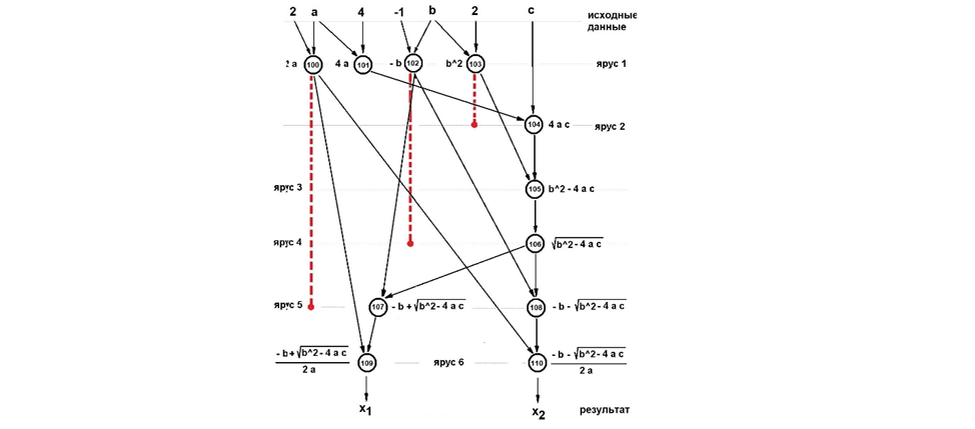
Невооружённым глазом видно, что перемещения любых двух операторов в пределах указанного красным пунктиром (а это и есть целенаправленная модификация) приводят к крайне привлекательным для вычислительной практики последствиям – вместо требуемых 4-х параллельных вычислителей (ибо ширина не преобразованной ЯПФ равна 4) теперь требуется всего 2 (ширина преобразованной ЯПФ равно 2) при той же самой высоте ЯПФ (она же параллельная сложность алгоритма, определяющая время его выполнения). Т.е. приведённый на рис. 22 алгоритм (в его ЯПФ) обладает следующими свойствами для его целенаправленной модификации:
- возможность снижения ширины ЯПФ (с целью выполнения на меньшем числе параллельных вычислителей) без увеличения высоты ЯПФ (сохранение времени выполнения)
- возможность дальнейшего снижения ширины ЯПФ (с целью выполнения на меньшем числе параллельных вычислителей) с увеличением высоты ЯПФ (возрастание времени выполнения).
Ключевым понятием тут является увеличение высоты ЯПФ. Оно определяет важнейший режим выполнения параллельной программы – время её выполнения (оно прямо зависит от числа ярусов ЯПФ – при допущении об одинаковости времён выполнения всех операторов, конечно).
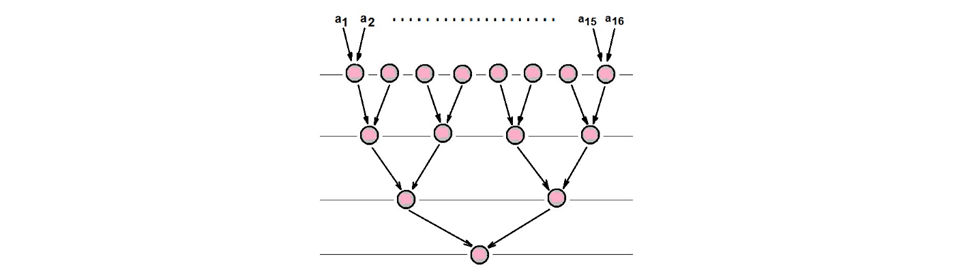
На рис. 23 показан алгоритм сдв́аивания (может быть применён ко всем операциям, обладающим свойством ассоциативности); на показанном на рисунке алгоритме производится суммирование 16 чисел (необходимое число ярусов ЯПФ при этом равно log2(16)=4).
На рис. 23 – пример алгоритма, отличающего невозможностью снижения ширины ЯПФ без увеличения её высоты! Логично ввести некоторый коэффициент Vt , определяющий степень возможности перестановок операторов с яруса на ярус ЯПФ (напр., в форме усреднённых по межъярусным промежуткам диапазонов возможного расположения операторов):
где T – общее число ярусов, Ti/max и Ti/min - максимальный и минимальный номера ярусов данной ЯПФ, на которых может располагаться i-тый оператор (суммирование ведётся по i); Ti/max и Ti/min фактически определяют диапазон возможного расположения i-того оператора в единицах ярусов.
Для алгоритма сдваивания (файл графа DOUBLING_32.GV) имеем Vt =0 (т.к. Ti/max = Ti/min для всех i в выражении (4); можно предположить, что с увеличением коэффициента Vt упростится сама возможность преобразования ЯПФ методом перемещения операторов с яруса на ярус. Метафорически говоря, можно считать, что вариативность (способность к изменениям, пода́тливость ЯПФ) возрастает при росте сложности ИГА (как временно́й, так и пространственной).
