В этой статье расскажу, как извлекать вредоносные файлы из сетевых захватов, т.е. как создать свой антивирус.
Сетевые захваты являются обычным явлением среди событий безопасности. Вредоносное ПО, присутствующее в любой сети, можно легко извлечь с помощью таких инструментов, как Wireshark. Если у вас много файлов PCAP, как бы их все извлечь? Давайте рассмотрим сценарий для извлечения PE-файлов из pcaps с использованием Python и Scapy.
Scapy — это довольно мощная библиотека Python. Менее чем за 200 строк мы можем написать простой парсер для извлечения PE-файлов из HTTP-запросов. Удобно иметь возможность создавать собственные инструменты или иметь один достаточно универсальный, который можно настроить в зависимости от ваших потребностей.
Как это работает?
Передавая один файл или каталог с сетевыми захватами, сценарий прочитает и проанализирует их, чтобы извлечь найденные PE-файлы.
Вывод будет отличаться в зависимости от файла. Я получил несколько примеров пакетов из анализа трафика вредоносных программ и начал их перебирать.
Код не окончательный, но работает. Надеемся, что другим людям будет полезно расширить его, адаптировать и использовать для обучения.
Код программы тут (в дзене нет нормального форматирования кода)
Весь код поместил в main.py. Список всех нужных библиотек в requirements.txt. Для ознакомления этого будет более, чем достаточно.
Самая важная функция в этом коде — extract_http_objects() это:
- Открыть файл PCAP
- Загружайте сеансы и перебирайте их, фильтруя HTTP для извлечения файлов.
- Записать все файлы в выходной каталог
Открытие и загрузка файла PCAP с помощью Scapy?
Эта часть довольно проста и понятна. После загрузки модуля Scapy в Python нам просто нужно открыть его и прочитать его содержимое.
Ранее я исследовал несколько возможных способов. Для этой цели я полагаюсь на rdpcap().
Фильтрация HTTP-трафика
Код не будет делать ничего сложного для фильтрации трафика и просто сосредоточится на любом сообщении, где порт источника или назначения равен 80. Это будет похоже на фильтрацию в Wireshark с использованием tcp.port == 80 || tcp.dstport == 80.
Код будет перебирать все сеансы. Посмотрите на каждый пакет и проверьте, является ли уровень пакета TCP, а порт источника или назначения равен 80, и сохраните полезную нагрузку.
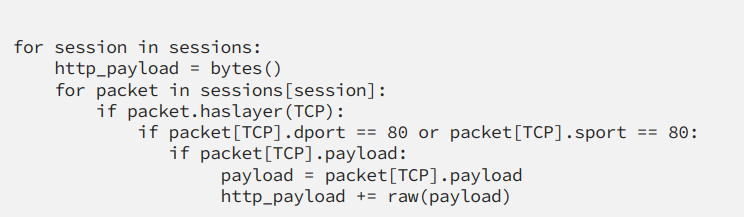
Как только вся информация будет собрана, мы сможем проанализировать полезную нагрузку и попытаться определить, есть ли какие-либо признаки того, что она содержит файл.
Читайте также: Лучшие хакерские инструменты на Python (от взлома сетей до взлома людей)
Анализ HTTP-заголовков
Следующий шаг — анализ заголовков HTTP. В целях нет ничего особенного: просто пытаемся создать словарь для доступа к содержимому в виде пар ключ/значение и оценить, присутствует ли что-то конкретное, что мы ищем.
Есть много вещей, которые можно отфильтровать, просматривая заголовки HTTP, поэтому невозможно уловить каждую комбинацию. Хорошо, что после анализа заголовков их можно фильтровать.
Код адаптирован для нескольких случаев. Ради практической реализации и проверки возможности расширения этого подхода до более общего.
Целью было не найти их все, а найти распространенные случаи среди множества сетевых перехватов, когда вредоносное ПО загружается с удаленного сервера через HTTP.
Пока что это работает довольно хорошо.
Извлечение объектов из полезных данных HTTP
Скрипт предназначен для извлечения объектов из полезных данных HTTP. В этом случае фильтрация начнется с подтверждения наличия Content Type.
Основываясь на первоначальной выборке из примерно 40 компьютеров, содержащих вредоносное ПО (это немного, но только для начала), я решил использовать 2 фильтра.
- application/x-msdownload
- application/octect-stream
Существует множество известных вариантов типов контента, и эта страница полезна для изучения/чтения о них. Одна из идей состоит в том, чтобы выполнять различные действия на основе поля Content-Type, если оно присутствует, поскольку оно может быть хорошим индикатором других типов файлов или содержимого.
Функция extract_object() выполняет эту работу:
Мы можем записать сюда еще немного информации, чтобы после неудачного извлечения мы могли просмотреть журналы и увидеть, что мы пропустили.
Запуск сценария
Как можно расширить этот сценарий?
- Извлечь новые типы файлов
- Разобрать другие протоколы
- Рефакторинг кода
У меня есть еще несколько идей в этом коде, поскольку в настоящее время я использую его для извлечения файлов, которые позже можно будет загрузить в конвейер вредоносных файлов, чтобы получить информацию, найти хорошие примеры или файлы для более глубокого изучения.
Вы не можете провести анализ вредоносного ПО, не имея доступа к образцам вредоносного ПО, поэтому создание хорошего репозитория для них (помимо известных общедоступных) может оказаться полезным.
Улучшения производительности?
Я достаточно глубоко погрузился в выполнение этого скрипта. Стоит попробовать использовать вариант PcapReader(), который потребляет меньше память. Целью было бы снизить потребление ресурсов для одновременного анализа нескольких файлов pcap.
Автоматизация – это здорово.
Извлечение информации из сетевых захватов может быть действительно полезным. Scapy — мощная и полезная библиотека Python для этой цели. Его также можно использовать даже для прослушивания сети. Об этом расскажу в следующих статьях.
❤️ Если вам понравилась статья, ставьте лайк и подписывайтесь на мой канал "Заходи в Ай-Ти".
👍 Если у вас остались вопросы или чтобы я подробнее разобрал описанные инструменты для взлома, то пишите в комментариях. Ваше мнение очень важно для меня!
#хакинг на python #python hack #python взлом #пайтон взлом #антивирус на питоне #антивирус на пайтон #антивирус на python