Искусственный интеллект (ИИ) стал переломным моментом во многих отраслях, и служба поддержки клиентов не является исключением. В этой статье мы рассмотрим влияние искусственного интеллекта на качественное обслуживание клиентов, подкрепив его последними статистическими данными и тенденциями. Покажем как создать и адаптировать базу данных для взаимодействия с LLM. Что такое RAG и как без проблем создать и настроить нейропомощника на базе ИИ. Читайте наш перевод с официального сайта Fluid AI.
Перезагрузка службы поддержки клиентов: Как генеративный ИИ влияет на сервис и лояльность
После пандемии обслуживание клиентов превратилось в катание на американских горках. Ожидания клиентов высоки как никогда — 72% потребителей утверждают, что останутся лояльными к компаниям, предоставляющим более быстрое обслуживание и обратную связь. А 78% агентов службы поддержки утверждают, что трудно найти баланс между скоростью и качеством, по сравнению с 63% с 2020 года. Все эти факторы привели к тому, что текучесть кадров в сервисных организациях достигла 19%. Рынок разговорного ИИ, который в настоящее время оценивается в 10,7 миллиарда долларов, переживает значительный рост. По прогнозам, рынок разговорного ИИ вырастет в три раза.
Статистика генеративного ИИ с графиками и пояснениями
Как люди относятся к генеративному ИИ
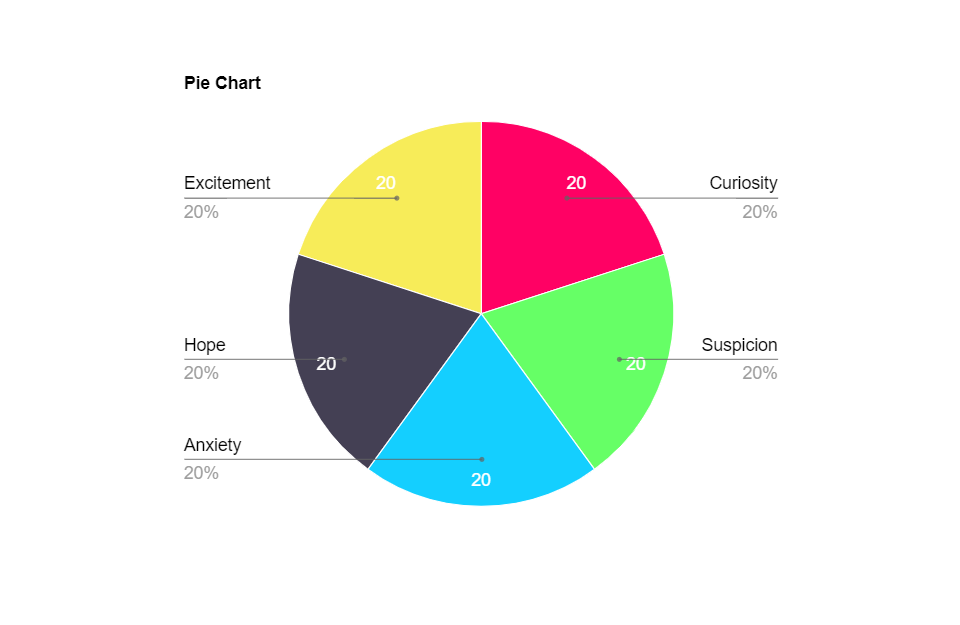
Этот круговой график представляет собой распределение пяти различных эмоциональных реакций, связанных с восприятием новой технологии — генеративного ИИ. Каждый сектор равен 20%. Это говорит о том, что реакции были распределены равномерно среди опрошенных участников.
- Восхищение (Excitement)
- Интерес (Curiosity)
- Подозрение (Suspicion)
- Надежда (Hope)
- Тревога (Anxiety)
График отображает реакцию аудитории на внедрение генеративного ИИ. Равномерное распределение указывает на то, что среди потенциальных пользователей нет явного доминирующего восприятия, что может свидетельствовать о сбалансированном взгляде на технологию — смешение оптимизма и предосторожности.