Кстати, значение Vt выдаётся в нижней части текстового окна инструмента ПРАКТИКУМ SPF и его (это значение) полезно учитывать при разработке Lua-скриптов для модификации ЯПФ.
Кстати – “вопрос на засы́пку”… Как - по Вашему мнению – при перемещении конкретного оператора между ярусами ЯПФ диапазон допусти́мых перемещений иных операторов изменится или же нет? Ведь если ответом будет "да", то это означает, что результат многократного использования данной операции зависит от последовательности её применения..!
Каждая ЯПФ фактически уже является планом (расписанием) параллельного выполнения программы – каждый ярус начиная с первого последовательно выполняется на параллельной вычислительной системе. Автору нравится термин “каркас” (скелет) в смысле необходимости дальнейшего “обшива́ния” его ́”мясом и кожей” (имеются в виду аппаратно-программные технологии параллельного программирования).
Только что полученная ЯПФ соответствует условиям неограниченного параллелизма, является и должна рассматриваться “сыро́й” вследствие крайне неравномерного распределения по ярусам количества операторов (при прямом использовании очень неэффективно будут использованы отдельные вычислители параллельного вычислительного поля). Отсюда следует вывод о необходимости целенаправленных изменений ЯПФ - как сказано, автоматизировать этот процесс в данной работе предлагается с использованием встроенного скриптового языка (в конкретно случае Lua).
“А теперь – Горбатый!..”
А теперь ГЛАВНОЕ – об API-функционале (как уже говорилось – это “функции-обёртки” над Lua). Ниже будем использовать стандартный синтаксис описания Lua-вызовов.
Первым делом необходимо создать ЯПФ по ИГА-файлу, это достигается вызовами CreateTiersByEdges и CreateTiersByEdges_Bottom (первый создаёт ЯПФ в “верхнем” варианте, второй – в “нижнем”, единственным формальным параметром является имя gv-файла):
boolean CreateTiersByEdges(string FileName)
boolean CreateTiersByEdges_Bottom(string FileName)
Чтобы узнать общее число ярусов в ЯПФ графа и число операторов по ярусам, можно использовать информационные функции GetCountTiers и GetCointOpsOnTier (формальный параметр функции Tier задаёт номер яруса, причём счёт ярусов начинает с 1 – нулевым считает ярус входных параметров):
integer GetCountTiers()
integer GetCountOpsOnTier(integer Tier)
Перемещение оператора (с проверкой допусти́мости перемещения) осуществляется API-вызовом:
integer MoveOpTierToTier (integer Op, integer Tier)
где Op и Tier – номера переносимого оператора и целевого яруса, при неудаче возвращается число <0.
Допустима перестановка (свопинг) операторов местами (Op1 и Op2 – свопи́руемые операторы):
integer SwapOpsTierToTier(integer Op1, integer Op2)
Перед свершением подобных операций весьма полезно использовать API-вызовы, дающие информацию о допустимых пределах расположения данного оператора Op по ярусам ЯПФ (вызовы GetMaxTierMaybeOp и GetMinTierMaybeOp возвращают номер максимального и минимального ярусов соответственно) :
integer GetMaxTierMaybeOp (integer Op)
integer GetMinTierMaybeOp (integer Op)
Вызовы DelTier и AddTier удаляют (непременно пустой) и добавляют (ниже текущего) ярус Tier соответственно:
integer DelTier (integer Tier)
integer AddTier (integer Tier)
В рамках данной работы предложено вычислительную сложность преобразования ЯПФ путём (эквивалентных – не нарушающих информационные связи в алгоритмах) перемещения операторов между ярусами оценивать в количестве перемещений (аналогично методу оценки трудоёмкости при сортировке одномерных массивов). Этому служат API-вызовы:
integer CountMovesZeroing()
integer GetOpsMoves()
первый из которых принудительно обнуляет счётчик перемещений, а второй возвращает текущее значение счётчика (счётчик инкрементируется при каждом акте перемещения).
- На основе выданной информации Читатель, уверен, уже понял основные принципы работы (и ознакомился с некоторыми механизмам реализации) использования Lua-вызовов для целенаправленной модификации ЯПФ. Дополню, что набора API-вызовов достаточно практически для любых (обслуживание ЯПФ является частым случаем) манипуляций (преобразований) с ИГА (Информационным Графом Алгоритма).
Я хочу задать вопрос Читателю – как он относится к самой идее целенаправленной модификации ЯПФ (Ярусно-Параллельной Формы) алгоритма методом автоматизации с использования скриптового языка? Какие преимущества в этом подходе он видит и какие недостатки усматривает? Перспективен ли такой подход к решению проблемы?
Кстати, совсем необязательно использовать API-вызовы явного создания ЯПФ CreateTiersByEdges() / CreateTiersByEdges_Bottom() – имеющийся набор API-функций позволяет реализовать это непосредственно (правда, получится очень громо́здко). Используя Lua-функции обратного вызова, нет проблем и в программной реализации Data-Flow – машины (см. публикацию #010).
