So Deep Data
Классификатор деревьев принятия решений (Extremely Randomized Trees Classifier, Extra Trees Classifier) - это разновидность ансамблевого метода обучения, который объединяет результаты множества декоррелированных деревьев принятия решений, собранных в "лес", для вывода результата классификации. По своей концепции он очень похож на классификатор Random Forest и отличается от него только способом построения деревьев решений в лесу. Каждое дерево решений в лесу Extra Trees Forest строится на основе исходной обучающей выборки.
Затем в каждом тестовом узле каждому дереву предоставляется случайная выборка k признаков из набора признаков, из которых каждое дерево решений должно выбрать лучший признак для разбиения данных на основе некоторого математического критерия (обычно индекса Джини).
Такая случайная выборка признаков приводит к созданию множества декоррелированных деревьев решений. Чтобы выполнить отбор признаков с помощью описанной выше структуры леса, при построении леса для каждого признака вычисляется нормированное суммарное сокращение математических критериев, используемых при принятии решения о признаке разбиения (индекс Джини, если при построении леса используется индекс Джини).
Это значение называется важностью признака по Джини. Для выбора признака каждый признак упорядочивается в порядке убывания в соответствии с Джини-важностью каждого признака, и пользователь выбирает k лучших признаков в соответствии со своим выбором.
Импорт библиотек:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import ExtraTreesClassifier
Загрузка и чистка данных:
cd C:\Users\Dev\Desktop\Kaggle
df = pd.read_csv('data.csv')
y = df['Play Tennis']
X = df.drop('Play Tennis', axis = 1)
X.head()
Построение леса дополнительных деревьев и вычисление важности отдельных признаков:
extra_tree_forest = ExtraTreesClassifier(n_estimators = 5,
criterion ='entropy', max_features = 2)
extra_tree_forest.fit(X, y)
feature_importance = extra_tree_forest.feature_importances_
feature_importance_normalized = np.std([tree.feature_importances_ for tree in
extra_tree_forest.estimators_], axis = 0)
Визуализация и сравнение:
plt.bar(X.columns, feature_importance_normalized)
plt.xlabel('Feature Labels')
plt.ylabel('Feature Importances')
plt.title('Comparison of different Feature Importances')
plt.show()
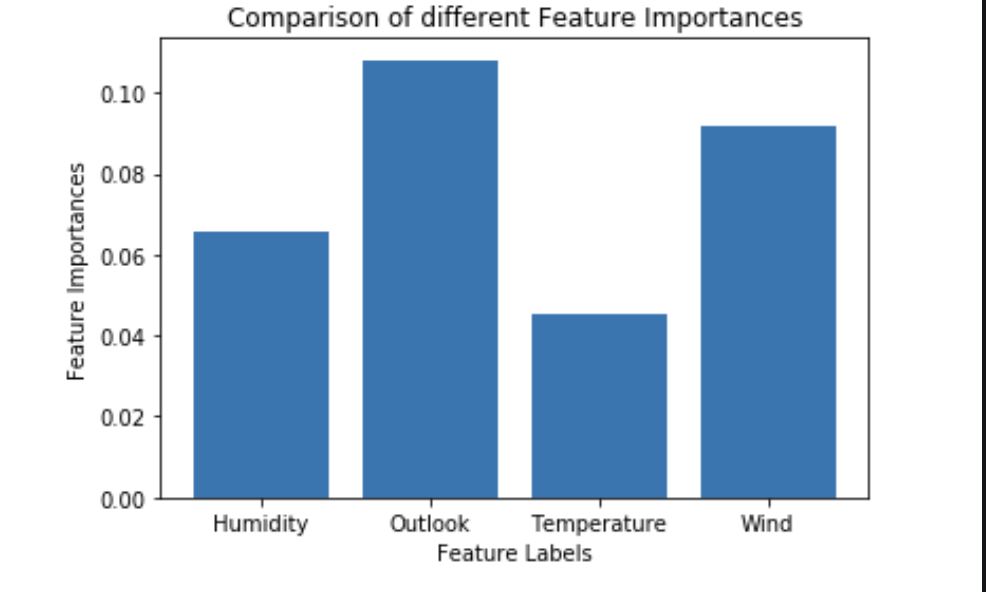
Таким образом, приведенный выше результат подтверждает нашу теорию о выборе признаков с помощью классификатора Extra Trees. Важность признаков может иметь разные значения из-за случайного характера выборок признаков.
Классификатор Extra Trees для отбора признаков предлагает несколько преимуществ:
1. Устойчивость к шуму и неинформативным признакам: Классификатор Extra Trees использует несколько деревьев решений и выбирает признаки на основе их важности, что делает его менее чувствительным к шуму и неинформативным признакам. Он может эффективно обрабатывать наборы данных с большим количеством признаков и зашумленными данными.
2. Вычислительная эффективность: Классификатор Extra Trees строит деревья решений параллельно, что значительно ускоряет процесс обучения по сравнению с другими методами отбора признаков. Он особенно полезен для наборов данных с высокой размерностью, где эффективность играет решающую роль.
3. Снижение смещения: Случайный выбор подмножеств и случайные точки разделения в классификаторе Extra Trees помогают снизить смещение, которое может возникнуть при использовании одного дерева решений. Путем рассмотрения нескольких деревьев решений он обеспечивает более полную оценку важности признаков.
4. Ранжирование признаков: Классификатор Extra Trees присваивает важности каждому признаку, позволяя вам ранжировать их на основе их относительной важности. Это ранжирование может предоставить понимание о релевантности и вкладе каждого признака в целевую переменную.
5. Работа с мультиколлинеарностью: Классификатор Extra Trees эффективно обрабатывает коррелированные признаки. Путем случайного выбора подмножеств признаков и использования случайных разделений он уменьшает влияние мультиколлинеарности, в отличие от методов, основанных на явной корреляции признаков.
6. Гибкость отбора признаков: Процесс отбора признаков в классификаторе Extra Trees основан на важности признаков, что позволяет вам адаптировать порог для включения признаков в соответствии с вашими конкретными потребностями. Вы можете выбрать включить только самые важные признаки или более крупное подмножество в зависимости от желаемого баланса между уменьшением признаков и производительностью модели.
7. Обобщаемость и интерпретируемость: Выбирая подмножество релевантных признаков, классификатор Extra Trees может улучшить обобщение модели, уменьшая переобучение. Кроме того, выбранные признаки могут предоставить интерпретируемые инсайты в факторы, влияющие на прогнозы и целевую переменную.
Эти преимущества делают классификатор Extra Trees ценным инструментом для отбора признаков, особенно при работе с наборами данных высокой размерности, зашумленными данными и в ситуациях, где важна вычислительная эффективность.
Больше в телеграм канале: https://t.me/sodeepdata