ИИ и обслуживание клиентов идут рука об руку

С одной стороны, 61% клиентов отдают предпочтение самообслуживанию при решении простых вопросов. Это подчеркивает важность наличия интуитивно понятного интерфейса самообслуживания, который может включать часто задаваемые вопросы, базу знаний или автоматизированные системы обслуживания, например чат-боты на основе генеративного ИИ, способные обрабатывать стандартные запросы.
С другой стороны, 65% клиентов ожидают немедленного ответа при обращении в компанию, что подчеркивает необходимость быстрого и эффективного реагирования на запросы клиентов. Генеративный ИИ может играть здесь ключевую роль, обеспечивая быстрый первичный ответ и поддержание диалога до тех пор, пока не потребуется вмешательство человека. Таким образом, интеграция генеративного ИИ в службу поддержки клиентов может помочь удовлетворить обе потребности: предоставить возможность самообслуживания для простых задач и гарантировать быструю реакцию на запросы, что является критически важным для удержания клиентов и улучшения их общего опыта.
Доверие: Определяющий фактор
На представленной диаграмме показано, насколько потребители доверяют компаниям в этическом использовании генеративного искусственного интеллекта (ИИ). Согласно диаграмме:
- 45% в основном доверяют компаниям на этот счет.
- 33% в основном не доверяют компаниям в вопросах этического использования ИИ.
- 10% полностью не доверяют компаниям в этом аспекте.
Эти данные могут быть использованы в контексте внедрения генеративного ИИ в службу поддержки клиентов для обоснования необходимости прозрачности и этических стандартов в использовании ИИ. Учитывая, что большинство клиентов хотя бы в какой-то мере доверяют компаниям, можно аргументировать, что существует основа для укрепления этого доверия путем демонстрации этического подхода в работе с ИИ. Это включает в себя объяснение клиентам, как ИИ используется для улучшения обслуживания, как обеспечивается защита их данных и какие меры принимаются для предотвращения предвзятости и ошибок в работе ИИ.
ИИ для поддержки клиентов: Статистика и выводы
Разговорный ИИ — наиболее распространенный тип приложения ИИ в современном бизнесе — является подтверждением влияния ИИ на обслуживание клиентов. Вот некоторые ключевые статистические данные:
- ИИ в сфере обслуживания клиентов активно используется 63% организаций розничной торговли для улучшения взаимодействия с клиентами.
Влияние ИИ на обслуживание клиентов
ИИ способен произвести революцию в обслуживании клиентов несколькими способами:
- Самообслуживание: Значительный процент клиентов предпочитает использовать возможности самообслуживания, прежде чем обратиться к представителю службы поддержки.
- Экономия средств: Чат-боты на базе ИИ позволяют компаниям ежегодно экономить значительное количество работы для представителей службы поддержки клиентов.
- Удовлетворенность клиентов: Бренды, которые отвечают на запросы службы поддержки клиентов через социальные сети, вызывают у значительной части клиентов более благоприятное мнение.
Будущее ИИ в сфере обслуживания клиентов
По прогнозам, к 2025 году ИИ будет определять 95% клиентского опыта. Это говорит о будущем, в котором взаимодействие с клиентами будет быстрым, точным и обогащенным персонализированным опытом.
Оптимизация поддержки клиентов с помощью ИИ
Преобразуйте службу поддержки клиентов вашей организации, обеспечив мгновенную и бесперебойную поддержку ваших сотрудников с помощью технологий ИИ
Компания Fluid AI создала революционные кросс-функциональные генеративные ИИ — GPT Copilots для комплексной поддержки в различных организационных сферах, включая кодирование, HR, юридическую, IT и другие. Давайте рассмотрим основную проблему клиентской поддержки и ее решение. И отдельным подразделом узнаем как подготовить свою базу знаний для внедрения ИИ в чатбот поддержки клиентов.
Проблема — задержки в клиентской поддержке
60% сотрудников тратят свое время на поиск нужных ответов и источников, что приводит к увеличению времени ожидания клиентов, в конечном итоге увеличивая задержки в обслуживании клиентов и конверсии
Современные технологически подкованные и цифровые пользователи возлагают большие надежды на быстрые ответы и оперативную помощь, в противном случае потенциальные клиенты могут разочароваться и искать альтернативные возможности, если они не будут удовлетворены.
