В настоящее время, когда финансовые технологии развиваются стремительными темпами, вопрос оценки кредитного риска становится все более актуальным. Точное определение рисков, связанных с выдачей кредитов, является важным аспектом для финансовых учреждений и заемщиков. Традиционные методы, основанные на статистических моделях и экспертных знаниях, сегодня дополняются современными методами машинного обучения.
В данной статье мы представляем сравнительный анализ двух подходов к оценке кредитного риска: экспертной системы с базой знаний и нейронной сети. Эти методы, хотя и отличаются по своей природе, имеют общую цель - помочь финансовым институтам принимать обоснованные решения о выдаче кредитов.
Методология экспертной системы на основе знаний для оценки кредитного риска
Экспертная система на базе знаний (ЭСБЗ) для оценки кредитного риска разработана с целью воссоздания процесса принятия решений финансовым экспертом. Она использует накопленные знания об условиях кредитования, финансовых показателях заемщика и других факторах для определения уровня риска выдачи кредита. ЭСБЗ основана на базе знаний, содержащей правила в формате "если-то", где каждое правило определяет взаимосвязь между различными факторами и уровнем риска.
Процесс реализации ЭСБЗ включает следующие шаги:
- Сбор экспертных знаний: Эксперты в области финансов и кредитования предоставляют информацию о факторах, влияющих на кредитный риск, и правилах, используемых для его оценки.
- Формализация знаний: Собранные знания переводятся в логические правила, понятные компьютеру. Это включает определение условий, при которых каждое правило применяется, и связанных с ними уровней риска.
- Реализация системы: Создается программный модуль, реализующий логику принятия решений на основе собранных экспертных знаний. Этот модуль обрабатывает входные данные о заемщике и выдает прогнозный уровень кредитного риска.
- Тестирование и оптимизация: Система тестируется на различных наборах данных, чтобы проверить её точность и эффективность. При необходимости правила и условия могут быть отрегулированы для улучшения качества прогнозов.
- Внедрение и поддержка: После успешного завершения тестирования система внедряется в рабочее окружение. Обеспечивается её поддержка и обновление для поддержания актуальности и эффективности в течение времени.
Преимущества ЭСБЗ:
- Точность и надежность: Система использует четко определенные правила для оценки риска, что позволяет достичь высокой точности и надежности прогнозов.
- Прозрачность процесса: Логика принятия решений в ЭСБЗ легко понятна и объяснима, что делает её предпочтительной для использования в ситуациях, где важна прозрачность процесса.
- Легкость обновления: Обновление базы знаний и правил системы может быть выполнено без необходимости переобучения, что обеспечивает её легкость обновления и поддержки.
Недостатки ЭСБЗ:
- Ограниченность знаний: Система оценивает риск на основе заранее определенных правил, что может привести к недостаточной гибкости в обработке нестандартных ситуаций.
- Трудоемкость подготовки: Создание и поддержка актуальности базы знаний требует значительных усилий и времени от экспертов.
- Гибкость: ЭСБЗ менее гибка в обработке нечетких, неполных или противоречивых данных по сравнению с нейронными сетями, которые могут обучаться на данных и адаптироваться к новым условиям.
Экспертная система на основе знаний для оценки кредитного риска является мощным инструментом для финансовых учреждений, помогая им принимать обоснованные решения о предоставлении кредитов и управлении рисками.
Методология экспертной системы на основе нейронных сетей для оценки кредитного риска
Экспертная система на основе нейронных сетей (ЭСНН) для оценки кредитного риска применяется для анализа больших объемов данных о заемщиках и предсказания вероятности невозврата кредита. Этот подход использует алгоритмы машинного обучения, особенно нейронные сети, для обучения на исторических данных о кредитах и принятия решений на основе выявленных закономерностей.
Процесс реализации ЭСНН:
- Сбор и подготовка данных: Начинается с сбора данных о заемщиках, включая их кредитную историю, доходы, занятость, возраст и другие финансовые показатели. Эти данные подвергаются очистке, преобразованию и подготовке для обучения нейронной сети.
