В материале:
рассмотрена модель простой нейронной сети, в текущем материале рассмотрим многослойную нейронную сеть для того, чтобы изучить отличия между дискретными и непрерывными данными при работе с многослойной нейронной сетью.
Напомним, что дискретными данными называются данные, число которых конечно или бесконечно, но может быть подсчитано при помощи множества натуральных чисел (пронумерованы). Непрерывными данными называются данные, которые могут принимать любые значения в некотором интервале, потому непрерывные переменные не поддаются подсчету, однако над непрерывными данными можно проводить арифметические операции.
В таблице ниже представлено, какой вид данных можно использовать при каждом типе данных:
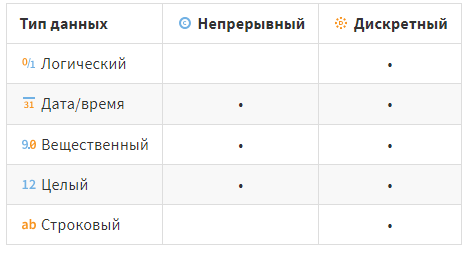
При работе с простой нейронной сетью можно было заметить, что при импорте данных все числовые поля по умолчанию импортируются как непрерывные, в то время как строковые данные, разумеется, могут быть только дискретными. Однако такое деление «дискретные-непрерывные» в контексте искусственных нейронных сетей имеет свои особенности.
Выполним два задания.
Задание 1.
Подготовьте файл с данными:

Для удобства приведём команду, которую необходимо ввести в ячейку:
=ЕСЛИ(A2<-6;1;(ЕСЛИ((A2>=-6)*И(A2<-2);2;(ЕСЛИ((A2>=-2)*И(A2<2);3;(ЕСЛИ((A2>=2)*И(A2<=6);4;(ЕСЛИ(A2>6;5;0))))))))).
Обучение нейронной сети на непрерывных выходных данных:
Непрерывность выходных данных означает, что выходной сигнал может быть любым, и не обязательно окажется целочисленным номером интервала.
Для непрерывных значений процент распознавания будет определяться как доля значений, ошибка распознавания для которых менее некоторой величины (по умолчанию 0,05).
Постройте и обучите следующую нейронную сеть:
Зафиксируйте: Сколько нейронов понадобилось для обучения? Сколько выходных нейронов вы видите на графе нейросети? Сколько процентов распознано? Какие значения обучения (обучающее множество, тестовое множество)?
Прежде всего, нужно разобраться в том, как вычисляется ошибка обучения.
Во-первых, это квадратичная ошибка.
Во-вторых, ошибка вычисляется не на исходных, а на нормированных значениях – иначе она будет сильно зависеть от порядка величин.
Поскольку выходные данные представляют собой последовательный ряд целых чисел, то очевидно, что распознавание можно считать верным тогда, когда выходной сигнал отличается от ожидаемого значения менее чем на 0,5.
Нормирование данных происходит на интервале [0, 1], причем ноль будет соответствовать минимальному значению В (1), а единица – максимальному (5). Таким образом, 0,5 составляет 1/8 нормированного единичного отрезка.
Квадрат такой ошибки составляет 1/64 или 0,015625.
Именно такую величину необходимо указать в поле «Считать пример распознанным, если ошибка меньше» на шаге «Настройка параметров остановки обучения» настройки нейронной сети. Тогда процент распознавания будет показывать долю образцов, для которых абсолютное отклонение не превышает 0,5.
Проверьте результаты обучения по диаграмме на вкладке инструмента «Что-Если». Вы увидите, что кривой зависимости свойственна некоторая сигмоидальность, то есть зависимость является нелинейной, а выходные значения – непрерывными. Однако округленное значение выходного сигнала в большинстве случаев соответствуют ожидаемым.
Обучение нейронной сети на дискретных выходных данных:
Теперь попробуйте повторить обучение с теми же параметрами, но определив выходные значения как дискретные (для этого потребуется вновь импортировать данные).
Так же, как и в предыдущем случае, установите всего лишь один нейрон в скрытом слое. Проведите обучение при тех же параметрах.
Прежде всего, обратите внимание на граф нейронной сети. Вы увидите, что теперь в сети не один, а три выходных нейрона.