На этом динамичном рынке специалисты сталкиваются с трудностями в получении актуальной информации, что сказывается на эффективности их работы по оказанию поддержки.
40% времени сотрудников тратится на выполнение повседневных рутинных задач, таких как решение одной и той же проблемы 100 других клиентов, что скучно, но необходимо для каждой организации, что делает команду менее продуктивной, снижает ее способность к многозадачности и максимальной производительности.
В связи с этим возник ключевой вопрос:
Как сотрудники могут работать более эффективно, выполняя существующие рабочие процессы, достигая поставленных целей и преобразуя опыт сотрудников, сокращая при этом ручные операции в масштабах всей организации?
Решение — использовать ИИ для клиентской поддержки
Создать и разработать решение на основе возможностей искусственного интеллекта и развивающейся технологии генеративного искусственного интеллекта, предоставляя клиентам нужную информацию в нужное время, чтобы они могли вовремя получить поддержку.
Благодаря быстрому доступу агентов службы поддержки к необходимой информации повышается способность принимать решения, что приводит к увеличению конверсии.
Просто общайтесь с GPT чат-ботом, который всегда готов помочь невасимо от времени. Просто наберите нужную информацию в чатбот или воспользуйтесь голосовой помощью, без необходимости обращения вашему к грубому коллеге…
Как реализовать поддержку клиентов по своей базе знаний
Переходим к большому разделу с умными терминами, но это необходимо для понимания — как реализовать настройку чатбота поддержки на корпоративных данных компании, на своей базе знаний. Итак, о чем будет следующий раздел?
Следующий раздел посвящен глубокому погружению в процесс настройки корпоративного чатбота для поддержки клиентов, используя собственную базу знаний компании. Мы рассмотрим ключевые шаги, необходимые для интеграции чатбота с корпоративными данными, обеспечивая при этом высокий уровень точности, безопасности и персонализации. Особое внимание будет уделено использованию передовых технологий, таких как генеративные языковые модели (LLM) и RAG, для обеспечения того, чтобы чатбот не только эффективно отвечал на запросы пользователей, но и обладал способностью к непрерывному обучению и адаптации на основе уникального набора данных компании.
RAG: LLM в режиме реального времени по своей базе
RAG — технология, объединяющая возможности LLM с источниками знаний в режиме реального времени. Читайте дальше, чтобы понять как все настроить
Традиционные подходы к работе с LLM опираются на предварительно обученные модели и общедоступные наборы данных, с ограниченными возможностями для настройки под целевые потребности. RAG — это технология, позволяющая расширить возможности LLM и отдавать ответы по заданным источникам знаний. Особенно это актуально в сфере поддержки клиентов, где требуются точные знания, и тем более, — знания динамичные.
Что такое RAG?
RAG (Retrieval-augmentedgeneration) — это метод повышения точности и надежности больших языковых моделей (LLM). Она позволяет LLM «консультироваться» с внешней базой знаний на предмет релевантной информации перед генерацией ответа. Он использует ретривер для выбора релевантных документов из большого корпуса и генератор для создания текста на основе найденных документов и входного запроса.
Подумайте об этом как о предоставлении LLM личной библиотеки для проверки фактов и деталей перед тем, как говорить. Это помогает LLM генерировать более точные и надежные результаты, основывая их на фактической информации.
Что такое LLM?
LLM (Large Language Models) — это мощные алгоритмы искусственного интеллекта, способные обрабатывать и генерировать естественный язык. Они обучены на огромных наборах текстовых данных и способны выполнять разнообразные задачи, такие как переводы, создание контента, суммаризация текстов и ответы на вопросы. LLM могут понимать контекст и нюансы языка, что делает их особенно полезными для создания убедительного и естественного текста.
Сравнимо с тем, как эрудированный человек может обсуждать широкий спектр тем, LLM используют свои обширные знания для формирования ответов, которые кажутся написанными человеком.
Как работает RAG и LLM по базе знаний?
- Сбор данных: База знаний RAG питается разнообразной информацией. Это могут быть как текстовые данные, такие как новостные статьи, исследовательские работы и отзывы клиентов, так и структурированные данные, такие как базы данных и графы знаний.