- Разработка архитектуры нейронной сети: Определяется структура и параметры нейронной сети, включая количество слоев, количество нейронов в каждом слое, а также выбор функций активации и оптимизаторов.
- Обучение нейронной сети: На этом этапе проводится обучение нейронной сети на подготовленных данных. Процесс обучения включает в себя подачу данных на вход нейронной сети, вычисление выходных значений и коррекцию весовых коэффициентов с целью минимизации ошибки предсказания.
- Оценка производительности: После завершения обучения производится оценка производительности нейронной сети на отдельном наборе данных для проверки её точности и обобщающей способности.
- Внедрение и использование: После успешного обучения и проверки нейронная сеть готова к использованию для предсказания кредитного риска на новых данных о заемщиках.
Преимущества ЭСНН:
- Гибкость и адаптивность: Нейронные сети способны обучаться на больших объемах данных и адаптироваться к новым ситуациям, что делает их эффективным инструментом для оценки кредитного риска в различных условиях.
- Способность к обработке нечетких данных: ЭСНН могут обрабатывать нечеткую, неполную или сложную для интерпретации информацию о заемщиках и их финансовом положении.
- Масштабируемость: Нейронные сети легко масштабируются и могут обрабатывать большие объемы данных без значительного увеличения затрат на обслуживание.
Недостатки ЭСНН по сравнению с ЭС на основе знаний:
- Непрозрачность процесса принятия решений: Нейронные сети обладают "черным ящиком" природой, что делает сложным понимание принципов и логики, на основе которых принимаются решения.
- Затраты на обучение: Для достижения высокой точности предсказаний нейронная сеть требует больших объемов данных и вычислительных ресурсов для обучения.
- Риск переобучения: Существует риск переобучения, когда нейронная сеть "запоминает" шум в данных вместо выявления реальных закономерностей, что может привести к снижению точности предсказаний на новых данных.
Методология экспертной системы на основе нейронных сетей (ЭСНН)
Методология экспертной системы на основе нейронных сетей (ЭСНН) для оценки кредитного риска представляет собой инновационный подход, использующий алгоритмы машинного обучения, в частности, нейронные сети. Ниже представлена методология разработки и применения ЭСНН для анализа кредитного риска:
Сбор данных: Процесс начинается с сбора обширного объема данных, включающего информацию о заемщиках, такую как кредитная история, доход, занятость, возраст, наличие обеспечения и т. д. Эти данные позволяют системе выявить закономерности и тенденции, связанные с кредитным риском.
- Подготовка данных: Полученные данные подвергаются предварительной обработке, включая очистку от выбросов, заполнение пропущенных значений и масштабирование при необходимости. Это позволяет улучшить качество обучения нейронной сети.
- Разработка архитектуры нейронной сети: На основе подготовленных данных проектируется архитектура нейронной сети, определяющая количество слоев, количество нейронов в каждом слое, функции активации и другие параметры. Тщательный анализ и выбор архитектуры играют ключевую роль в достижении высокой точности предсказаний.
- Обучение нейронной сети: С использованием обучающего набора данных нейронная сеть обучается находить зависимости между входными признаками и целевой переменной - категорией кредитного риска. Этот процесс осуществляется с помощью алгоритмов обратного распространения ошибки, где веса нейронной сети постепенно корректируются для минимизации ошибки предсказания.
- Оценка качества модели: После завершения обучения модель оценивается на тестовом наборе данных для проверки ее способности к обобщению на новые данные. Важными метриками качества являются точность, полнота, F1-мера и матрица ошибок.
- Внедрение и эксплуатация: После успешной оценки качества модель готова к внедрению в рабочее окружение. Это может включать в себя интеграцию с существующими системами управления кредитным портфелем и автоматизацию процессов принятия решений о выдаче кредитов.
Преимущества ЭСНН:
- Гибкость и адаптивность: Нейронные сети способны обучаться на больших объемах данных и адаптироваться к изменениям во входных данных, что позволяет им эффективно моделировать сложные зависимости в данных о кредитном риске.
