Сегодня начали делать вместе с моим учеником лабораторную работу на тему "Хэширование данных". Учится он в одном уважаемом СПб-ком техническом вузе, по направлению "Программная инженерия", поэтому и требования к выполнению работы достаточно высокие и интересные. Предлагаю вместе разобрать эту задачу.

Что вообще такое хэширование и где оно применяется можно почитать здесь.
А вот, собственно, и само задание:
Составить хеш-функцию в соответствии с заданным вариантом и проанализировать ее. При необходимости доработать хеш-функцию. Используя полученную хеш-функцию разработать программу, которая должна выполнять следующие функции:
· создавать хеш-таблицу;
· просматривать хеш-таблицу;
· добавлять/удалять элементы в хеш-таблицу;
· искать элементы в хеш-таблице по номеру сегмента/по ключу;
· выгружать содержимое хеш-таблицы в файл для построения гистограмм;
· при удалении элементов из хэш-таблицы, реализовать алгоритм, позволяющий искать элементы, вызвавшие коллизию с удаленным;
· реализовать алгоритм, обрабатывающий ситуации с переполнением хэш-таблицы.
В одно занятие мы явно не уложимся, подумала я :))) Длительность одного занятия для взрослых учеников, в основном, 1,5 часа, как раз чтобы хватило времени разобрать 1-2 средней сложности задачки, или пройтись по новой теме с примерами. Здесь же объем заданного тянет урока на 2-3, т.к. ученик хоть и сообразительный, но очень невнимательный, да и мы с ним только начали заниматься, и ему явно не хватает твердой базы по основам программирования.
Итак, перед написанием программы от нас требуется провести анализ выбранной хэш-функции по методичке:
Порядок анализа хэш-функции
Ключ представляет собой строку, содержащую буквы и цифры в определенных позициях (‘ц’ – цифра, ‘Б’ – заглавная буква).
Оценим область значений, получаемых от хеш-функции. Эта область должна совпадать с количеством сегментов хеш-таблицы.
· Минимальное значение хеш-функция принимает, когда строка-ключ содержит символы с минимальным кодом. Это будет символ «0» с кодом 48 и символ «A» с кодом 65. Тогда минимальное значение полученной хеш-функции будет 373, и начальные сегменты хеш-таблицы никогда не будут использованы. Следовательно, необходимо привести хеш-функцию к виду, когда ее минимальное значение давало бы минимальный номер сегмента таблицы, равный 0, то есть вычесть из нее число 373.
· Теперь проверим максимальное значение хеш-функции, которое она принимает при максимальных кодах символов строки-ключа. Это будет символ «9» с кодом 57 и символ «Z» с кодом 90. Тогда максимальное значение (с учетом вычитания 373) будет 134, и конечные сегменты хеш-таблицы никогда не будут использованы. Следовательно, необходимо привести хеш-функцию к виду, когда ее максимальное значение давало бы максимальный номер сегмента таблицы, равный 1500, то есть умножить ее на число 11. Теперь хеш-функция принимает значения в диапазоне от 0 до 1474, что практически соответствует допустимым номерам сегментов хеш-таблицы.
Экспериментальное исследование качества полученной хеш-функции проводится следующим образом:
1) формируются случайным образом ключи заданного формата в
количестве, превышающем количество сегментов хеш-таблицы в
2-3 раза;
2) для каждого сформированного ключа вычисляется хеш-функция, и
подсчитывается, сколько раз вычислялся адрес того или иного
сегмента хеш-таблицы.
После получения экспериментальных данных осуществляем их анализ и делаем экспертные оценки равномерности распределения коллизий по сегментам хеш-таблицы. При равномерном распределении коллизий считаем, что сформированная хеш-функция является удачной и можно программно реализовывать хеш-таблицу на ее основе. В противном случае хеш-функция считается неудачной, необходима ее доработка и проведение повторного исследования. Все перечисленное следует повторять до тех пор, пока не будет получена удачная хеш-функция.
Разбору и реализации этого анализа и отведем одно занятие.
Ну что, «поехали»? :)
Первым делом объявляем пользовательский тип данных на основе struct -для хранения информации про один ключ:
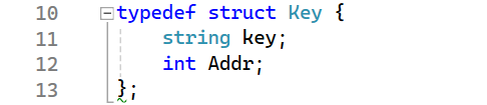
Объявляем маску ключа (‘ц’ – цифра, ‘Б’ – заглавная буква):
Принимаем количество сегментов будущей хэш-таблицы равным NumOfSegments. Структурой для хранения информации о ключах я бы выбрала vector, но, увы, по правилам лабораторной работы, использовать STL-кие контейнеры запрещено. Поэтому используем std::array с максимально возможным по заданию количеством сегментов хэш-таблицы:
Теперь объявим несколько хэш-функций. Наш выбор пал на аддитивный метод, аддитивный метод с модификацией и прямой полиномиальный хэш.
Аддитивный метод
Модифицированный аддитивный метод: суммируем только первый и последний символы строки-ключа:
Прямой полиномиальный хэш:
Чтобы подготовить случайный набор ключей для проведения исследования, быстренько напишем функцию генерации ключа на основе заданной маски:
И функцию расчета адресов хэш-таблицы на основе приведенной хэш-функции:
, где CalcCoefficients() – функция для расчета коэффициентов для приведения выбранной хэш-функции согласно описанию в методичке.
Теперь мы готовы посчитать, какое максимальное количество коллизий возникает при генерации набора ключей при использовании каждой из наших хэш-функций. Результатом работы функции анализа является массив, который содержит столько элементов, сколько сегментов в хеш-таблице. Каждая строка содержит число, показывающее, сколько раз вычислялся адрес соответствующего сегмента.
Для упрощения оценки равномерности распределения коллизий по сегментам хеш-таблицы визуализируем полученные данные с помощью диаграмм. Мы сделаем это с использованием MS Excel, импортировав в него текстовые файлы:.
Ниже представлены диаграммы каждой из трех хэш-функций:
У прямого полиномиального хэша коллизии распределены более равномерно по сравнению с двумя другими функциями и, следовательно, ее мы и будем считать приемлемой.
Возможно наши читатели посоветуют более подходящую хэш-функцию для данного формата ключа? С интересом почитаю Ваши комментарии и опробую советы в деле!
Теперь можно приступать к реализации хеш-таблицы и программы, которая выполняет требуемые действия с этой хеш-таблицей с учетом заданного в лабораторной метода разрешения коллизий.
Продолжение следует.
Если у Вас появились вопросы на эту тему и не только - Вы всегда можете задать их мне в комментариях или в группе в ВК.