- Ввод: Вы задаете любой вопрос или даете подсказку системе на базе RAG.
- Поиск информации: Когда RAG получает запрос, база знаний начинает действовать. Она извлекает релевантную информацию из своего обширного хранилища, учитывая ключевые слова, контекст и намерения пользователя.
- Проверка фактов и верификация: Чтобы обеспечить точность, база знаний сверяет извлеченную информацию с внешними источниками, такими как базы данных фактов и надежные веб-сайты. Это помогает бороться с дезинформацией и предвзятостью.
- Генерация подсказок: На основе полученной информации база знаний генерирует подсказки, которыми руководствуется LLM (большая языковая модель) в RAG. Эти подсказки обеспечивают контекст и направление для творческого процесса LLM.
Примеры применения RAG + LLM
- Системы ответов на вопросы: Генерируют более точные и информативные ответы на ваши вопросы.
- Обобщение: С его помощью можно легко создавать обобщенные версии больших документов и отчетов.
- Помощники креативного письма: Помогают LLM генерировать более реалистичный и основанный на фактах контент, а также добавляют творческий потенциал для создания различных частей контента.
Как LLM понимает запрос пользователя и готовит ответ
На данной блок-схеме представлен чатбот поддержки, реализованный на основе технологий RAG (Retrieval-Augmented Generation) и LLM (Large Language Models). Вот как работает эта система:
- Пользовательский запрос: Все начинается с запроса пользователя. Пользователь задает вопрос или вводит запрос, который попадает в чатбот.
- Преобразование запроса в векторное пространство (Embedding): Введенный запрос пользователя преобразуется в векторное представление, называемое embedding. Это позволяет системе понимать смысл запроса в математической форме и находить соответствующую информацию.
- Поиск в базе знаний: После получения векторного представления запроса система ищет похожие векторные представления в организационной базе знаний, которая была предварительно преобразована в векторное пространство.
- Извлечение похожих фрагментов: Как только найдены похожие векторы, система извлекает соответствующие документы или фрагменты текста из базы знаний.
- LLM (Large Language Models): Извлеченные данные передаются в LLM, которая генерирует окончательный ответ, используя информацию как из пользовательского запроса, так и из извлеченных документов.
- Чатбот отправляет ответ пользователю: Пользователь получает ответ от чатбота, который должен быть точным и релевантным, так как он основан на актуальной информации из базы знаний и генеративной способности LLM.
Чатбот поддержки клиентов использует RAG для повышения качества и релевантности ответов генеративного ИИ, сочетая мощь LLM с точной информацией из корпоративных баз данных, а также знаний в реальном времени. Это позволяет обеспечить более интеллектуальное и адаптивное обслуживание клиентов.
Еще пара терминов… и оно стоит того!
В следующем разделе мы разберемся, в чем разница между Generative Pre-training Transformer (GPT) и Retrieval-Augmented Generation (RAG). Обе технологии являются передовыми инструментами в сфере обработки естественного языка (NLP), но работают они по-разному. Итак сравним их ключевые отличия и выясним, почему для службы технической поддержки больше подходит RAG.
GPT vs RAG — что выбрать для обработки NLP
Generative Pre-training Transformer (GPT) и Retrieval-Augmented Generation (RAG) — мощные инструменты в области обработки естественного языка NLP (Natural Language Processing)
GPT и LLM в чем разница?
Generative Pre-training Transformer (GPT) и Large Language Models (LLM) на первый взгляд кажутся похожими, поскольку оба являются моделями искусственного интеллекта, предназначенными для работы с текстом. Однако GPT — это конкретный тип LLM, разработанный с использованием архитектуры трансформера, который специализируется на генерации текста. Это означает, что GPT не просто понимает или интерпретирует запросы, но и может создавать совершенно новый, связный и смысловой контент.
С другой стороны, LLM — это более общий термин, который охватывает любые большие модели, обученные на интерпретации и генерации языка, включая, но не ограничиваясь, GPT. LLM могут выполнять широкий спектр языковых задач, включая перевод, ответы на вопросы и даже создание программного кода. В то время как GPT может рассматриваться как одна из самых известных реализаций LLM, LLM включает в себя и другие модели, каждая со своими уникальными способностями и предназначением.