- Обработка нечетких данных: Нейронные сети могут работать с нечеткой и сложной для интерпретации информацией, что делает их эффективным инструментом для анализа данных о кредитном риске.
- Масштабируемость: ЭСНН легко масштабируются для работы с большими объемами данных, что делает их подходящими для использования в крупных финансовых институтах.
Недостатки ЭСНН:
- Непрозрачность принятия решений: Нейронные сети обычно работают как "черный ящик", что затрудняет понимание причинно-следственных связей, влияющих на прогнозы о кредитном риске.
- Затраты на обучение: Обучение нейронной сети требует значительных вычислительных ресурсов и времени, особенно при использовании больших объемов данных.
- Риск переобучения: Существует опасность, что нейронная сеть может "запомнить" шум в данных, что может привести к ухудшению ее способности к обобщению на новые данные.
Сравнение
При выборе между экспертной системой на базе знаний и экспертной системой на основе нейронных сетей стоит учитывать ряд ключевых факторов, таких как цель применения, доступность данных для обучения, необходимость в интерпретируемости результатов и ограничения по ресурсам. Экспертные системы на базе знаний идеально подходят для задач, где требуется высокая степень точности и прозрачности в принятии решений, а также в ситуациях, когда доступен ограниченный объем данных. Они позволяют легко обновлять и модифицировать базу знаний по мере поступления новой информации. С другой стороны, экспертные системы на основе нейронных сетей превосходят в обработке больших и сложных наборов данных, обладают способностью обучаться на примерах и могут выявлять скрытые закономерности, недоступные при использовании традиционных подходов. Однако они требуют значительных вычислительных ресурсов для обучения и могут представлять трудности в интерпретации результатов. Таким образом, выбор между этими двумя подходами должен опираться на специфические потребности и условия задачи, стоящей перед исследователями или практиками.
Реализация ЭС на базе знаний
Файл expert_system.py
import pandas as pd
import numpy as np
import time
# Функция экспертной системы для оценки кредитного риска
def evaluate_credit_risk(credit_history, income, employment, age):
risk_level = None
reasons = []
# Правила для кредитной истории
if credit_history == 'хорошая':
reasons.append('Отличная кредитная история снижает риск.')
risk_level = 'низкий'
elif credit_history == 'удовлетворительная':
reasons.append('Удовлетворительная кредитная история может снизить риск.')
risk_level = 'средний'
elif credit_history == 'плохая':
reasons.append('Плохая кредитная история увеличивает риск.')
risk_level = 'высокий'
# Правила для дохода
if income == 'высокий':
reasons.append('Высокий доход снижает риск.')
if risk_level == 'средний':
risk_level = 'низкий'
elif risk_level == 'высокий':
risk_level = 'средний'
elif income == 'низкий':
reasons.append('Низкий доход увеличивает риск.')
if risk_level == 'средний':
risk_level = 'высокий'
elif risk_level == 'низкий':
risk_level = 'высокий'
# Правила для занятости
if employment == 'постоянная':
reasons.append('Постоянная занятость может снизить риск.')
if risk_level == 'высокий':
risk_level = 'средний'
elif employment == 'временная':
reasons.append('Временная занятость может повысить риск.')
if risk_level == 'низкий':
risk_level = 'средний'
elif employment == 'безработный':
reasons.append('Безработный имеет высокий риск.')
risk_level = 'высокий'
# Правила для возраста
if age < 32 or age >= 50:
reasons.append('Молодой возраст или старший возраст могут немного повысить риск.')
if risk_level == 'низкий':
risk_level = 'средний'
elif risk_level == 'средний':
risk_level = 'высокий'
elif 32 <= age < 50:
reasons.append('Средний возраст.')
return risk_level, reasons
def interactive_test():
print("\nТестирование экспертной системы по оценке кредитного риска:\n")
credit_history = input("Какова ваша кредитная история? (хорошая/удовлетворительная/плохая): \n")
income = input("\nКаков ваш доход? (высокий/средний/низкий): \n")
employment = input("\nКакова ваша занятость? (постоянная/временная/безработный): \n")
age = int(input("\nСколько вам лет?: \n"))
result = evaluate_credit_risk(credit_history, income, employment, age)
if result is None:
print("Недостаточно информации для определения риска кредитования.")
