Трансформеры возникли из видео карт и кубитах. Теперь кубиты можно делать даже из атомов и молекул..
Одним из ключевых элементов, предложенных в этой статье, является механизм внимания, который позволяет модели фокусироваться на различных частях входных данных в зависимости от их значимости для текущей задачи. Это позволяет трансформерам обрабатывать последовательности данных любой длины, сохраняя контекст и учитывая взаимодействия между элементами последовательности.
Основной принцип работы трансформеров — это механизм самовнимания (self-attention), который позволяет модели учитывать относительную важность каждого элемента входной последовательности при генерации выхода. Этот механизм позволяет трансформерам эффективно обрабатывать длинные последовательности данных, такие как тексты, сохраняя контекст и учитывая долгосрочные зависимости.
Другим важным аспектом трансформеров является параллельная обработка данных благодаря использованию множества слоев внутри модели. Это позволяет трансформерам работать с большими объемами данных более эффективно, что делает их привлекательными для обработки естественного языка и других задач, требующих анализа последовательностей.
Статья "Attention is All You Need" стала отправной точкой для развития трансформеров и их применения в различных областях искусственного интеллекта, включая генерацию текста, машинный перевод, обработку речи, обработку изображений и другие.
Первая статья о трансформерах, "Attention is All You Need" (Внимание - все, что вам нужно), была опубликована исследователями из компании Google AI (Google Brain) в 2017 году. Авторы статьи включают:
- Васвани, Ашиш (Ashish Vaswani)
- Шаза, Ноам (Noam Shazeer)
- Пармар, Никил (Niki Parmar)
- Уски, Якоб (Jakob Uszkoreit)
- Джонс, Ллойд (Llion Jones)
- Гомес, Айдан (Aidan N. Gomez)
- Кайзер, Лука (Łukasz Kaiser)
- Полосукхин, Илларион (Illia Polosukhin)
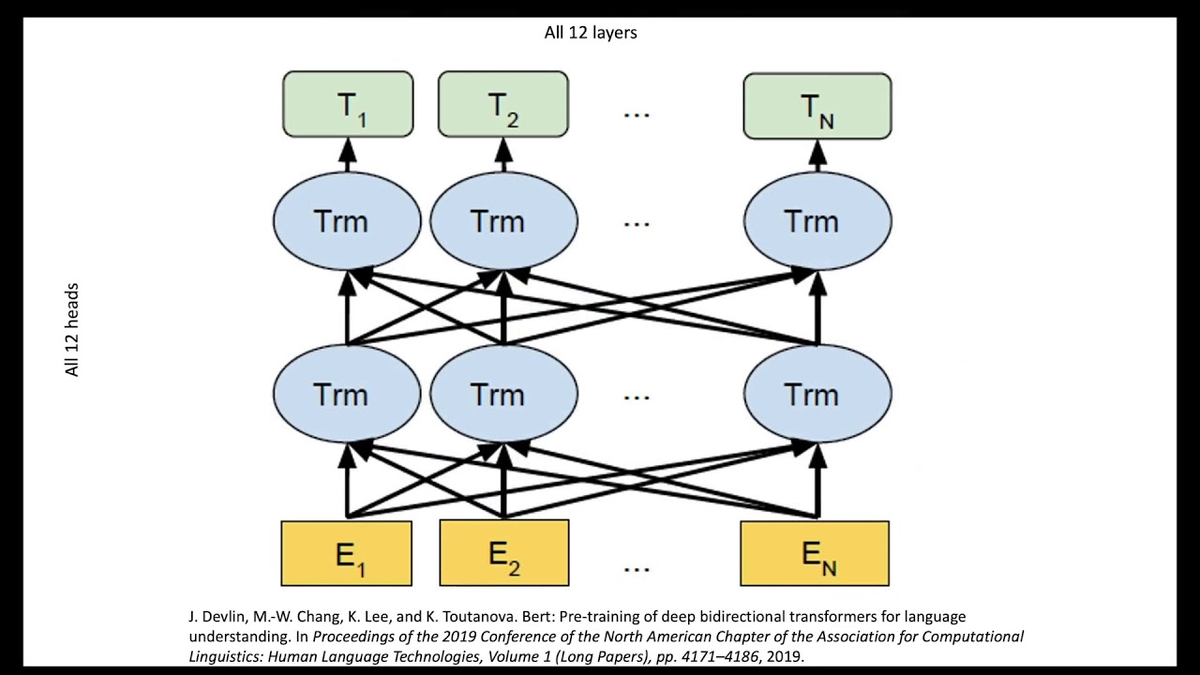
Эта статья представила новую архитектуру нейронной сети — трансформер, которая активно используется в различных моделях обработки естественного языка (NLP), включая модели GPT и BERT. Трансформеры быстро стали популярными благодаря их способности работать с последовательными данными более эффективно, чем предыдущие архитектуры, такие как рекуррентные нейронные сети (RNN).
Исследование и разработка математики моделей типа GPT включает несколько ключевых компонентов:
1. Трансформерная архитектура: Эта архитектура была значительным прорывом в области обработки естественного языка (NLP). В отличие от рекуррентных нейронных сетей (RNN), которые имеют ограничения при работе с длинными последовательностями данных из-за проблемы затухания градиентов, трансформеры используют механизм внимания для эффективной работы с контекстом даже на больших расстояниях в последовательности.
2. Механизм внимания (Attention Mechanism): Этот механизм позволяет модели фокусироваться на различных частях входных данных в зависимости от их значимости для текущей задачи. Он позволяет модели выделить ключевые аспекты входных данных и использовать эту информацию для более эффективного решения задачи.
