
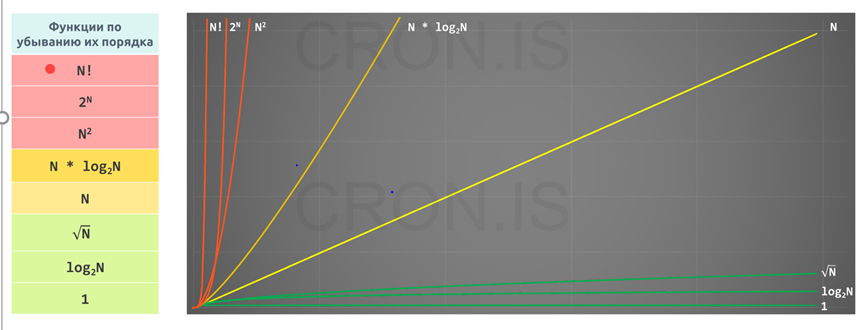
Разберёмся к какому алгоритму надо стремиться:
1) O(1) имеет наименьшую сложность. Часто называемый «постоянный по времени», если вы можете создать алгоритм для решения проблемы с O(1), то это будет лучший выбор алгоритма. Фактически, любая программа, не содержащая циклы, имеет O(1), потому что в этом случае требуется константное число инструкций (конечно, при отсутствии рекурсии.
Давайте рассмотрим программу на Python, которая складывает два значения из массива и записывает результат в новую переменную:
v = a[ 0 ] + a[ 1 ] ------------ O(1)
2)O (log(n)) является более сложным, чем O(1), но менее сложным, чем полиномы (многочлен). (log(n)) – это, как правило, хорошая сложность, которую можно достичь для алгоритмов сортировки. O (log(n)) является менее сложным, чем O (√n), потому что логарифм обратно пропорционален степени.
Теория для чаек.
«Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция f(n) = n, красный — f(n) = sqrt(n), а наименее быстро возрастающий — f(n) = log(n). Далее: подобно тому, как взятие квадратного корня является операцией, обратной возведению в квадрат, логарифм — обратная операция возведению чего-либо в степень.
Рассмотрим уравнение 2x = 1024
Чтобы найти из него x, спросим себя: в какую степень надо возвести 2, чтобы получить 1024? Ответ: в десятую. В самом деле, 210 = 1024, что легко проверить. Логарифмы помогают нам описать данную задачу, используя новую нотацию. В данном случае, 10 является логарифмом 1024 и записывается, как log( 1024 ). Читается: «логарифм 1024». Поскольку мы использовали 2 в качестве основания, то такие логарифмы называются «по основанию 2». Основанием может быть любое число, но логарифмы по основанию 2 распространены больше, чем какие-либо другие, поскольку часто мы имеем всего две сущности: 0 и 1. Также существует тенденция разбивать объёмные задачи пополам, а половин, как известно, тоже бывает всего две.
Перейдём к практике – логарифмическая сложность: Одной из известнейших задач в информатике является поиск значения в массиве. Дано: у нас есть отсортированный массив, в котором мы хотим найти заданное значение. Одним из способов сделать это является бинарный поиск. Мы берём средний элемент из нашего массива: если он совпадает с тем, что мы искали, то задача решена. В противном случае, если заданное значение больше этого элемента, то мы знаем, что оно должно лежать в правой части массива. А если меньше — то в левой. Мы будем разбивать эти подмассивы до тех пор, пока не получим искомое.