Ключевые отличия GPT и RAG
Разберем подробно в чем отличие и что выбрать для службы поддержки клиентов — Generative Pre-training Transformer (GPT) или Retrieval-Augmented Generation (RAG)
Generative Pre-training Transformer (GPT) можно перевести как «Генеративный предварительно обученный трансформер», что отражает его способность генерировать текст на основе обучения большим объемам данных. Этот ИИ особенно хорош в создании содержательных и когерентных текстов, что делает его полезным для автоматизации относительно простых вопросов клиентской поддержки или генерации контента на основе примеров, уже известных системе конкретной LLM.
Retrieval-Augmented Generation (RAG), в свою очередь, переводится как «Генерация с дополнением поисковыми данными». Это подход, при котором ИИ сочетает способности генеративной модели, наподобие GPT, с возможностью поиска и использования специфической информации из внешних источников в реальном времени. RAG идеально подходит для ситуаций, когда ответы требуют актуальных данных или специализированных знаний, которых нет в исходной обучающей базе GPT.
На чем сфокусированы GPT и RAG
GPT фокусируется на внутреннем моделировании языка. Он изучает статистические взаимосвязи между словами и фразами в огромном наборе данных текста и кода. Это позволяет ему генерировать креативные текстовые форматы, такие как стихи, код, сценарии, музыкальные произведения и многое другое.
RAG фокусируется на интеграции внешних знаний. Он использует предварительно обученную языковую модель (например, GPT), но также обращается к внешним источникам знаний, таким как документы или базы данных. Это позволяет ему давать более фактические и обоснованные ответы, основанные на реальной информации.
Какая архитектура у GPT и RAG
GPT обычно имеет одноступенчатую архитектуру. Входной запрос поступает непосредственно в модель, и она генерирует выходной сигнал, основываясь на своих внутренних знаниях о языковых шаблонах.
RAG имеет двухступенчатую архитектуру. На первом этапе модель извлекает релевантную информацию из внешнего источника знаний на основе входного запроса. На втором этапе он использует полученную информацию вместе с исходной подсказкой для создания ответа.
Сильные стороны GPT и RAG
GPT отлично справляется с творческими задачами, такими как генерация различных форматов текста, перевод языков и написание различных видов творческого контента. Его также можно использовать для ответов на вопросы, но его точность может быть ограничена информацией, содержащейся в обучающих данных.
RAG отлично справляется с предоставлением фактологически точных и контекстуально релевантных ответов наряду с творческими задачами. Это особенно полезно для таких задач, как ответы на вопросы, где очень важен надежный поиск информации.
Слабые стороны GPT и RAG
GPT может быть склонен к созданию ответов, которые фактологически некорректны или вводящи в заблуждение (так называемые «галлюцинации»), особенно при работе с открытыми вопросами или темами, выходящими за рамки данных, на которых он был обучен. Эта модель не использует внешние источники информации для проверки фактов, поэтому качество и точность ответов целиком зависят от обучающего датасета.
Представьте себе GPT как талантливого рассказчика, который создает истории, опираясь исключительно на уже имеющиеся знания и воображение. Модели GPT способны придумывать увлекательные истории, но эти истории могут не всегда соответствовать действительности или фактическим данным.
RAG можно сравнить с рассказчиком, у которого есть доступ к обширной библиотеке ресурсов. Этот подход позволяет модели использовать свои генеративные способности для создания текста, одновременно обогащая его проверенной информацией из источников. RAG активно извлекает данные из внешних баз данных и настроенных источников в процессе ответа на запросы. Это делает его рассказы не только увлекательными, но и надежными: с фактами, подкрепленными актуальной информацией из заданных источников.
Как использовать RAG для дообучения LLM
Традиционные подходы к работе с LLM в основном опираются на большие, предварительно обученные модели и общедоступные наборы данных, что ограничивает их возможности тонкой настройки и персонализации. Для поддержания актуальности таких моделей требуется периодическое ручное обновление и переобучение на основе новых данных. Это может приводить к значительным затратам и трудоемким обновлениям.