return
risk_level, reasons = result
print(f"\nОценка вашего кредитного риска: {risk_level}\n")
print("Причины:\n")
for reason in reasons:
print(reason)
def generate_and_save_test_data(test_data, num_samples=1000):
data = {
"credit_history": np.random.choice(["хорошая", "удовлетворительная", "плохая"], num_samples),
"income": np.random.choice(["высокий", "средний", "низкий"], num_samples),
"employment": np.random.choice(["постоянная", "временная", "безработный"], num_samples),
"age": np.random.randint(0, 131, num_samples)
}
df = pd.DataFrame(data)
df.to_csv(test_data, index=False)
print(f"\nТестовые данные сохранены в файл {test_data}")
def load_data_and_test(test_data, result_expert):
df = pd.read_csv(test_data)
start_time = time.time()
with open(result_expert, 'w') as f:
f.write("Тестирование экспертной системы по оценке кредитного риска:\n")
for i, (_, row) in enumerate(df.iterrows(), 1):
f.write(f"Тест {i+1}:\n")
f.write(f"Кредитная история: {row['credit_history']}\n")
f.write(f"Доход: {row['income']}\n")
f.write(f"Занятость: {row['employment']}\n")
f.write(f"Возраст: {row['age']}\n\n")
result = evaluate_credit_risk(row['credit_history'], row['income'], row['employment'], row['age'])
if result is None:
f.write("Недостаточно информации для определения риска кредитования.\n\n")
continue
predicted_risk, reasons = result
f.write(f"Предсказанный риск: {predicted_risk}\n")
f.write("Причины:\n")
if isinstance(reasons, list):
for reason in reasons:
f.write(f"- {reason}\n")
else:
f.write(f"- {reasons}\n")
f.write("-" * 50 + "\n\n")
elapsed_time = time.time() - start_time
print(f"\nРезультаты тестов сохранены в файл {result_expert}.\n")
print(f"Всего тестов: {len(df)}, Время выполнения: {elapsed_time:.2f} секунд.\n")
if __name__ == "__main__":
interactive_test()
generate_and_save_test_data('test_data.csv')
load_data_and_test('test_data.csv', 'result_expert.txt')
Реализация нейронной сети на основе Экспертной системы.
Обучение нейронной сети, составление датасета
Файл neiroobych.py
import pandas as pd
import random
# Function to simulate the expert system's risk evaluation using a neural network
def simulate_expert_system(credit_history, income, employment, age):
risk_level = None
# Правила для кредитной истории
if credit_history == 'хорошая':
risk_level = 'низкий'
elif credit_history == 'удовлетворительная':
risk_level = 'средний'
elif credit_history == 'плохая':
risk_level = 'высокий'
# Правила для дохода
if income == 'высокий':
if risk_level == 'средний':
risk_level = 'низкий'
elif risk_level == 'высокий':
risk_level = 'средний'
elif income == 'низкий':
if risk_level == 'средний':
risk_level = 'высокий'
elif risk_level == 'низкий':
risk_level = 'высокий'
# Правила для занятости
if employment == 'постоянная':
if risk_level == 'высокий':
risk_level = 'средний'
elif employment == 'временная':
if risk_level == 'низкий':
risk_level = 'средний'
elif employment == 'безработный':
risk_level = 'высокий'
# Правила для возраста
if age < 32 or age >= 50:
if risk_level == 'низкий':
risk_level = 'средний'
elif risk_level == 'средний':
risk_level = 'высокий'
return risk_level
# Generating random inputs
def generate_data(num_samples):
data = []
for _ in range(num_samples):
credit_history = random.choice(["хорошая", "удовлетворительная", "плохая"])
income = random.choice(["высокий", "средний", "низкий"])
employment = random.choice(["постоянная", "временная", "безработный"])