3. Претренировка на больших объемах данных: Одной из ключевых особенностей GPT и подобных моделей является претренировка на огромных объемах текстовых данных. Это позволяет модели узнавать широкий спектр языковых закономерностей и контекстов, что в конечном итоге повышает её способность генерировать качественный текст.
4. Fine-tuning (настройка) под конкретную задачу: После пре-тренировки модель может быть настроена (fine-tuned) на специфическую задачу, что улучшает её производительность и адаптирует под конкретные потребности пользователей.
Математические основы этих моделей включают в себя операции линейных преобразований, функции активации, расчеты внимания и оптимизации параметров с использованием методов градиентного спуска.
Исследование в этой области проводится сообществом исследователей по машинному обучению и глубокому обучению, и каждый новый шаг в развитии моделей подобного типа учитывает опыт предыдущих исследований, проблемы и пути их решения.
Математика моделей типа GPT основана на различных исследованиях в области машинного обучения и искусственного интеллекта. Основной концепцией лежащей в основе GPT ( Generative Pre-trained Transformer) является трансформерная архитектура, которая была предложена в статье
"Attention is All You Need" (Внимание - все, что вам нужно) исследователями из Google AI в 2017 году.
Эта архитектура представляет собой глубокую нейронную сеть, в которой используется механизм внимания для работы с последовательностями данных. Идея заключается в том, чтобы сфокусироваться на разных частях входных данных в разные моменты времени, что позволяет модели лучше понимать контекст и создавать более качественные прогнозы или генерировать текст.
GPT, разработанный OpenAI, использует эту архитектуру, но добавляет претренировку на огромных объемах текстовых данных для обучения модели на широком спектре языковых задач, таких как генерация текста, вопросно-ответные системы, завершение предложений и другие.
Таким образом, математика, лежащая в основе моделей типа GPT, основана на исследованиях по нейронным сетям, трансформерах и механизмах внимания, а также на практическом опыте в области обработки естественного языка и машинного обучения.
Теория групп в математике изучает алгебраические структуры, которые состоят из множества элементов и определённой операции над этими элементами, обладающей определёнными свойствами. Элементы группы могут быть, например, числами, матрицами или функциями, а операция может быть сложением, умножением или композицией функций.
Основные свойства группы включают ассоциативность операции ( т.е. порядок, в котором выполняются операции, не имеет значения), наличие нейтрального элемента (такого элемента, который не меняет другие элементы при операции с ними) и существование обратного элемента ( каждый элемент имеет обратный элемент, при умножении на который получается нейтральный элемент).
Теория групп широко применяется в различных областях математики, включая алгебру, теорию чисел, геометрию и физику.
В отношении нейросетей, теория групп также имеет своё место.
Например:
Группы симметрии играют важную роль в анализе данных и обработке изображений. Некоторые нейронные сети, такие как свёрточные нейронные сети (CNN), используют идею симметрии для обнаружения образов в данных.
Нейронные сети часто обучаются с использованием алгоритмов оптимизации, которые могут быть представлены в терминах групп.
Например, группы симметрии могут быть использованы для создания эффективных алгоритмов обучения с учителем.
В квантовых вычислениях используются различные математические структуры, включая группы, для описания операций над квантовыми битами (кьюбитами). Это имеет прямое отношение к обучению нейронных сетей с использованием квантовых компьютеров.
Таким образом, теория групп представляет собой мощный инструмент не только в математике, но и в области нейронных сетей и машинного обучения, где она может быть использована для анализа структур данных, оптимизации алгоритмов и разработки новых методов обучения.
Конечно, давайте более подробно рассмотрим, как теория групп связана с нейросетями:
1. Группы симметрии играют важную роль в анализе данных и обработке изображений в нейросетях. Например, в свёрточных нейронных сетях (CNN) используются свойства трансляционной инвариантности, что означает, что сеть способна распознавать объекты на изображениях независимо от их местоположения в кадре. Это достигается благодаря применению операций свёртки и пулинга, которые учитывают локальные свойства изображения, сохраняя инвариантность относительно сдвигов.
2. Групповые операции могут использоваться для преобразования данных в нейросетях. Например, в задачах обработки изображений групповые операции могут включать в себя вращения, масштабирование и сдвиги изображений. Применение таких трансформаций позволяет сети обучаться на разнообразных данных, что способствует её обобщающей способности.
3. Некоторые методы оптимизации, используемые в обучении нейронных сетей, могут быть сформулированы в терминах групповых операций. Например, методы стохастического градиентного спуска могут интерпретироваться как итеративные шаги в пространстве параметров, которые образуют группу операций над параметрами сети.
4. Некоторые модели нейронных сетей могут быть абстрагированы как алгебраические структуры, которые подчиняются определённым групповым законам. Например, рекуррентные нейронные сети (RNN) могут быть интерпретированы как групповые операции, применяемые к последовательностям данных.
Таким образом, теория групп предоставляет концептуальный и математический фреймворк для понимания и анализа работы нейронных сетей, а также для разработки новых методов и алгоритмов обучения. Это помогает улучшить обучение нейронных сетей, повысить их эффективность и обобщающую способность, а также расширить область их применения.
ссылки по теме:
https://ru.wikipedia.org/wiki/Generative_pre-trained_transformer
https://habr.com/ru/companies/ods/articles/716918/
https://dzen.ru/a/X2xtgz6hwXlhdk0U