Дополнительно попрактиковаться в изучении API-вызовов языка Lua можно на основе анализа многочисленных файлов согласно шаблону test_*.lua, выгружа́емых при инсталляции ПРАКТИКУМА SPF.
Минимизация числа перемещений операторов с яруса на ярус ЯПФ (зависимость от формы огибающей ЯПФ)
Ранее указывалось, что возможно построение ЯПФ в “верхней” и “нижней” формах - ЯПФ(в) и ЯПФ(н) соответственно. Один из вопросов минимизации вычислительной трудоёмкости целенаправленных преобразований ЯПФ – начиная с какого исходного состояния (оба соответствуют условию неограниченного параллелизма) начинать преобразования, соответствующие минимуму вычислительной трудоёмкости (числу элементарных шагов по перемещению операторов с яруса на ярус)?
На миниатюре ниже приведены характерные формы огибающих ЯПФ (шириной W и высотой H каждая, причём выполнение параллельной программы происходит “сверху вниз”).
Процесс “сгла́живания” ширин ЯПФ при целенаправленных преобразованиях обычно характеризуется ме́ньшей трудоемкостью при бо́льшей начальной ширине ЯПФ (перемещения операторов преимущественно напра́влены “вниз”), при бо́льшей ширине ЯПФ в нижней части перемещения главным образом напра́влены “вверх”.
Нестандартные случаи распараллеливания (генерация простых чисел)
Во многих случаях ЯПФ (более/менее успешно) модифицируются этими методами. Но алгоритмов огромное количестве и всегда есть вероятность встретить “нечто необычное”. Таким алгоритмом выступает генерация последовательности просты́х чисел (не автору объяснять Исследователю важность этого де́йства). Кстати, гипот́еза Ри́мана (1859, первая из 6-ти нерешённых до сих пор задач согласно “списку Ги́льберта”) считается не доказанной до сих пор..!
Публикациям вроде этой (и тут же) мы верим с осторожностию. Тест на простоту́ любого заданного числа известен. Cпособы нахождения начального списка простых чисел вплоть до некоторого значения – решето Эратосфена, решето Сундарама, решето Аткина. Т.к. априорного предсказания повторя́емости простых чисел нет, чаще всего встречается вариант последовательной проверки каждого заданного числа на простоту́ (модификаций сокращения числа прове́рок множество); характерно, что решение подобных задач сильно отличается для параллельных архитектур с общей и локальной памятями.
“Решето” предполагает постепенное “отсе́ивание” (фильтрацию) чисел по некоторому принципу; в результате остаётся единственное N-е по порядку найденных число. Проблема здесь в необходимости проведения расчётов обязательно с минимума (1 или 2) до заданного числа M. Проблема эта заключается в многократном дублировании действий для каждого заданного M (избыточность операций).
Без учёта избыточности достаточно принять размер гранулы параллелизма равной размеру самой программу (схема параллелизации, близкая к рис. 36 в публикации #018); это естественный приём, когда априори почти ничего неизвестно о потенциале параллелизма программы При этом каждый вычислительный узел из среднего яруса (в данном случае 1÷100) выполняет последовательно гранулы с шагом P (число работающих – “slave” - узлов); решение о включении числа M в список простых принимается соответствующим “slave”-процессом. Номер тестируемого числа M рассылается нулевым “master”-узлом, список найденных простых чисел собирается узлом 1000. Конечно, придётся обдумать проблемы барьерной синхронизации (время выполнения процессов на каждом вычислительном узле будет значительно отличаться). Почти точно можно ускорить выполнение общей задачи путём использования некоей априорной информации об исключении определённых комбинаций чисел M и N.
Проблема избыточности операций остаётся и сильно замедлит выполнение общей задачи. Пока автору для её решения не приходит ничего лучше использования метода бинарной сериализации (см., напр., здесь) - процесса сохранения/восстановления мгновенного состояния программы и данных. Огромный недостаток предложенного метода заключается в избыточности операций, она сильно замедлит выполнение общей задачи. Пока автору для её решения не приходит ничего лучше использования метода бинарной сериализации (см., напр., здесь) - процесса сохранения/восстановления мгновенного состояния программы и данных.
- Это, конечно, сугубо наивный метод (даже с учётом перебо́ра чисел с шагом 2) и годится сугубо для нулевого приближе́ния. Поиск в Сети привёл к таким вот результатам (множество ссылок). Интересно, что на́йдено много вариантов распараллеливания “решета Эратосфена” и почти нет примеров распараллеливания иных методов…
Кстати, мне очень нравится вторая часть названия книги И.Е.Федотова (дополнительно здесь) - Параллельное программирование. Модели и приёмы. Среди расшифровок термина “приём” встречаются и такие – “уло́вка”, “мане́вр”, “хитрость”… что-ж, и такое для решения вопроса допусти́мо..!
● На этом примере видно, как важно не формально подходи́ть к процессу параллелизации, а учитывать конкретные закономерности, свойственные каждому алгоритму (их, конечно, необходимо знать). Далее (публикация #018) показано, как использовать для распараллеливания априорно известные структурные свойства конкретных алгоритмов.