Зафиксируйте: Сколько нейронов понадобилось для обучения? Сколько выходных нейронов вы видите на графе нейросети? Сколько процентов распознано? Какие значения обучения (обучающее множество, тестовое множество)?
Продолжите обучение, увеличивая число нейронов в скрытом слое. При каком числе нейронов качество обучения приблизится к качеству обучения, достигнутому для непрерывных выходных данных?
Задание 2.
Для удобства укажем команду, которую необходимо поместить в ячейку файла:
=ЕСЛИ(((A2<=0)*И(A2>-5))*И((B2>=0)*И(B2<5));1;(ЕСЛИ(((A2>=0)*И(A2<5))*И((B2>=0)*И(B2<5));2;(ЕСЛИ(((A2>=0)*И(A2<5))*И((B2<=0)*И(B2>-5));3;(ЕСЛИ(((A2<=0)*И(A2>-5))*И((B2<=0)*И(B2>-5));4;(ЕСЛИ(((A2<=-5)*И(A2>=-10))*И((B2<=0)*И(B2>=-5));5;(ЕСЛИ(((A2<=-5)*И(A2>=-10))*И((B2>=0)*И(B2<5));6;(ЕСЛИ(((A2<=-5)*И(A2>=-10))*И((B2>=5)*И(B2<=10));7;(ЕСЛИ(((A2<=0)*И(A2>-5))*И((B2>=5)*И(B2<=10));8;(ЕСЛИ(((A2<5)*И(A2>=0))*И((B2>=0)*И(B2<=10));9;(ЕСЛИ(((A2<=10)*И(A2>=5))*И((B2>=5)*И(B2<=10));10;(ЕСЛИ(((A2<=10)*И(A2>=5))*И((B2>=0)*И(B2<=10));11;(ЕСЛИ(((A2<=10)*И(A2>=5))*И((B2<=0)*И(B2>=-5));12;(ЕСЛИ(((A2<=10)*И(A2>=5))*И((B2<=-5)*И(B2>=-10));13;(ЕСЛИ(((A2<5)*И(A2>=0))*И((B2<=-5)*И(B2>=-10));14;(ЕСЛИ(((A2>-5)*И(A2<=0))*И((B2<=-5)*И(B2>=-10));15;(ЕСЛИ(((A2>=-10)*И(A2<=-5))*И((B2<=-5)*И(B2>=-10));16;0))))))))))))))))))))))))))))))).
Обучение нейронной сети на дискретных выходных данных:
Зафиксируйте: Сколько нейронов понадобилось для обучения? Сколько выходных нейронов вы видите на графе нейросети? Сколько процентов распознано? Какие значения обучения (обучающее множество, тестовое множество)?
Обучение нейронной сети на непрерывные выходные данные:
Для контроля за степенью обучения непосредственно во время прохождения эпох необходимо верно установить значение ошибки в поле «Считать пример распознанным, если ошибка меньше»:
Установите число нейронов в скрытом слое равным минимальному число нейронов, при котором удалось достичь распознавания в 95% в случае с дискретным С.
Проведите обучения, контролируя его результат.
Зафиксируйте: Сколько нейронов понадобилось для обучения? Сколько выходных нейронов вы видите на графе нейросети? Сколько процентов распознано? Какие значения обучения (обучающее множество, тестовое множество)? Удалось ли достичь такого же уровня обучения, как и при дискретном выходе? Насколько обучение сети с непрерывным выходным значением стало лучше или хуже?
Заметим, что, скорее всего, будет наблюдаться значительное ухудшение качества обучения. Картина полностью отличается от той, которая наблюдалась в первой части задания – там, наоборот, непрерывная выходная величина показала значительно лучшие результаты. Однако там дискретные ожидаемые значения были линейно упорядочены, здесь же скорее наоборот, их взаимное расположение в пространстве образцов близко к случайному.
Таким образом, использование непрерывных значений оправдано не только в том случае, когда они являются действительно непрерывными, но и тогда, когда они являются дискретными, но упорядоченными. Дискретные значения, как показало выполнения задания, раскладываются на комбинацию независимых и никак не упорядоченных данных.
Это в равной мере относится и к входным значениям. Например, в задачах определения стоимости недвижимости число комнат в квартире разумно представить как непрерывное значение, хотя оно в действительности, конечно, является дискретным.