В отличие от этого, LLM, интегрированные с RAG, могут обновлять свои знания в реальном времени и адаптироваться на основе новой информации, минимизируя необходимость в частых и ресурсоемких переобучениях. Методы, такие как активное обучение, трансферное обучение и метаобучение, позволяют модели постоянно корректировать свои параметры для улучшения производительности.
Система на основе RAG постоянно совершенствует свою базу знаний, обеспечивая актуальность и точность на первом месте благодаря взаимодействию с новыми данными и пользователями.
Обновление LLM на основе обратной связи от клиентов
Если компания хочет обновить свою модель LLM после длительного взаимодействия с RAG, процесс может включать в себя следующие шаги:
- Анализ Данных: Первым шагом будет анализ данных, собранных в ходе работы RAG, для выявления важных обновлений и улучшений, которые могут быть внесены в LLM.
- Подготовка Данных: Подготовка новых обучающих данных, возможно, с учетом отзывов и вопросов клиентов, на которые RAG дал наиболее точные ответы.
- Дообучение Модели: С использованием этих новых данных, модель LLM может быть дообучена. Это поможет модели лучше справляться с запросами, которые ранее вызывали затруднения, и делать ее ответы более актуальными и точными.
- Интеграция Обновленной Модели: После дообучения, обновленная модель LLM интегрируется обратно в систему для использования вместе с RAG.
- Мониторинг и Оценка: После внедрения обновленной модели важно продолжить мониторинг её работы, чтобы оценить улучшения и определить, требуются ли дополнительные корректировки.
Важно отметить, что весь процесс должен сопровождаться тщательным тестированием, чтобы гарантировать, что новые обновления улучшают работу LLM, не внося новых ошибок или предвзятостей. Обновление LLM требует знаний в области машинного обучения и понимания конкретных потребностей бизнеса.
Почему стоит выбрать RAG вместо GPT
Рассмотрим некоторые причины, по которым система Retrieval-Augmented Generation (RAG) стала критически необходимой в области обработки естественного языка (NLP) и лучше подходит для службы поддержки клиентов чем GPT:
- Решение проблем фактичности:
Большие языковые модели (LLM), такие как GPT, хотя и впечатляют своей беглостью и креативностью, часто испытывают трудности с точностью фактов. Их ответы могут быть предвзятыми, фактологически неверными или просто не иметь под собой основы в виде знаний о реальном мире. RAG преодолевает это ограничение за счет использования внешних источников данных, обеспечивая соответствие ответов реальным фактам и доказательствам. - Повышенная адаптивность и актуальность:
LLM, обученные на статичных наборах данных, со временем устаревают и не могут отразить постоянно меняющийся ландшафт знаний. RAG, интегрируя поиск информации в реальном времени, адаптируется к динамичной среде и сохраняет актуальность ответов в соответствии с текущими событиями и тенденциями. Это очень важно для реальных приложений, таких как новостные боты или диалоговые системы. - Повышение прозрачности и доверия:
Многие пользователи считают ответы LLM непрозрачными и не уверены в их надежности. RAG, благодаря атрибуции источника, обеспечивает прозрачность данных, использованных для создания ответа. Такая прозрачность способствует укреплению доверия и позволяет пользователям оценить достоверность представленной информации. - Смягчение утечки данных и предвзятости:
LLM, обученные на массивных наборах данных, могут непреднамеренно впитать в себя предубеждения и вредные стереотипы, присутствующие в обучающих данных. RAG, отбирая релевантную информацию из конкретных источников, помогает уменьшить утечку данных и предвзятость в генерируемых ответах. - Преодоление писательского блока и семантических пробелов:
RAG может помочь писателям, столкнувшимся с творческими трудностями, предлагая соответствующие факты, идеи и примеры на основе их первоначального запроса. Это может помочь устранить семантические пробелы между намерениями пользователя и пониманием LLM, что приведет к более последовательным и тематическим ответам. - Более широкая сфера применения:
Способность RAG обосновывать ответы фактическими данными открывает новые возможности для применения NLP. Его можно использовать в ответах на научные вопросы, информационно-поисковых системах, платформах персонализированного образования и многих других.