age = random.randint(0, 121)
# Evaluate the simulated risk
risk = simulate_expert_system(credit_history, income, employment, age)
data.append([credit_history, income, employment, age, risk])
# Convert to DataFrame and return
return pd.DataFrame(data, columns=["Credit History", "Income", "Employment", "Age", "Risk"])
# Generate 1000 samples
df = generate_data(1000)
# Save the generated data to a CSV file
csv_file_path = 'generated_credit_risk_data.csv'
df.to_csv(csv_file_path, index=False)
csv_file_path
Предобработка данных, Код для Локальной Обработки данных Файл local_data.py
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
# Загрузка данных
data = pd.read_csv('generated_credit_risk_data.csv')
# Подготовка transformers для предобработки данных
column_transformer = ColumnTransformer(
[
('categorical', OneHotEncoder(), ['Credit History', 'Income', 'Employment']),
('numerical', StandardScaler(), ['Age'])
],
remainder='passthrough'
)
# Применение ColumnTransformer
processed_data = column_transformer.fit_transform(data)
processed_data = pd.DataFrame(processed_data, columns=column_transformer.get_feature_names_out())
# Добавляем целевую переменную в обработанные данные
processed_data['Risk'] = data['Risk']
# Разделение данных на фичи и таргет
X = processed_data.drop('Risk', axis=1)
y = processed_data['Risk']
# Разделение на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Сохранение обработанных данных в новый файл для дальнейшего использования
# Удаление ненужного столбца
processed_data.drop(columns=['remainder__Risk'], inplace=True)
processed_data.to_csv('processed_data.csv', index=False)
Код для Нейронной Сети
Файл neural_network.py:
import time
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.optimizers import Adam
from joblib import dump, load
# Загрузка обработанных данных
data = pd.read_csv('processed_data.csv')
# Кодирование целевой переменной (целевая переменная находится в столбце 'Risk')
label_encoder = LabelEncoder()
data['Risk'] = label_encoder.fit_transform(data['Risk'])
# Разделение данных на фичи и таргет
X = data.drop('Risk', axis=1).astype(float) # Преобразование всех входных данных в float
y = data['Risk']
# Разделение на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Создание модели
model = Sequential([
Input(shape=(X_train.shape[1],)), # Входной слой с количеством нейронов, равным количеству признаков
Dense(64, activation='relu'), # Первый скрытый слой с 64 нейронами и функцией активации ReLU
Dense(64, activation='relu'), # Второй скрытый слой с 64 нейронами и функцией активации ReLU
Dense(len(np.unique(y)), activation='softmax') # Выходной слой с функцией активации softmax
])
# Компиляция модели
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Обучение модели
start_time = time.time()
model.fit(X_train, y_train, epochs=200, batch_size=900, verbose=2)
training_time = time.time() - start_time
print(f"Время обучения модели: {training_time:.2f} секунд.")
# Измерение времени предсказания
start_time = time.time()
predictions = model.predict(X_test)
prediction_time = time.time() - start_time
print(f"Время, затраченное на предсказание: {prediction_time:.2f} секунд.")
# Расчет среднего времени на один образец
average_prediction_time_per_sample = prediction_time / len(X_test)
print(f"Среднее время предсказания на один образец: {average_prediction_time_per_sample:.5f} секунд.")