Теперь давайте попробуем проанализировать этот алгоритм. Ещё раз, в этом случае мы имеем рекурсивный алгоритм. Давайте для простоты предположим, что массив всегда разбивается ровно пополам, игнорируя +1 и -1 части в рекурсивном вызове. Также для простоты давайте предположим, что наш массив имеет размер одной из степеней двойки. Наихудшим сценарием для данной задачи будет вариант, когда массив в принципе не содержит искомое значение. В этом случае мы начинаем с массива размером n на первом рекурсивном вызове, n / 2 на втором, n / 4 на третьем и так далее. В общем, наш массив разбивается пополам на каждом вызове до тех пор, пока мы не достигнем единицы. Давайте запишем количество элементов в массиве на каждом вызове:
0-я итерация: n
1-я итерация: n / 2
2-я итерация: n / 4
3-я итерация: n / 8
…
i-я итерация: n / 2i
…
последняя итерация: 1
Заметьте, что на i-й итерации массив имеет n / 2i элементов. Мы каждый раз разбиваем его пополам, что подразумевает деление количества элементов на два (равноценно умножению знаменателя на два). Проделав это i раз, получим n / 2i. Процесс будет продолжаться, и из каждого большого i мы будем получать меньшее количество элементов до тех пор, пока не достигнем единицы. Если мы захотим узнать, на какой итерации это произошло, нам нужно будет просто решить следующее уравнение:
1 = n / 2i
Равенство будет истинным только тогда, когда мы достигнем конечного вызова функции binarySearch(), так что узнав из него i, мы будем знать номер последней рекурсивной итерации. Умножив обе части на 2i, получим:
2i = n
Решив его, мы получим:
i = log( n )
Этот ответ говорит нам, что количество итераций, необходимых для бинарного поиска, равняется log(n),где n — размер оригинального массива.
Если немного подумать, то это имеет смысл. Например, возьмём n = 32 (массив из 32-х элементов). Сколько раз нам потребуется разделить его, чтобы получить один элемент? Считаем: 32 → 16 → 8 → 4 → 2 → 1 — итого 5 раз, что является логарифмом 32. Таким образом, сложность бинарного поиска равна Θ( log( n ) ).
Последний результат позволяет нам сравнивать бинарный поиск с линейным Несомненно, log( n ) намного меньше n, из чего правомерно заключить, что первый намного быстрее второго. Так что имеет смысл хранить массивы в отсортированном виде, если мы собираемся часто искать в них значения.
Рекурсия
«Рекурсия достаточно распространённое явление, которое встречается не только в областях науки, но и в повседневной жизни. Например, эффект Дросте, треугольник Серпинского и т. д. Один из вариантов увидеть рекурсию – это навести Web-камеру на экран монитора компьютера, естественно, предварительно её включив. Таким образом, камера будет записывать изображение экрана компьютера, и выводить его же на этот экран, получится что-то вроде замкнутого цикла. В итоге мы будем наблюдать нечто похожее на тоннель.
»»Если вы ждете гостей и вдруг заметили на своем костюме пятно, не огорчайтесь. Это поправимо.
Например, пятна от растительного масла легко выводятся бензином. Пятна от бензина легко снимаются раствором щелочи.
Пятна от щелочи исчезают от уксусной эссенции. Следы от уксусной эссенции надо потереть подсолнечным маслом.
Ну, а как выводить пятна от подсолнечного масла, вы уже знаете...»»
Процедура или функция может содержать вызов других процедур или функций. В том числе процедура может вызвать саму себя. Никакого парадокса здесь нет – компьютер лишь последовательно выполняет встретившиеся ему в программе команды и, если встречается вызов процедуры, просто начинает выполнять эту процедуру. Без разницы, какая процедура дала команду это делать.
Пример рекурсивной процедуры:
Рассмотрим, что произойдет, если в основной программе поставить вызов, например, вида Rec(3). Ниже представлена блок-схема, показывающая последовательность выполнения операторов.
Процедура Rec вызывается с параметром a = 3. В ней содержится вызов процедуры Rec с параметром a = 2. Предыдущий вызов еще не завершился, поэтому можете представить себе, что создается еще одна процедура и до окончания ее работы первая свою работу не заканчивает. Процесс вызова заканчивается, когда параметр a = 0. В этот момент одновременно выполняются 4 экземпляра процедуры. Количество одновременно выполняемых процедур называют глубиной рекурсии.
Четвертая вызванная процедура (Rec(0)) напечатает число 0 и закончит свою работу. После этого управление возвращается к процедуре, которая ее вызвала (Rec(1)) и печатается число 1. И так далее пока не завершатся все процедуры. Результатом исходного вызова будет печать четырех чисел: 0, 1, 2, 3.»»