Внедрение RAG: какие шаги предпринять
RAG решает несколько общих проблем, возникающих при внедрении традиционного ИИ, таких как фактические ошибки, отсутствие контекста и релевантности, природа «черного ящика» и отсутствие адаптации к меняющимся знаниям. Однако, прежде чем внедрять RAG, организациям следует принять во внимание следующие соображения.
- Внешний источник данных: Выберите релевантный и надежный источник информации, который соответствует вашему сценарию использования. Это может быть база знаний, хранилище документов или даже поток данных в режиме реального времени.
- Интеграции: Оцените, как RAG будет интегрироваться с вашими текущими рабочими процессами, компонентами поиска, программным обеспечением, доступом к API и существующими проектами ИИ. Бесшовная интеграция минимизирует сбои и повышает эффективность.
- Лицензирование моделей: Стоимость лицензирования предварительно обученных языковых моделей может быть значительной. Изучите варианты стоимости и рассмотрите потенциальную окупаемость инвестиций.
- Тонкая настройка: Тонкая настройка выбранной модели GPT на ваших конкретных данных для повышения ее производительности и адаптации. Для этого могут использоваться такие методы, как обучение под конкретную задачу или оперативное проектирование.
- Разработка и сопровождение модели: Первоначальные инвестиции в разработку и тонкую настройку модели RAG могут быть значительными. Учитывайте текущие расходы на обслуживание и потенциальную модернизацию.
- Масштабируемость: Учитывайте предполагаемый объем и рост данных, которые будет обрабатывать ваша система RAG. Выбирайте масштабируемую инфраструктуру и инструменты, чтобы удовлетворить будущие потребности без узких мест в производительности.
- Безопасность и конфиденциальность: Применяйте надежные меры безопасности для защиты пользовательских данных и обеспечения целостности получаемой информации.
- Разработка подсказок: Создайте эффективные подсказки, которые направят LLM к нужной информации и формату ответа. Это может существенно повлиять на качество и релевантность результатов RAG.
- Объяснимость и прозрачность: Рассмотрите методы объяснения того, как RAG приходит к своим ответам. Это может укрепить доверие и позволить пользователям понять причины, лежащие в основе сгенерированного текста.
- Мониторинг и оценка: Постоянно контролируйте производительность и точность RAG. Отслеживайте такие ключевые показатели, как успешность поиска, релевантность ответов и отзывы пользователей. Используйте эту информацию для уточнения источников данных, настройки модели и общей производительности системы.
- Механизмы обратной связи: Разработайте каналы обратной связи для сбора мнений пользователей о работе RAG и постоянного совершенствования системы на основе реального опыта.
- Пилотные проекты: Начните с небольших пилотных проектов, чтобы проверить эффективность RAG и решить любые проблемы интеграции или производительности до полномасштабного развертывания.
Теперь Вы вооружены информацией и стратегиями для запуска собственного генеративного ИИ с помощью LLM и RAG. Возможно вам захочется приступить к созданию собственного Self Hosted решения. Однако, если вы ограничены в ресурсах, времени или необходимой экспертизе, на помощь приходит альтернативный путь.
Иногда наиболее разумным выбором бывает использование готовой платформы, которая может обеспечить вас всем необходимым для запуска и управления интеллектуальными приложениями ИИ. Вот тут на сцену выходит Fluid AI — инновационная платформа, которая предлагает все преимущества RAG, собранные в одном месте, чтобы помочь вам быстро и эффективно не только протестировать, но и реализовать ваши идеи.
Fluid AI: инновационная платформа на основе RAG для приложений ИИ, основанных на данных
Хранилище базы знаний Fluid AI
- Хранилище знаний: База знаний Fluid AI функционирует как обширное хранилище, всеобъемлющая библиотека, которая способна ассимилировать любую информацию вашей организации, включая частные данные и данные в режиме реального времени. Пользователи могут легко загружать свои документы, поддерживая такие форматы, как PDF, TXT, CSV, JSON, DOCX, можно просто вставить URL-адрес веб-страницы или даже ссылку на youtube. Используя эти данные для создания базы знаний, GPT Copilots способен обрабатывать и эффективно использовать такие разнообразные источники данных, а пользователи получают доступ к самой актуальной и точной информации.