# Оценка модели
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f'Точность модели: {accuracy:.2f}')
# Предсказание рисков для всех данных
predicted_probabilities = model.predict(X)
predicted_risks = np.argmax(predicted_probabilities, axis=1)
# Преобразование числовых предсказаний в строковые метки риска
predicted_risks_labels = label_encoder.inverse_transform(predicted_risks)
# Добавление предсказанных рисков в DataFrame
data['Predicted Risk'] = predicted_risks_labels
data['Risk'] = label_encoder.inverse_transform(data['Risk']) # Возвращаем исходные метки риска
# Сохранение только двух столбцов с метками риска
data[['Risk', 'Predicted Risk']].to_csv('predictions.csv', index=False)
print("Предсказанные риски сохранены в файл predictions.csv")
model.save('save_model.h5')
dump(label_encoder, 'label_encoder.joblib')
Код для уже обученной Нейронной Сети
Файл neural_networkafter.py:
import pandas as pd
from keras.models import load_model
from sklearn.preprocessing import LabelEncoder
# Load the trained model
model = load_model('save_model.h5')
# Load the LabelEncoder
label_encoder = LabelEncoder()
label_encoder = label_encoder.fit(['низкий', 'средний', 'высокий'])
# Load the data for prediction
data_for_prediction = pd.read_csv('processed_data.csv')
# Загрузка данных из исходного файла
generated_data = pd.read_csv('generated_credit_risk_data.csv')
# Remove the target variable from the data for prediction
data_for_prediction_without_target = data_for_prediction.drop(columns=['Risk'])
# Predict the risk
predicted_risks = model.predict(data_for_prediction_without_target)
# Inverse transform the predicted risks
predicted_risks_labels = label_encoder.inverse_transform(predicted_risks.argmax(axis=1))
# Add the predicted risks to the DataFrame
generated_data['Predicted Risk'] = predicted_risks_labels
generated_data.drop(columns=['Risk'], inplace=True)
# Save the data with predicted risks to a new file
generated_data.to_csv('predicted_credit_risk_data.csv', index=False)
Результаты работы экспертной системы
Прохождение опроса в экспертной системе:
Тестирование экспертной системы по оценке кредитного риска:
Какова ваша кредитная история? (хорошая/удовлетворительная/плохая):
хорошая
Каков ваш доход? (высокий/средний/низкий):
высокий
Какова ваша занятость? (постоянная/временная/безработный):
постоянная
Сколько вам лет?:
19
Оценка вашего кредитного риска: низкий
Причины:
Отличная кредитная история снижает риск.
Высокий доход снижает риск.
Постоянная занятость может снизить риск.
Средний возраст.
Тестовые данные сохранены в файл test_data.csv
Результаты тестов сохранены в файл result_expert.txt.
Всего тестов: 1000, Время выполнения: 0.08 секунд.
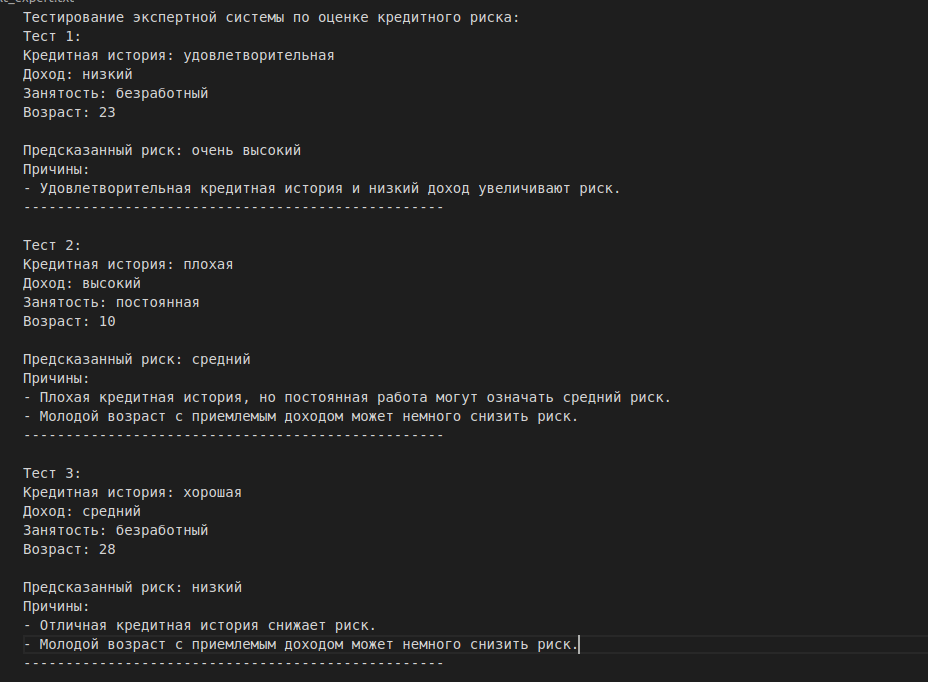
Прохождение опроса, но уже в сгенерированном случайном датасете на 1000 входных данных:
Пример файла result_expert.txt
Пример файла test.data.cvk датасета (входных данных)экспертной системы:
Результат работы нейронной сети:
Пример работы файла neural_network.py
Пример файла generated_credit_risk_data.cvk датасета (входных данных) нейронной сети:
Пример файла processed_data.cvk датасета (входных данных) нейронной сети после локальной обработки:
Пример файла prediction.cvk
Классы "Risk" (фактический риск) и "Predicted Risk" (прогнозируемый риск) представляют собой фактический риск из исходных данных и прогнозируемый риск нейронной сети после обучения соответственно.