- Компонент поиска и генерации: Fluid AI — это платформа на основе технологии Retrieval Augmented Generation (RAG), разработанная для расширения возможностей приложений ИИ. Этот подход объединяет три основных элемента ИИ: поиск, расширение и генерацию. Простой поиск релевантной информации, затем он объединяет данные со своими обширными предварительно обученными знаниями и пониманием, чтобы сгенерировать наиболее релевантный ответ/вывод.
- Интеграция частных данных или данных в режиме реального времени: база знаний, созданная вашей организацией на основе частной и публичной информации путем предоставления структурированных и неструктурированных данных, помогает GPT Copilot от Fluid AI быть более умным и ценным. Fluid AI дополнительно настраивает LLM на внутренних данных организации, делая их более надежными и исключительно эффективными для любой конкретной области или задачи.
- Простой в использовании интерфейс — мы упростили работу для наших клиентов, и вам не придется проходить через сложные процессы или обучение, мы уже сделали всю тяжелую работу за вас. Благодаря удобному интерфейсу, простой загрузке и обновлению источников данных, а не переобучению всей модели, RAG-pilot может оставаться в курсе последних событий и предоставлять более точные и информативные ответы на фактические запросы, получая доступ к соответствующей информации из баз знаний и других источников.
- Точность фактов: Fluid AI GPT Copilot, будучи платформой на основе RAG, позволяет избежать недостоверной информации, интегрируя частные данные организации и данные реального мира вместе со своими предварительно обученными знаниями. Просто задав любой запрос на естественном языке, Copilot извлекает из базы знаний фактически точную информацию и объединяет ее с предварительно обученными знаниями для более человекоподобного общения. Кроме того, Fluid AI включает в себя защиту от галлюцинаций и предоставляет справочные фрагменты, чтобы информировать пользователей и избежать сценариев «черного ящика».
- Безопасность данных: Fluid AI уделяет большое внимание безопасности данных. Теперь с Fluid AI вам не придется беспокоиться о конфиденциальности и сохранности данных. Вы можете выбрать один из наших безопасных вариантов частного развертывания или воспользоваться гибкими возможностями публичного или гибридного хостинга. Кроме того, различные экземпляры создаются для различных команд в организациях, обеспечивая доступ к нужным данным для нужного персонала при сохранении конфиденциальной информации.
Подведение итогов
Организации тонут в данных, а ценные сведения погребены под кучей отчетов и взаимодействий с клиентами. Традиционный искусственный интеллект с трудом справляется с этой сложной задачей, часто генерируя типовые ответы или фактологически неточный контент. Это приводит к снижению эффективности, разочарованию клиентов и упущенным возможностям.
Организации не могут просто выбрать LLM и ожидать, что он будет творить чудеса. LLM с трудом понимают нюансы организационного контекста и часто работают как черные ящики, что затрудняет понимание того, как они приходят к своим результатам. Отсутствие прозрачности может препятствовать доверию и ограничивать внедрение решений ИИ в организациях, а также может быть дорогостоящим в вычислениях и требовать специализированного опыта для обслуживания.
Именно здесь на помощь приходит Fluid AI. Мы — первая компания, которая предлагает мощь LLM в организации с дополнительными возможностями, необходимыми для предприятий, простым в использовании интерфейсом, обеспечивающим безопасность и конфиденциальность данных. Теперь организациям не нужно беспокоиться о найме новых технических специалистов/девелоперов, тратить месяцы и годы на сложное обучение и бороться за новейшие технологии.
Copilot от Fluid AI открывает возможности объясняемого ИИ (AI), проливая свет на то, как RAG приходит к своим результатам. Забудьте о месяцах настройки, обучения или сложного кодирования. Fluid AI делает RAG легкодоступным и простым в использовании даже без специальной команды специалистов по ИИ и обеспечивает постоянное обновление технологии, чтобы ваш Copilot всегда работал на передовых позициях.
Забудьте об ограничениях, примите трансформацию. Copilot на базе RAG от Fluid AI — это не просто очередная причуда, это смена парадигмы.