Пример работы уже обученной модели neural_networkafter.py на новых данных. Пример файла predicted_credit_risk_data.csv
Вывод
В ходе работы была реализована экспертная система с базой знаний на языке Python на тему "Оценка кредитного риска". Разработана нейронная сеть с 4(четырмя) слоями(входном, первым скрытом, втором скрытом и выходном) на основе экспертной системы на языке Python. Как мы видим после 200 эпохи обучения и размере получения данных для обучения 900 во входном датасете, состоящим из 1000 тестовых данных точность нейронной сети составила 0.95. Время обучения нейронной сети составило 4,37с. Время на предсказание на 1000 тестовых данных составило 0.09с. Время работы экспертной системы составило 0.08с, что в 1,125 раза(либо же на 11%) быстрее работы нейронной сети. Точность экспертной системы равна 1.00(что на 5 % лучше нейронной сети). Моя экспертная система позволяет увидеть причины получения нужного результата, в то время как нейронная сеть такого себе позволить не может.
Заключение
В настоящей статье мы проанализировали два различных подхода к оценке кредитного риска и сравнили их эффективность: экспертную систему на базе знаний (ЭСБЗ) и экспертную систему на основе нейронных сетей (ЭСНН) (PS. правила, используемые в программе в реальности не используются). Основываясь на изучении точности прогнозов, скорости выполнения анализа, гибкости, масштабируемости, прозрачности и интерпретируемости, мы выявили, что каждый из этих методов имеет свои сильные и слабые стороны, что делает их более или менее подходящими для различных сценариев кредитного анализа.
Экспертная система на базе знаний демонстрирует высокую точность и быструю реакцию при наличии четко определенных правил и условий, что делает ее надежным инструментом для оценки кредитного риска в ситуациях, где все возможные сценарии и решения могут быть заранее определены и включены в базу знаний. Это особенно ценно в стабильных и контролируемых средах.
С другой стороны, экспертная система на основе нейронных сетей обладает значительной гибкостью и способностью адаптироваться к новым, ранее неизвестным условиям благодаря обучению на разнообразных данных. Хотя ЭСНН может иногда допускать ошибки и требует времени для обучения модели, она предлагает мощный потенциал для идентификации и оценки широкого спектра кредитных рисков, особенно в динамичных или нестандартных ситуациях.
В конечном итоге выбор между ЭСБЗ и ЭСНН должен зависеть от конкретных потребностей и условий их использования. Для ситуаций, требующих высокой точности и надежности при наличии четко определенных сценариев кредитного анализа, ЭСБЗ может быть предпочтительнее. В контексте, где требуется гибкость и способность адаптироваться к новым и меняющимся условиям, ЭСНН предложит более эффективное решение, несмотря на возможные ошибки.
В заключение, обе системы представляют значительный интерес для финансовой отрасли, предлагая инструменты для улучшения качества кредитного анализа и принятия решений. Дальнейшие исследования и разработки в этой области могут привести к созданию более совершенных систем, которые будут сочетать в себе преимущества обеих подходов, предлагая еще более точные и гибкие решения для анализа кредитного риска.